Code Graph Model (CGM): A Graph-Integrated Large Language Model for Repository-Level Software Engineering Tasks
预备知识
- (AI Software Engineering) 随着大模型 (LLM) 的日益发展进步, 一般的 Function-level Coding Problem (e.g., “Write a python function to find the first repeated character in a given string”) 已经完全可以交由 LLM 完成. 然而, 工业生产中的问题要复杂的多, 至少是 Repository-level Coding Problem: 由多个文件构成. 遇到的实际问题往往是需要添加某一个功能, 或者修改某一个 Bug. 这要求 LLM 1) 定位出所需要修改的位置 (File & Lines); 2) 根据整个 Repository (相当长的 Context) 来生成合适的代码.
核心思想
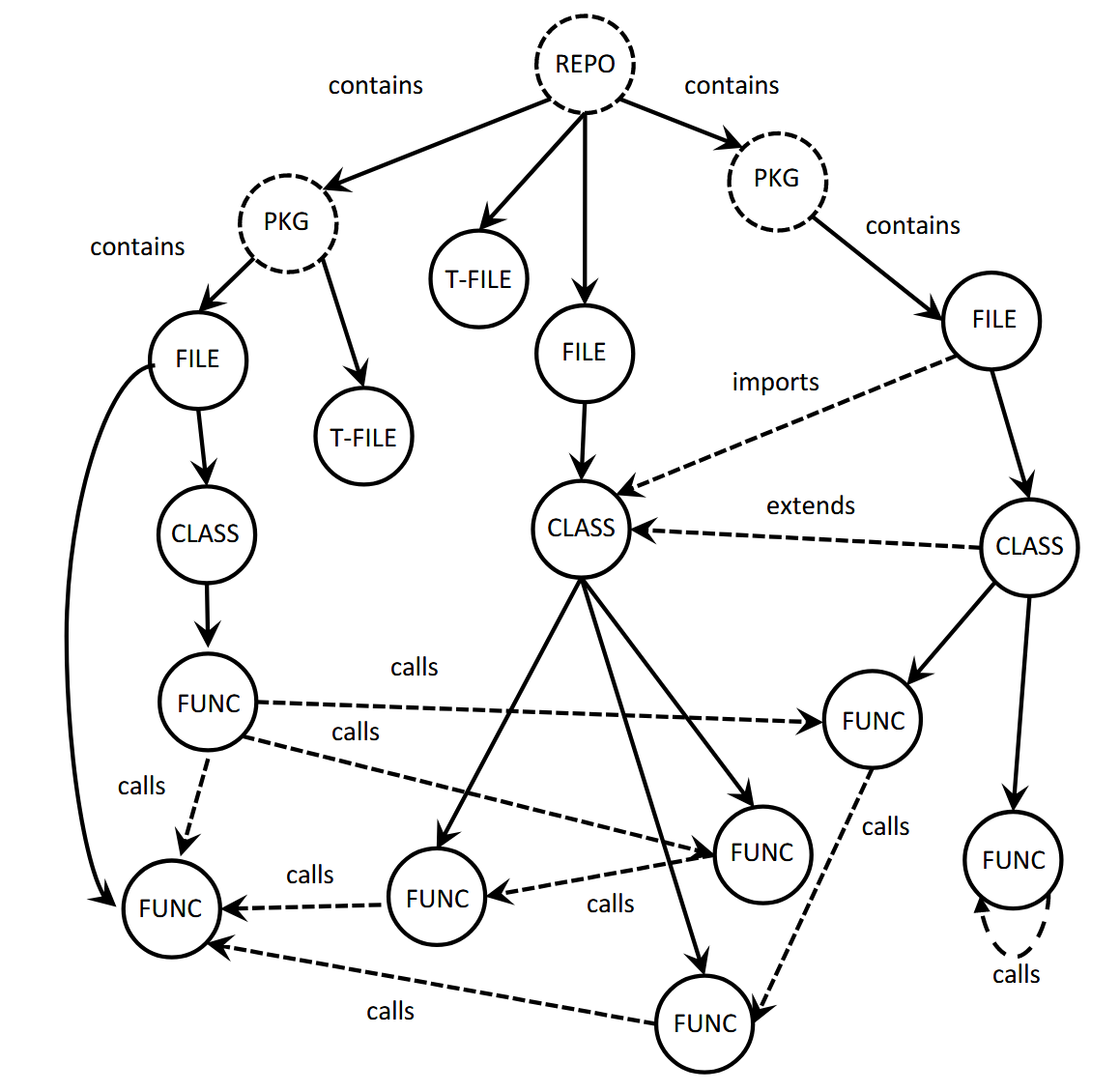
(Code Graph) CGM 采用如下方式构建 Code Graph $G = (V, E)$:
- 首先是当前 Repository 按照类似文件系统的方式构建树 (solid edge 表示包含关系);
- 利用 dashed edges 表示实体间的 reference dependencies (e.g., class inheritance, function calls, module imports).
- 每个节点记录 content, line range 等属性.
(Semantic Information) CGM 利用 CodeT5+ 将对每个节点进行预处理, 得到每个节点的向量表示.
(CGM, Code Graph Model):
- Code Graph Model 以 QWen-2.5 72B 为基模, 进行 LoRA 微调.
- 输入: (I) 通过上述方式得到的 (sub) Code Graph 的节点向量表示 (顺序无关), 这些表示需要通过一个 Adaptor (可训练); (II) 图中节点所对应的具体的代码文件 (按照文件结构的拓扑结构排序), 同一文件中的代码按照行号正常排序.
- Graph Attention Mask. Code Graph 部分不采用传统的 Causal Attention, 按照 Code Graph 的邻接矩阵进行 mask.
Training
- CGM 的训练分为两部分, 如上图所示, 训练过程中 Encoder (CodeT5+) 以及 CGM (Qwen2.5-72B-instruct) 均采用 LoRA 微调:
- (Subgraph Reconstruction Pre-training) 为了让 Encoder 和 CGM 抓住更高效的结构信息, 首先通过一个 Graph -> Code 的重建任务进行训练: 通过按照拓扑顺序排列子图的 node embedding (通过 CodeT5+ 提取), 后续重建对应的 code.
- (Noisy Fine-tuning) 为了更好地在 SWE-Bench 等实际 repository-level 的任务上应用, 该阶段在 subgraph & hints_text (指明那些文件需要被修改) 的基础上生成对应的 code patches. 注意, 这里 subgraph 融入了真正需要修改的文件, 下游节点以及一跳邻居. 为了进一步提高模型鲁棒性 (因为实际推理的时候不存在完美的 hints_text, 会导致"需要修改的文件"或者多或者缺), 10% 的实例增加无关文件, 10% 实例缺失相关文件.
Inference
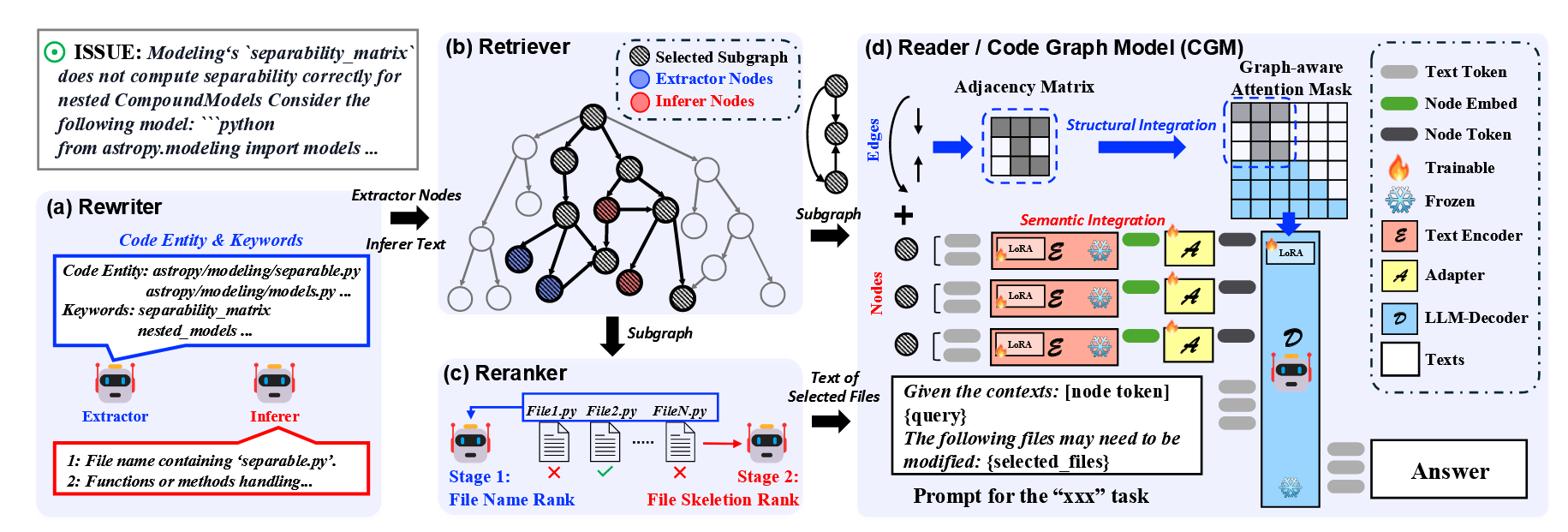
- 因此, CGM 修复一个 Bug 的流程如下:
- Rewriter (Qwen2.5-72B-instruct): Extractor 确定 ISSUE 的关键元素: 文件名, 函数名等. Inferer 在此基础上进行进一步润色, 添加具体的功能描述.
- Retriever (CGE-Large model): 在 Rewriter 给定信息的基础上, Retriever 抽出一个合适的 subgraph 用于后续推理.
- Reranker (Qwen2.5-72B-instruct): 通过上述方式可能选中相当多的代码文件, 这会导致 context 变得相当冗长, reranker 进一步筛选出 Top-K 最相关的.
- Reader (finetuned Qwen2.5-72B): 将 subgraph (node embeddings) 和选中的文件作为输入, CGM 进行代码生成.