Language Representations Can be What Recommenders Need: Findings and Potentials
Content
核心思想
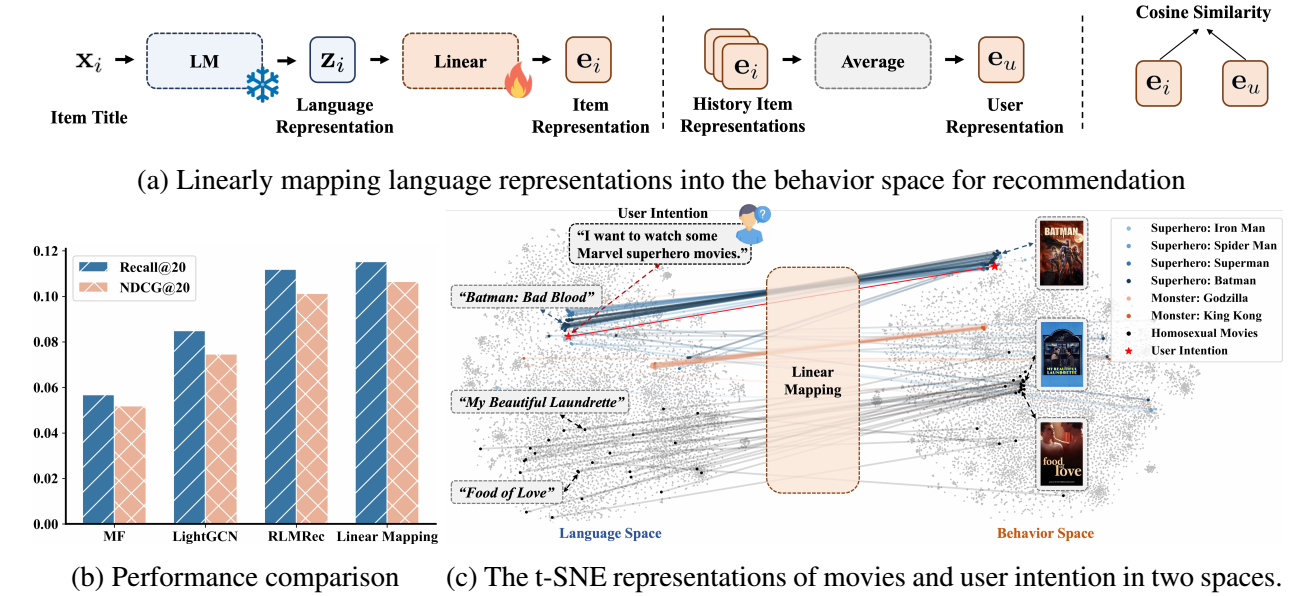
Linear
-
本文探索 LLM embeddings 的潜力, 方法极为简单:
- 将 title 的 embeddings 作为对应 item 的表示 (记为 $\bm{z}_i$), 其过程如下 (注意到, 实际上, 是将 decoder-only 的 next-token embedding 作为 item 的表示, 而不是平均之类的方式):
# model_path = "meta-llama/Meta-Llama-3-8B" model_path = "meta-llama/Llama-2-7b-hf" # model_path = "meta-llama/Llama-2-13b-hf" tokenizer = AutoTokenizer.from_pretrained(model_path, device_map = 'auto') model = AutoModelForCausalLM.from_pretrained(model_path, device_map = 'auto') tokenizer.padding_side = "left" tokenizer.pad_token = tokenizer.eos_token item_df = pd.read_csv('raw_data/items_filtered.csv', index_col=0) item_df.rename(columns={'title': 'item_name'}, inplace=True) batch_size = 64 for i in tqdm(range(0, len(item_df), batch_size)): # print(i) item_names = item_df['item_name'][i:i+batch_size] # 生成输出 inputs = tokenizer(item_names.tolist(), return_tensors="pt", padding=True, truncation=True, max_length=128).to(model.device) with torch.no_grad(): output = model(**inputs, output_hidden_states=True) seq_embeds = output.hidden_states[-1][:, -1, :].detach().cpu().numpy() # break if i == 0: item_llama_embeds = seq_embeds else: item_llama_embeds = np.concatenate((item_llama_embeds, seq_embeds), axis=0)-
然后 user 表示为其所交互过的商品的平均:
$$ \bm{z}_u = \frac{1}{|\mathcal{N}_u|} \sum_{i \in \mathcal{N}_u} \bm{z}_i. $$ -
然后通过共享的 projector 得到:
$$ \bm{e}_u = \mathbf{W} \bm{z}_u, \quad \bm{e}_i = \mathbf{W} \bm{z}_i. $$ -
score 以 cosine similarity 来计算:
$$ s_{ui} = \frac{\bm{e}_u^T \bm{e}_i}{\|\bm{e}_u\| \| \bm{e}_i\|}. $$ -
通过 InfoNCE 进行训练 (温度参数 $\tau \approx 0.15$), 注意, $\bm{z}$ 是固定的.
-
下面是 linear projector 下的结果:
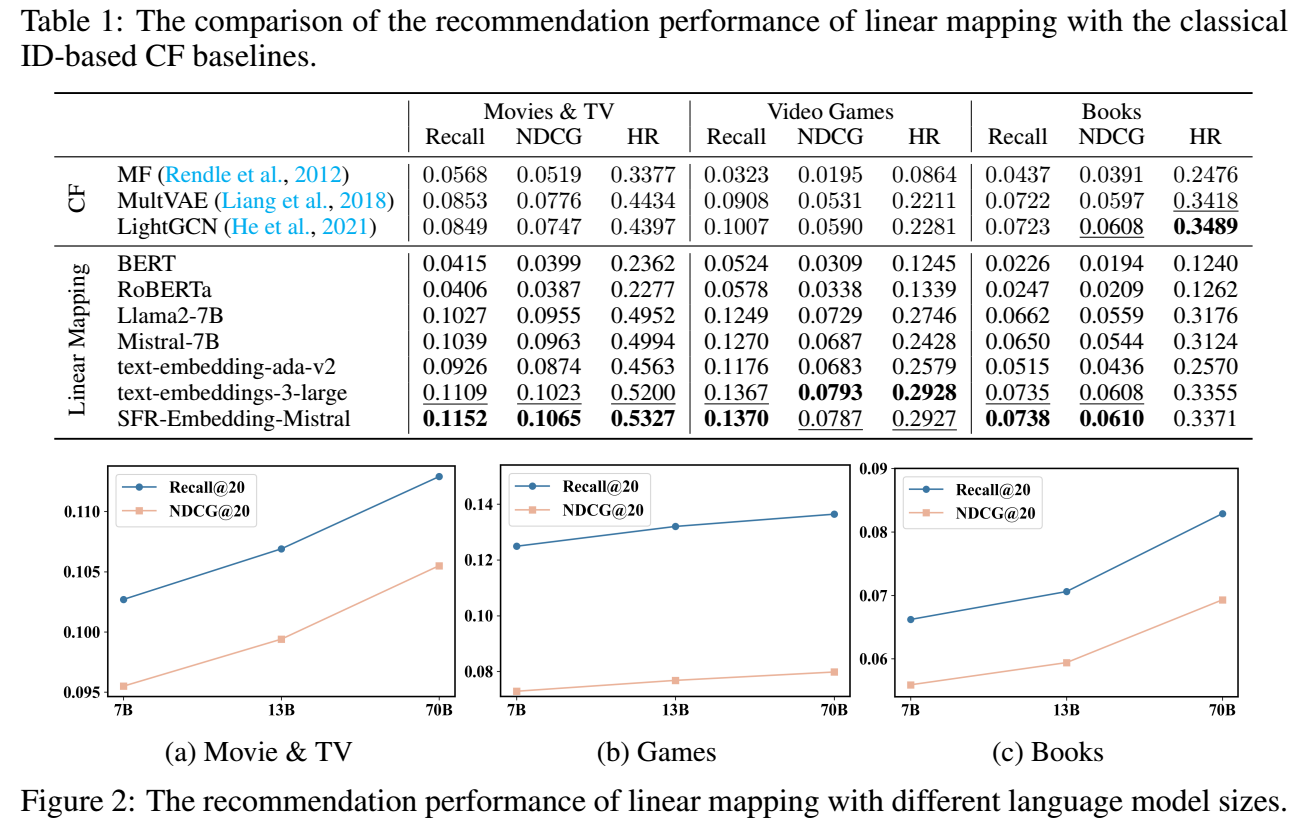
- 有一些很有趣的点:
- BERT, RoBERTa 等传统的 encoder 模型反而会取得很差的效果, 这个和之前的一些经验是相符的;
- 随着 LLM 的能力的增强, 效果也越来越好了, 很容易就能够超过 ID-based 的方法.
AlphaRec
-
AlphaRec 的做法:
- linear projector 进行了一点点修改
- 加上 LightGCN:
这里 $\mathbf{E}$ 是所有的 $\bm{e}_u, \bm{e}_i$, $\mathbf{\tilde{A}}$ 是对应的 (对称) normalized 邻接矩阵.
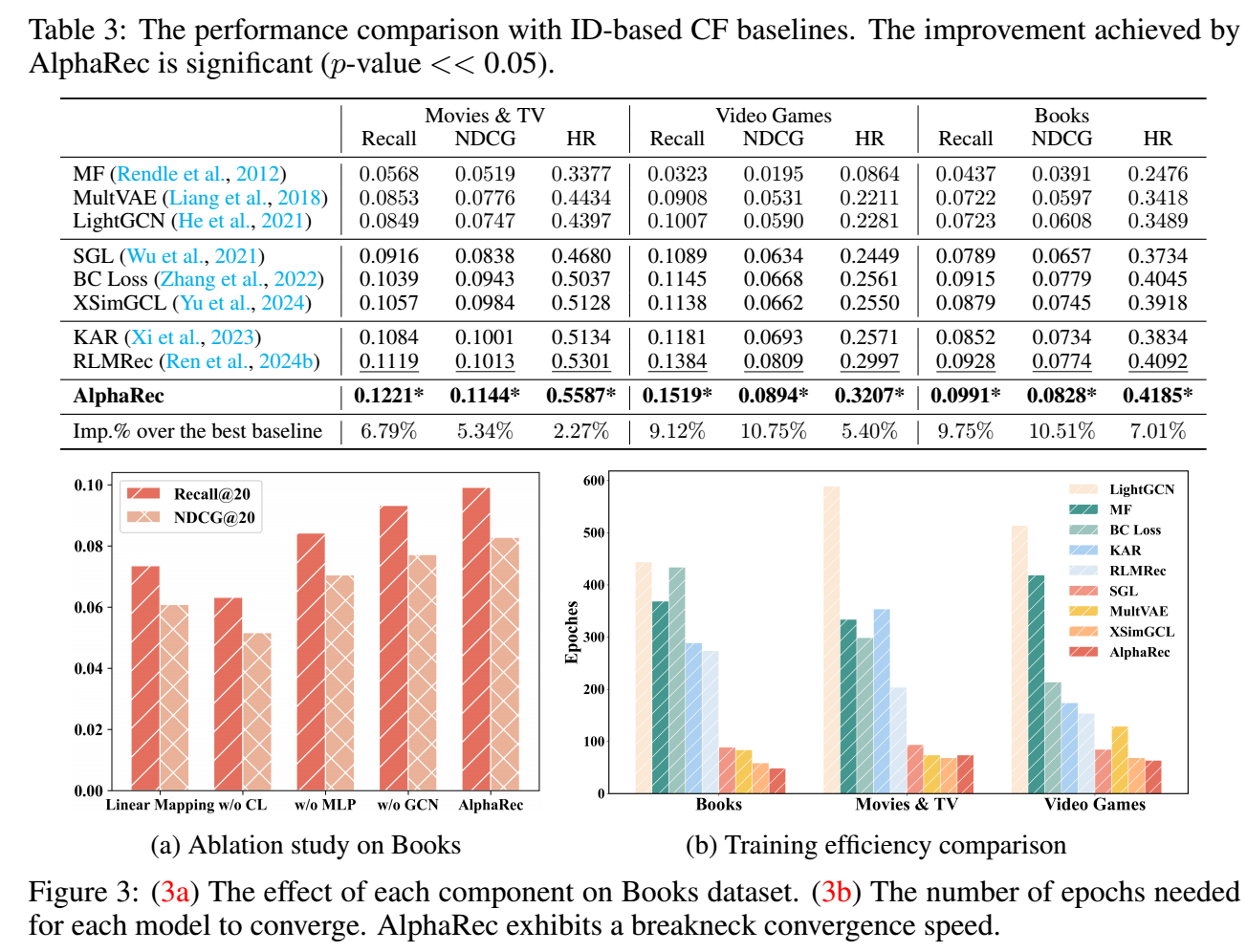
- 如上图所示, AlphaRec 如此简单的方法就能够取得非常惊人的效果 (而且效率很高).
其它潜力
-
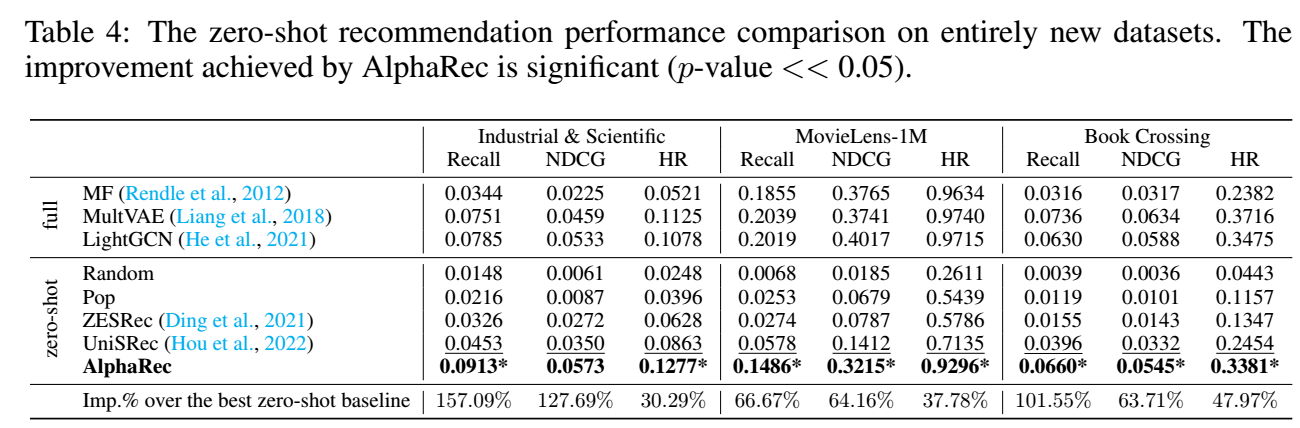
可以作为初始化而加速和提高传统模型
-
非常强的 zero-shot 能力, 甚至能够媲美传统模型 full-training 的效果
-
intention-aware, 用户可以输入自己的意图, 同样通过 LLM 得到 embedding, 加权平均得到 user 的表示:
$$ \bm{\tilde{e}}_u = (1 - \alpha) \bm{e}_u + \alpha \bm{e}_u^{Intention}. $$

个人测试
- 参考作者的代码, 自己实现了 AlphaRec, 在 Movies 进行了一下测试.
Movies
# AlphaRec
root: ../../data
dataset: AmazonMovies_Alpha
tasktag: Matching
embedding_dim: 64
num_layers: 2
epochs: 500
batch_size: 4096
optimizer: adam
lr: 5.e-4
weight_decay: 1.e-6
tau: 0.15
num_negs: 256
projector: mlp
monitors: [LOSS, Recall@1, Recall@10, Recall@20, HitRate@10, HitRate@20, NDCG@10, NDCG@20]
which4best: Recall@20
# LightGCN
root: ../../data
dataset: AmazonMovies_Alpha
tasktag: Matching
embedding_dim: 64
num_layers: 2
epochs: 1000
batch_size: 2048
optimizer: adam
lr: 1.e-3
weight_decay: 1.e-3
monitors: [LOSS, Recall@1, Recall@10, Recall@20, HitRate@10, HitRate@20, NDCG@10, NDCG@20]
which4best: NDCG@20
Beauty
# LightGCN
root: ../../data
dataset: Amazon2014Beauty_550811_ROU
tasktag: Matching
embedding_dim: 64
num_layers: 3
epochs: 1000
batch_size: 2048
optimizer: adam
lr: 1.e-3
weight_decay: 1.e-3
monitors: [LOSS, Recall@1, Recall@10, Recall@20, NDCG@10, NDCG@20]
which4best: NDCG@20
# LightGCN + InfoNCE
root: ../../data
dataset: Amazon2014Beauty_550811_ROU
tasktag: Matching
embedding_dim: 64
num_layers: 3
num_negs: 256
tau: 0.15
epochs: 500
batch_size: 2048
optimizer: adam
lr: 5.e-4
weight_decay: 1.e-2
monitors: [LOSS, Recall@1, Recall@10, Recall@20, NDCG@10, NDCG@20]
which4best: NDCG@20
root: ../../data
dataset: Amazon2014Beauty_550811_ROU
tasktag: Matching
embedding_dim: 64
num_layers: 3
tfile: llama2_7b_title.pkl # llama2_13b_title.pkl
epochs: 500
batch_size: 2048
optimizer: adam
lr: 5.e-4
weight_decay: 0.
tau: 0.15
num_negs: 256
projector: mlp
monitors: [LOSS, Recall@1, Recall@10, Recall@20, NDCG@10, NDCG@20]
which4best: NDCG@20
| Method | R@1 | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|---|
| LightGCN | 0.0079 | 0.0538 | 0.0836 | 0.0282 | 0.0361 |
| LightGCN+InfoNCE | 0.0098 | 0.0544 | 0.0829 | 0.0296 | 0.0371 |
| AlphaRec (Llama2-7B) | 0.0104 | 0.0618 | 0.0925 | 0.0330 | 0.0412 |
| AlphaRec (Llama2-13B) | 0.0107 | 0.0608 | 0.0921 | 0.0329 | 0.0412 |
| AlphaRec (MiniLM-L12-v2) | 0.0100 | 0.0608 | 0.0930 | 0.0322 | 0.0407 |
Baby
# LightGCN
root: ../../data
dataset: Amazon2014Baby_550811_RAU
tasktag: Matching
embedding_dim: 64
# num_layers: 3
# num_negs: 256
# tau: 0.25
epochs: 100
batch_size: 2048
optimizer: adam
lr: 1.e-3
weight_decay: 5.e-3
monitors: [LOSS, Recall@1, Recall@10, Recall@20, NDCG@10, NDCG@20]
which4best: NDCG@20
# LightGCN + InfoNCE
root: ../../data
dataset: Amazon2014Baby_550811_RAU
tasktag: Matching
embedding_dim: 64
num_layers: 3
num_negs: 256
tau: 0.25
epochs: 500
batch_size: 2048
optimizer: adam
lr: 1.e-3
weight_decay: 1.e-3
monitors: [LOSS, Recall@1, Recall@10, Recall@20, NDCG@10, NDCG@20]
which4best: NDCG@20
# AlphaRec
root: ../../data
dataset: Amazon2014Baby_550811_RAU
tasktag: Matching
embedding_dim: 64
num_layers: 3
tfile: llama2_7b_title.pkl
epochs: 500
batch_size: 2048
optimizer: adam
lr: 5.e-4
weight_decay: 0.
tau: 0.25
num_negs: 256
projector: mlp
monitors: [LOSS, Recall@1, Recall@10, Recall@20, NDCG@10, NDCG@20]
which4best: NDCG@20
| Method | R@1 | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|---|
| LightGCN | 0.0037 | 0.0212 | 0.0357 | 0.0113 | 0.0151 |
| LightGCN+InfoNCE | 0.0036 | 0.0206 | 0.0344 | 0.0111 | 0.0147 |
| AlphaRec (Llama2-7B) | 0.0039 | 0.0243 | 0.0399 | 0.0128 | 0.0169 |
| AlphaRec (Llama2-13B) | 0.0037 | 0.0242 | 0.0399 | 0.0126 | 0.0167 |
| AlphaRec (MiniLM-L12-v2) | 0.0031 | 0.0229 | 0.0385 | 0.0117 | 0.0158 |
-
从自己处理的数据集来看, LLM 并没有比传统的 BERT 好上太多.
-
不过 Next-token embedding 的能力还是比较令人惊讶的, 这方面的原因可能可以通过 这篇文章 解释.