BEAR: Beam-Search-Aware Optimization for LLM-based Recommendation
Content
研究背景
-
(LLM4Rec 范式) LLM-based RS 通常采用三阶段范式: 1. 将用户历史交互转化为文本 prompt; 2. 通过 SFT 微调 LLM; 3. 使用 Beam Search 解码生成推荐候选项. Beam Search 因其高效的剪枝策略而被广泛采用.
-
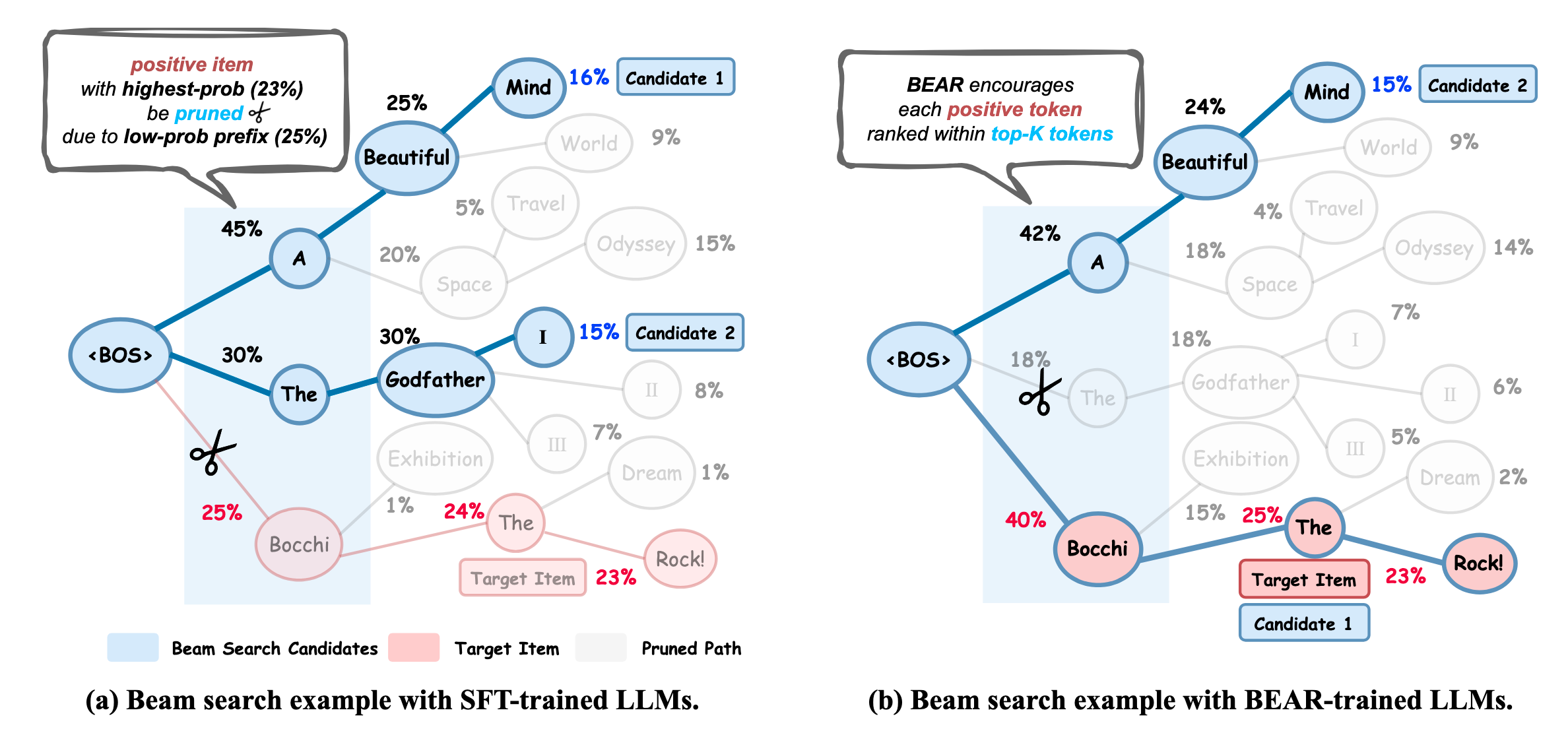
(Beam Search 的局部最优) 然而, SFT 优化的目标是最大化正样本的整体概率 $P_{\theta}(y|x)$, 而 Beam Search 在每一步只保留前缀概率最高的 $B$ 个候选. 这导致了一个关键的训练-推理不一致: 一个拥有最高整体概率的正样本, 可能因为其前缀概率不足而在 Beam Search 中被提前剪枝.
-
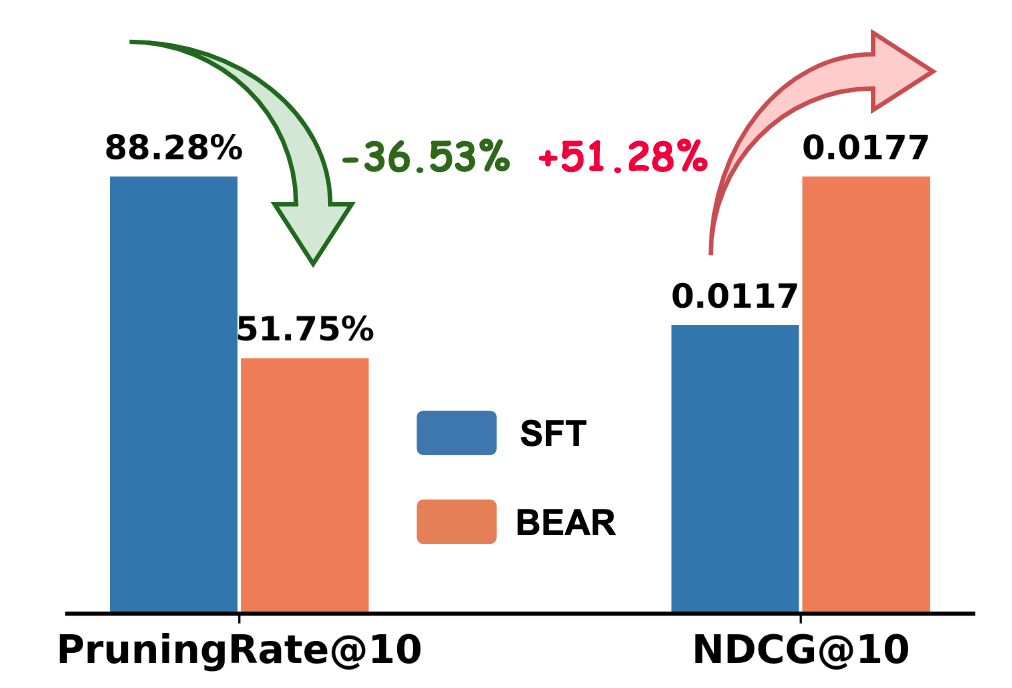
(经验发现) 实验数据显示这一现象极为普遍: 在 Book 和 Toy 数据集上, 超过 80% 的 top-$K$ 正样本在 Beam Search 中被错误剪枝. 其中, 违反必要条件 (即每个正样本 token 的概率未进入 top-$B$) 是导致错误剪枝的主要原因, 占比超过 70%.
核心思想
-
记正样本为 $y$, 其第 $t$ 个 token 为 $y_t$. SFT 的优化目标为:
$$ \mathcal{L}_{\text{SFT}}(x, y; \theta) = -\sum_{t=1}^{|y|} \log P_{\theta}(y_t | y_{ -
(朴素方案) 直接保证正样本的每个前缀 $y_{
其中 $b^B_{
-
(条件放松) 观察发现, 绝大多数的错误剪枝源于一个必要条件被违反: 正样本的每个 token $y_t$ 的概率必须进入 top-$B$:
$$ \max_{\theta} \prod_{t=1}^{|y|} \mathbb{I}\big( P_{\theta}(y_t | y_{ < t}, x) \geq \beta^B_t \big), $$其中 $\beta^B_t = \text{top-}B\{P_{\theta}(\cdot | y_{ < t}, x)\}$ 是第 $t$ 步的第 $B$ 大 token 概率. 该目标是 (3.1) 的必要条件, 但计算 $\beta^B_t$ 不需要额外的 LLM 前向传播 (因为 SFT 已计算了所有 logits).
-
(可微化) 引入 pruning margin $\Delta^B_t = \log \beta^B_t - \log P_{\theta}(y_t | y_{ < t}, x)$, 当 $\Delta^B_t > 0$ 时意味着正样本 token 将在第 $t$ 步被剪枝. 用 sigmoid 替代指示函数:
$$ \mathcal{L}_{\text{reg}}(x, y; \theta) = \sum_{t=1}^{|y|} \log \sigma_{\xi} \big( \log \beta^B_t - \log P_{\theta}(y_t | y_{ < t}, x) \big), $$其中 $\sigma_{\xi}(z) = 1/(1 + \exp(-z / \xi))$, $\xi$ 为温度参数.
-
最终 BEAR 目标:
$$ \min_{\theta} \mathcal{L}_{\text{BEAR}}(x, y; \theta) = \mathcal{L}_{\text{SFT}}(x, y; \theta) + \lambda \mathcal{L}_{\text{reg}}(x, y; \theta). $$BEAR 无需额外的前向传播, 计算开销与 SFT 相当, 同时有效降低了 Beam Search 中的错误剪枝率.
继往开来
- 虽然 BEAR 方法层面比较简单, Beam Search 的训推不一致的问题的确是客观存在, 其实 Beam Search 此类搜索策略对于推荐来说是否是最优的本身也是个值得商榷的问题.