Climber: Toward Efficient Scaling Laws for Large Recommendation Models
预备知识
- (Recommendation Scaling Law) 自从 Scaling Law 在语言模型中取得了广泛成功之后, 推荐, 尤其是工业界对推荐的 Scaling Law 也进行了持续的研究: 包括 META 的 HSTU, Wukong, 快手的 OneRec 系列, 美团的 MTGR 等等.
核心思想
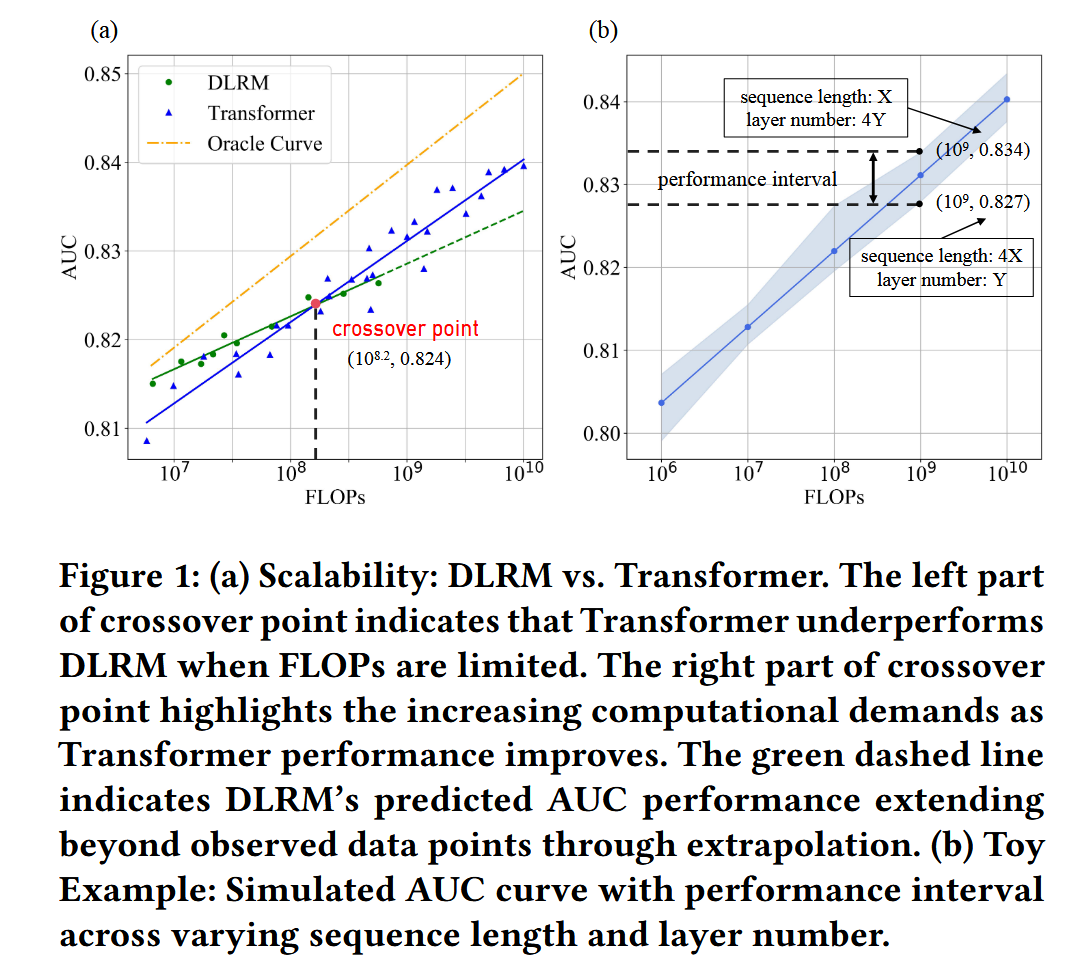
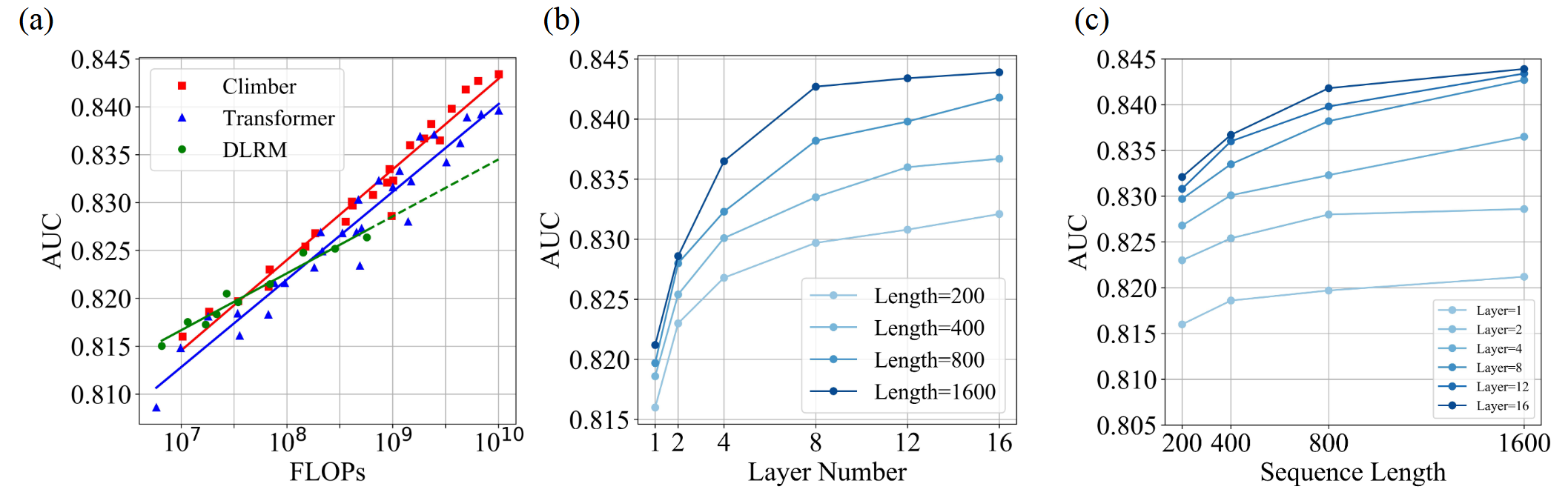
(Scaling Law of Transformer-based Recommendation.) 本文首先展示了 推荐的 Scaling Law, 发现 Transformer 其实并不是最佳的架构, 其需要大量的 FLOPs 下才能超过经典的 DLRM 模型. 此外, 作者还发现, 通过调节层数和序列长度, 我们能够使得 Scaling 的效率大大提高.
(更高效的架构 Climber) 为此, 本文希望提出一种更为高效的架构, 核心在于更好的利用用户长序列行为.
一般的用户行为序列是不具备语义的那种连贯性, 因此 Climber 首先会利用不同的策略对原本的用户序列分解为多个子序列:
$$ S_1, S_2, \ldots, S_{N_b}, $$这一方面提高了子序列的连贯性, 另一方面能够大大缓解用于序列长度带来的复杂度.
Adaptive Transformer Layer (ATL): 接着 ATL 会单独地处理每个子序列, 这部分一般的 Transformer Block 区别在于:
$$ \text{Softmax}(R(S_k) / f_{tc}(a_k, r)), $$这里并没有固定的 $\sqrt{d}$ 作为 temperature 调节 attention 权重, 而是利用一个可学习的项来自适应调节.
Bit-wise Gating Fusion: 这一步将先前的各个子序列的表示拼接得到整个序列: $E(S) \in \mathbb{R}^{N_b \times d}$, 然后进行子序列的交叉融合.
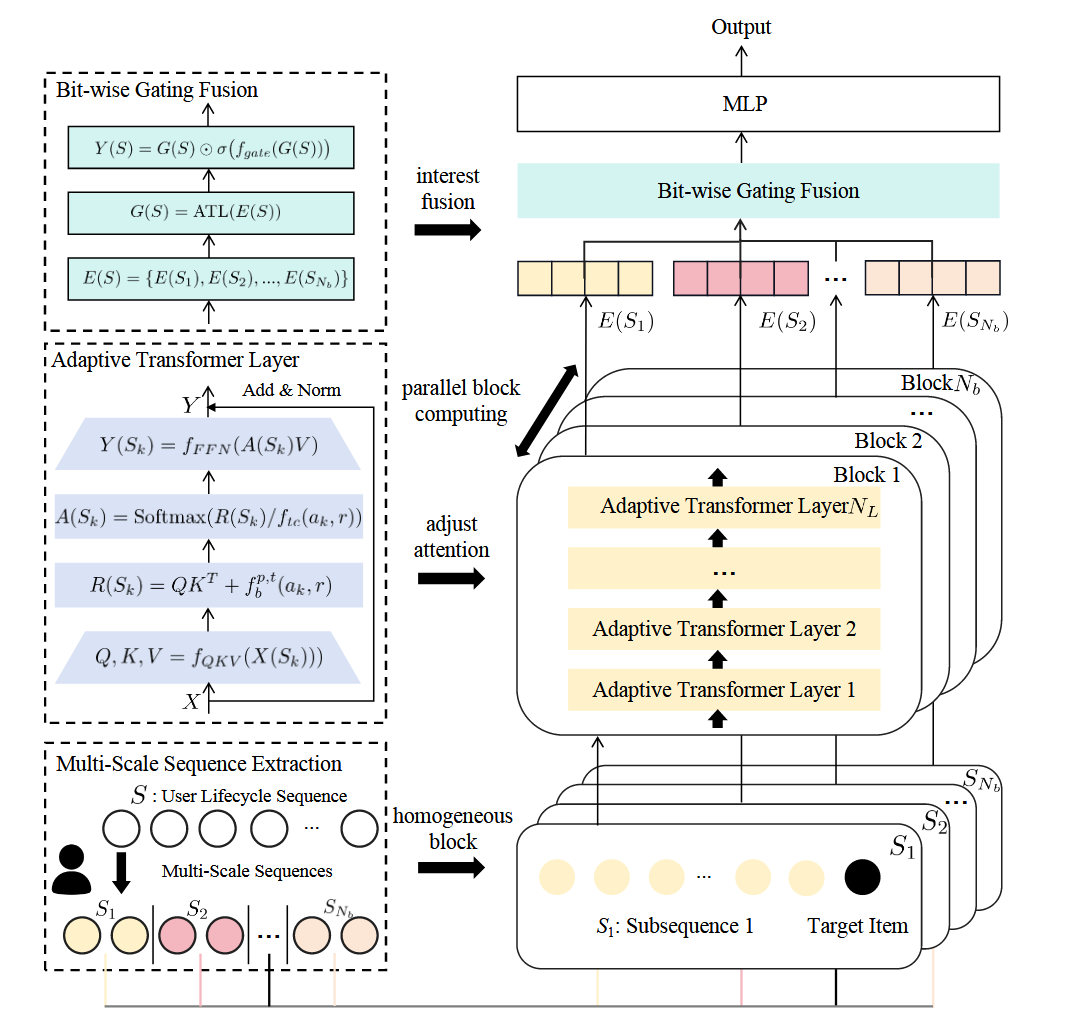
- (Scaling Law of Climber)