Bridging Textual-Collaborative Gap through Semantic Codes for Sequential Recommendation
预备知识
- 需要对 TIGER 以及 Q-Former 有一定的了解.
核心思想
现在大体的对于 textual features 的方法主要有两种:
- 一种是用类似 UniSRec 的做法, 将其直接作为 item embeddings, 然后在此基础上进行一定的推理;
- 第二种是先将其转换为 semantic IDs, 然后套用生成式推荐的模式, 代表工作就是 TIGER.
前者的主要问题在于, textual features 通常是具有很多噪声的, 故而直接使用往往存在一定问题, 不能够充分利用协同信息. 另一方面, 后者虽然能够自主地学习协同信息, 但是其所套用的两阶段的训练方式可能会剔除很多宝贵的 textual features.
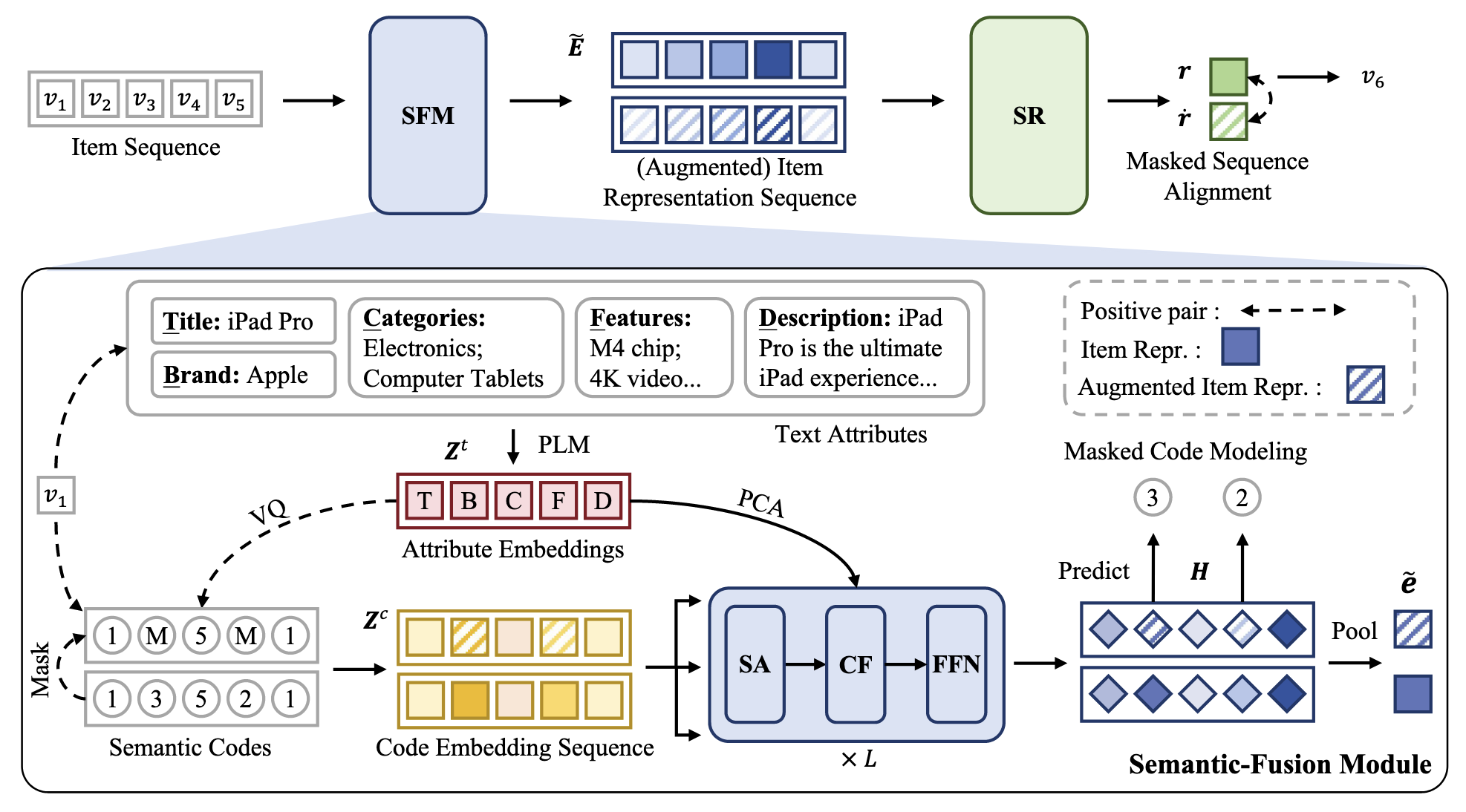
本文提出的 CCFRec 就是希望解决这个问题, 它接触 Q-Former 来沟通 semantic IDs 和 textual features, 以获得更好的 item embeddings:
(Attribute features) 首先通过一个预训练好的模型来编码 text attributes $\mathcal{A} = \{a_1, a_2, \ldots, a_m\}$:
$$ \bm{z}_i^t = \text{PLM}(a_i), \quad i=1,2,\ldots, m, $$这里, 不用 [CLS] Token 作为最终的表示, 而是利用 mean pooling 后的结果. $t$ 指代第 $t$ 个 item.
(Semantic IDs) 对于每个 attribute feature $\bm{z}_i^t$, 我们都可以通过向量量化得到一组 semantic codewords:
$$ C_i = (c_1^i, c_2^i, \ldots, c_k^i). $$因此, 对于一个 item 而言, 他共有 $m \times k$ 个 codewords:
$$ (c_1^1, c_2^1, \ldots, c_{k-1}^m, c_{k}^m). $$(Semantic-Fusion Module (SFM)) 如上图所示, 引入一个 Q-Former, 其以 semantic IDs 为 query (对应的 SID embedding 为 $[\bm{z}_1^c, \ldots, \bm{z}_{n_c}^c]$), 以 $[\bm{z}_1^t, \ldots, \bm{z}_m^t]$ 通过 PCA 降维后的向量组 (降维是为了保证维度一致) 为 Context, 所得 item embeddings 能够自适应地吸收所需的 textual 信息. 假设 $[\bm{z}_1^c, \ldots, \bm{z}_{n_c}^c]$ 经过 Q-Former 得到的 hidden vectors 为 $[\bm{h}_1, \ldots, \bm{h}_{n_c}]$, 则最终的 item embeddings 为:
$$ \bm{e} = \frac{1}{n_c} \sum_{j=1}^{n_c} (\bm{h}_j + \bm{z}_j^c). $$(Sequential Recommendation) 后面的推理部分就和普通的 Transformer-based 的序列推荐大差不差了, 只是其 embedding table 是上述得到的 embeddings 而不是单独可训练的.
除了最一般的 Next-item prediction 任务, 为了进一步增强表示学习的能力, 作者引入了两个额外的对比学习任务:
- (Masked Code Modeling) 此任务主要用于 SFM, 即通过对输入的 semantic codes 进行随机掩码操作, 构造正样本对.
- (Masked Sequence Alignment) 上述的操作同样能够生成多样的 item 表示, 并通过对比学习来增强 recommendation backbone 的学习.