Distilling LLM Agent into Small Models with Retrieval and Code Tools
预备知识
(Agent) Agent 是具备规划和工具使用能力的智能体, LLM 在 reasoning 方面超强的能力赋予了广阔的天空. 然而, 多智能体间的交互行为需要大量的 LLM 推理为代价, 这让本不富裕的家庭雪上加霜.
(Distillation) 因此, 将大模型蒸馏为小模型就显得那么重要了. 一般的蒸馏:
Knowledge Distillation: 给定 source tokens $\bm{x}$ 和 target tokens $\bm{y}$, 其优化目标是:
$$ \min_{\theta} \: \mathbb{E}_{(\bm{x}, \bm{y}) \sim \mathcal{D}_{\text{train}}} \frac{1}{L_y} \sum_{n=1}^{L_{\bm{y}}} \text{KL} \left( p_T(\cdot | \bm{y}_{< n}, \bm{x}) \| p_S(\cdot | \bm{y}_{< n}, \bm{x}; \theta) \right), $$这里 $S, T$ 分别表示 student, teacher models.
Reasoning Distillation. 通过让学生模仿教师在 CoT (chain-of-thought) 下的输出逻辑来实现:
$$ \min_{\theta} \: -\mathbb{E}_{\bm{x} \sim \mathcal{D}_{\text{train}}, \bm{y} \sim p_T (\cdot | \bm{x}, \bm{I}_{\text{CoT}})} \sum_{n=1}^{L_{\bm{y}}} \log p_S (\bm{y}_n | \bm{x}, \bm{y}_{< n}; \theta). $$
核心思想

上述的两个蒸馏方法均没有涉及到 Agent 的交互过程, 因此难以保证 agent trajectories:
$$ \tau = ( (\bm{r}_1, \bm{a}_1, \bm{o}_1), \ldots, (\bm{r}_{L_{\tau}}, \bm{a}_{L_{\tau}}, \bm{o}_{L_{\tau}}) ) \sim p_T (\cdot| \bm{x}, \bm{I}_{\text{agent}}), $$的蒸馏. 这里 $\bm{I}_{\text{agent}}$ 表示 instruction prompt for the agent (如, “To solve the task, you must plan forward to proceed in a series of steps, in a cycle of Thought:, Code:, and Observation: sequences”). $\bm{r}$ 是 thought, $\bm{a}$ 是 action, $\bm{o}$ 是 observation.
本文采取类似的蒸馏方式用来蒸馏 Agent 的 trajectories:
$$ \min_{\theta} -\mathbb{E}_{\bm{x} \sim \mathcal{D}_{\text{train}}, \tau \sim \pi_{T}(\cdot | \bm{x}, \bm{I}_{\text{agent}})} \sum_{t=1}^{L_{\tau}} \log p_S(\bm{r}_t, \bm{a}_t | \bm{x}, \tau_{< t}; \theta). $$
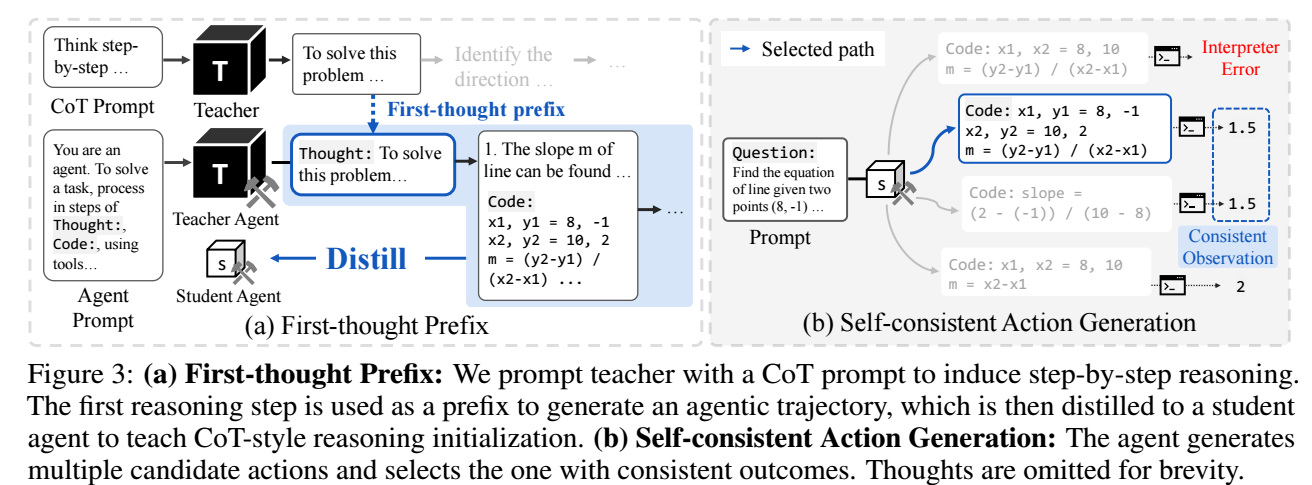
作者认为, 目前的方式首先于学生模型可能过于 fit 到 CoT-style reasoning, 以及本身能力有限, 导致交互不畅. 为此, 本文提出:
- First-thought prefix: 由于 CoT 通常要求模型先一步一步规划, 而 Agent 通常直接执行, 因此, 作者以 teacher 的 CoT prompt 的第一步行动作为 prompt, 避免学生 Agent 过度依赖 CoT 的推理方式:
- Self-consistent action generation: 由于小模型代码能力有限, 因此经常会出现无效的 actions. 因此, 作者建议在采样 actions 的时候采样多个 diverse 的 actions (而不是用 greedy decoding), 然后一一验证并取其中有效的.