Collaborative Alignment for Recommendation
预备知识
- $\mathcal{U} = \{u_1, u_2, \ldots, u_{|\mathcal{U}|}\}$, users;
- $\mathcal{I} = \{i_1, i_2, \ldots, i_{|\mathcal{I}|}\}$, items;
- $\mathbf{R} \in \{0, 1\}^{|\mathcal{U}| \times |\mathcal{I}|}$, interaction matrix;
- $\mathcal{G}(\mathcal{U}, \mathcal{I}, \mathcal{E})$, 对应的图.
核心思想
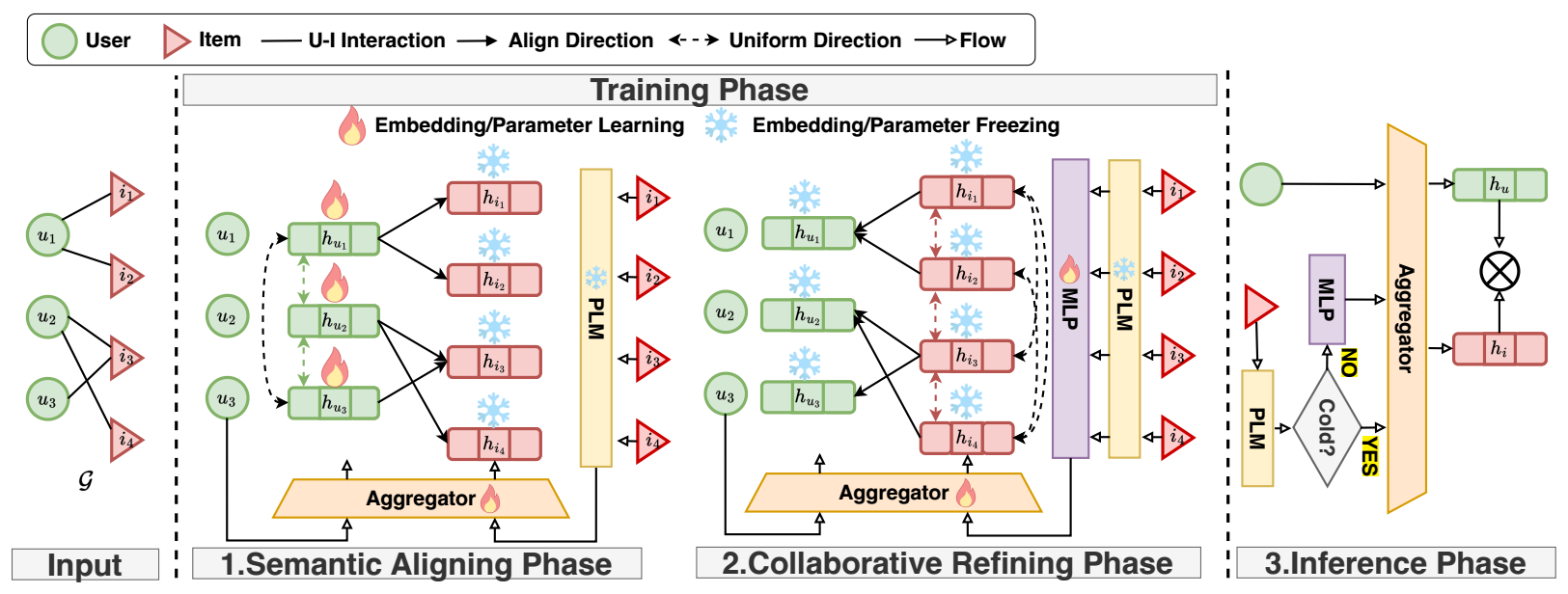
以前的方法大多为:
- 纯的 ID-based 的方法, 即 user/item 均用可训练的 embeddings 表示;
- 纯的语义表示, 即 user/item 均用文本或者其它模态信息编码得到的编码;
- 二者混合.
本文属于第三种, 特别之处在于 user embeddings 随机初始化 $\mathbf{h}_u^{(0)}$, item 的 embeddings 用语义表示 $\mathbf{h}_i^{(0)}$ (通过训练好的语言模型得到).
Semantic Aligning Phase: 这一阶段是为了训练 user embedddings, 使其和 item 的编码得到的语义特征对齐:
首先经过 LightGCN:
$$ \mathbf{h}_u, \mathbf{h}_i = \text{Aggregator} \big( \mathcal{G}(\mathcal{U}, \mathcal{I}, \mathcal{E}), \mathbf{h}_u^{(0)}, \mathbf{h}_i^{(0)} \big). $$通过类似 DirectAU 的方式对齐 $\mathbf{h}_u \rightarrow \mathbf{h}_i$:
$$ l_{align}^{\mathcal{U}} = \frac{1}{|\mathcal{E}|} \sum_{(u, i) \in \mathcal{E}} \| \mathbf{h}_u - \text{freeze}(\mathbf{h}_i) \|^2, \\ l_{uniform}^{\mathcal{U}} \log \frac{1}{|\mathcal{U}|^2} \sum_{u \in \mathcal{U}} \sum_{u^* \in \mathcal{U}} e^{-2 \| \mathbf{h}_u - \mathbf{h}_{u^*} \|}. $$
第二个损失是促进均匀分布的.
Collaborative Refining Phase: 在上一阶段训练完毕之后, 在进行一个协同微调 (作者是这么认为的) 的过程:
通过一个可训练的 MLP 得到
$$ \mathbf{\tilde{h}}_i^{(0)} = \text{MLP}(\mathbf{h}_i^{(0)}). $$后续的过程是一样的.
然后通过如下的 alignment loss 来令 $\mathbf{\tilde{h}}_i \rightarrow \mathbf{h}_u$:
$$ l_{align}^I = \frac{1}{|\mathcal{E}|} \sum_{(u, i) \in \mathcal{E}} \| \text{freeze}(\mathbf{h}_u) - \mathbf{\tilde{h}}_i \|^2, \\ l_{uniform}^{\mathcal{I}} \log \frac{1}{|\mathcal{I}|^2} \sum_{i \in \mathcal{I}} \sum_{i^* \in \mathcal{I}} e^{-2 \| \mathbf{\tilde{h}}_i - \mathbf{\tilde{h}}_{i^*}\|}. $$
注: 容易发现, 这个阶段新引入的 MLP 是不会改变 $\mathbf{\tilde{h}}_i$ 的 embedding size 的, 所以在实际中, embedding size 必须和 text encoder 的 embedding size 保持一致. 这不是一个好的设计.
- Inference 的时候, 利用内积即可, 特别的是, 作者认为冷启动场景下不需要经过 MLP, 直接用 textual embedding 就可以了.