Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations
预备知识
核心思想
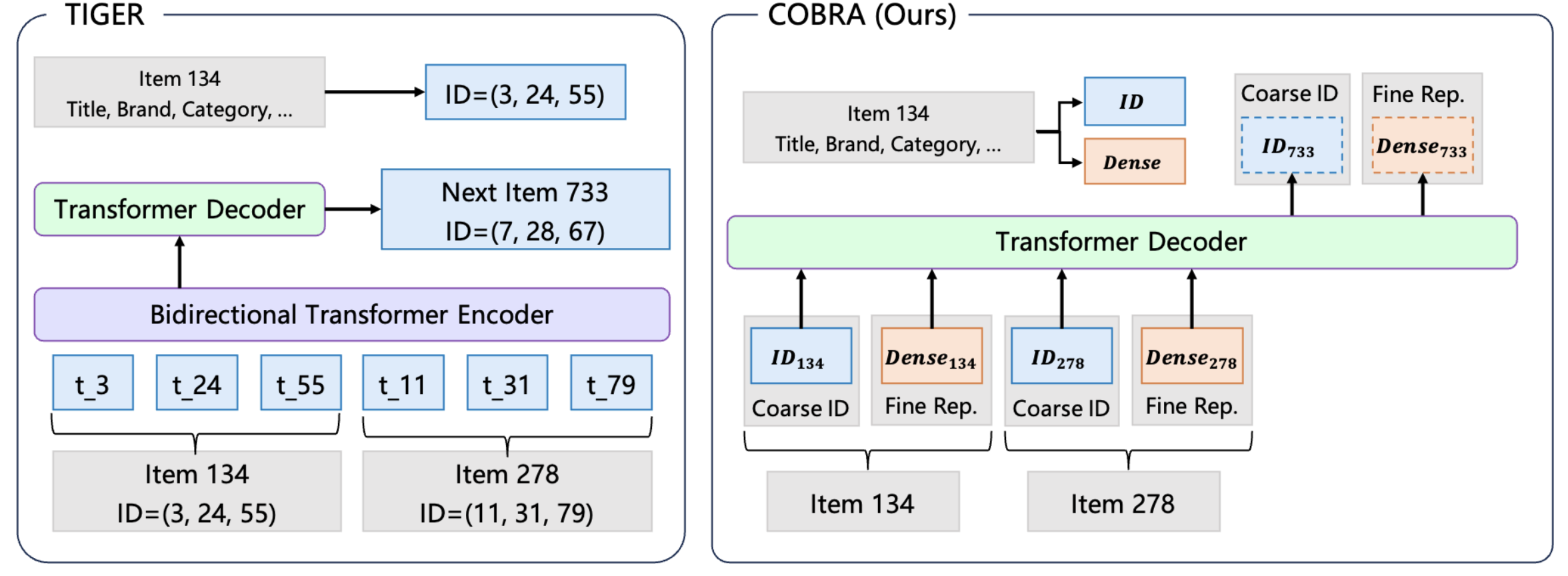
- COBRA 是来自百度团队的作品.
- 出发点: 类似 TIGER 的采用离散编码的做法会造成明显的信息损耗, 因此 COBRA 希望在原本的离散编码的基础上更进一步:
- 根据用户交互序列生成 next-item 的离散编码;
- 根据生成的一组离散编码, 细化得到稠密向量;
- 兼顾离散编码以及稠密向量的得分来给出最终的得分.
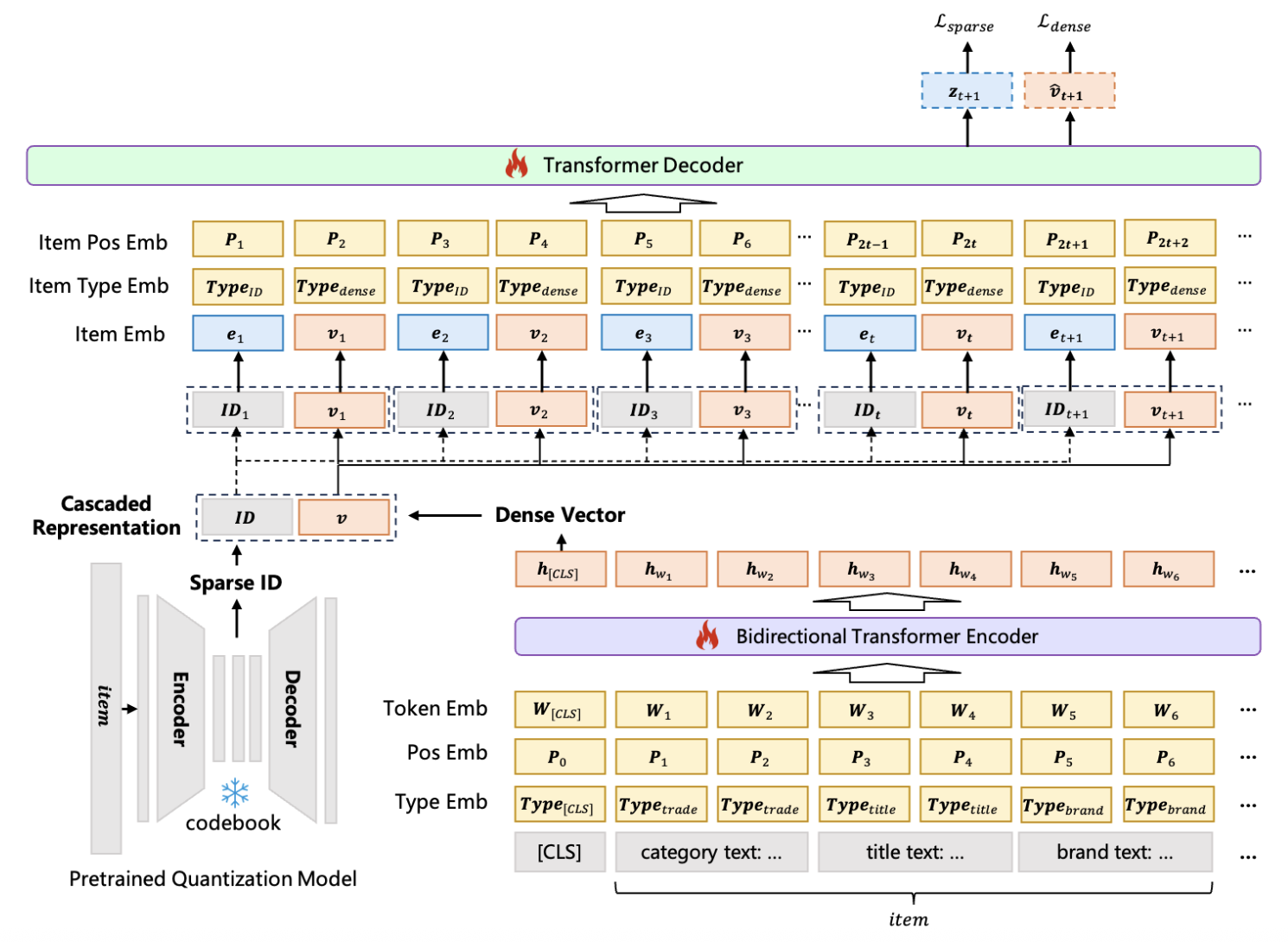
Sparse Representation: 类似于 TIGER, 采用 RQ-VAE 为每个 item 赋予一组语义 IDs.
Dense Representation: End-to-end 地训练一个 Encoder, 其中的 [CLS] token 作为整个 item textual features 的融合表征, 记为 $\mathbf{v}$.
推理流程:
输入: 因此, 输入序列的每个 item 都由一组 Sparse & Dense 表示组成, 即 $(ID_t, \mathbf{v}_t)$.
输出: 输出同样包含 Sparse & Dense 两个输出. 假设输入的序列为 $S_{1:t}$, 则预测下一个 item 的流程为:
$$ \mathbb{P}(ID_{t+1}, \mathbf{v}_{t+1} | S_{1:t}) = \mathbb{P}(ID_{t+1} | S_{1:t}) \cdot \mathbb{P}(\mathbf{v}_{t+1} | S_{1:t}, ID_{t+1}). $$即先输出 item 的离散编码, 然后再以此为条件, 进一步细化得到稠密表示. 特别注意的是, item 的离散编码是 TransformerDecoder 的输出过一个 SparseHead 得到的, 而稠密表示直接就是 TransformerDecoder 的输出.
训练: 对于 Sparse ID 采用普通的 next-token loss, 而对于 dense representation, 采取 in-batch 的交叉熵训练 (毕竟 dense 的词表有点大).
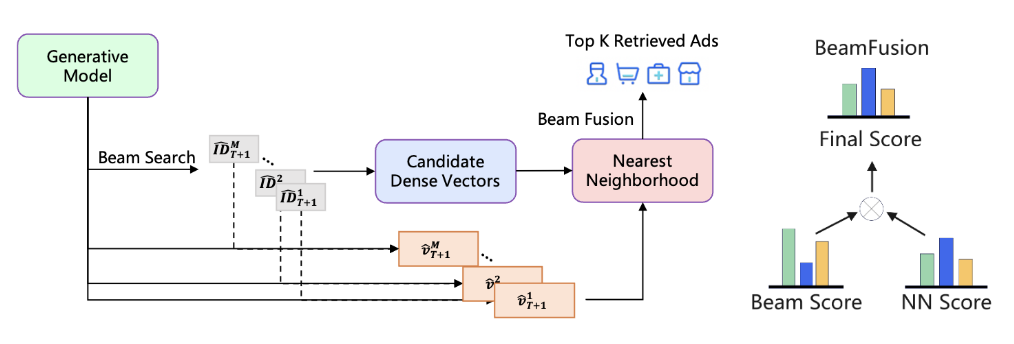
- Coarse-to-Fine Generation:
- 通过 BeamSearch 生成多个离散 IDs;
- 将上述得到每一个 ID 单独作为条件得到其 refined 的 dense 表示;
- 综合离散 ID 的 beamsearch 得分, 和 dense 表示计算得到的 (cosine) 相似度得分, 对候选商品进行排序. COBRA 称之为 BeamFusion.
注: 其实 LIGER 也尝试了 Sparse & Dense 表示的混用, 其主要出发点是其发现 Sparse 表示容易过拟合到见过的 Sparse ID 组合, 从而在冷启动商品上的表现不佳. 不知道, COBRA 的工作诞生是不是有这方面的影响.