BEiT: BERT Pre-Training of Image Transformers
预备知识
- 请务必了解 VQVAE.
核心思想
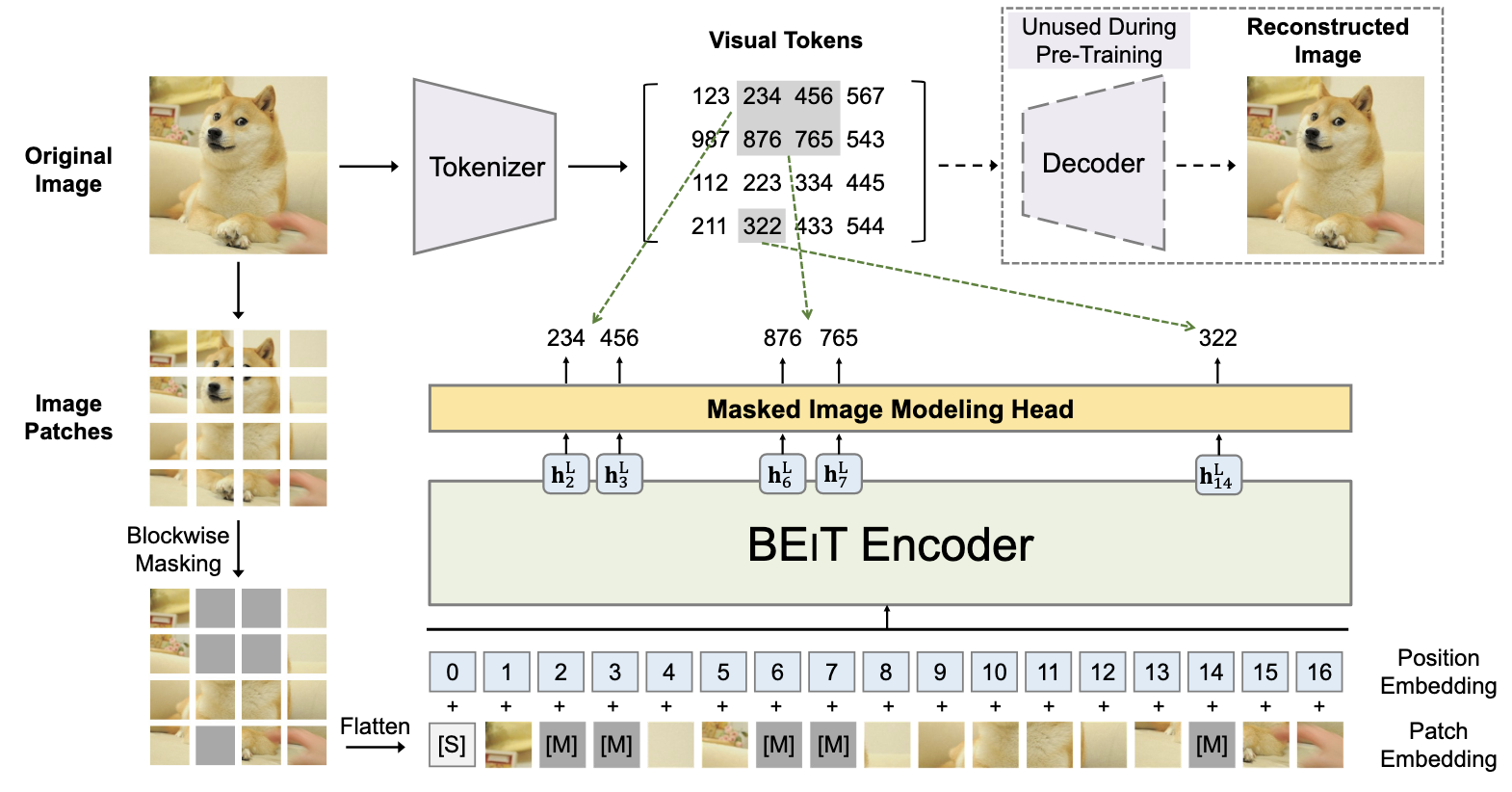
虽说 ViT 已经在如何将 Transformer 应用到图片上做了相当的工作, 但是由于图片偏 ‘连续’ 的特性, 依旧难以像 BERT 那样以 ‘Prediction’ 的方式训练.
BEiT 做了一个突破的尝试:
- Visual tokens: 除了正常的 Patch-level 的表示, BEiT 通过自编码将每个 patch 编码为一个 codeword, 换言之, 对于一个图片, 我们可以用一组 codeword 来表示了.
- Masked Image Modeling: 模仿 BERT, BEiT 采取图片恢复的任务进行训练, 其以 patch 信息为输入, 通过 BEiT Encoder 来尽可能恢复出被 mask 的 patch 所对应的 visual tokens.
- 图像恢复: 在实际任务中, 倘若我们像恢复图片, 只需要将 visual tokens 喂给 Decoder, 即可得到重构的图片.
对于 Maksed Image Modeling, 作者建议采取 block-wise 的随机掩码方式 (即一次 mask 掉图片中的多个 patch), 而不是简单的随机掩码.