CodeT5
Content
研究背景
- (研究背景) Code 领域有很多 encoder-only, decoder-only, 以及部分 encoder-decoder 架构的模型, 然而这些架构各擅胜场, 也各有不足之处.
核心思想
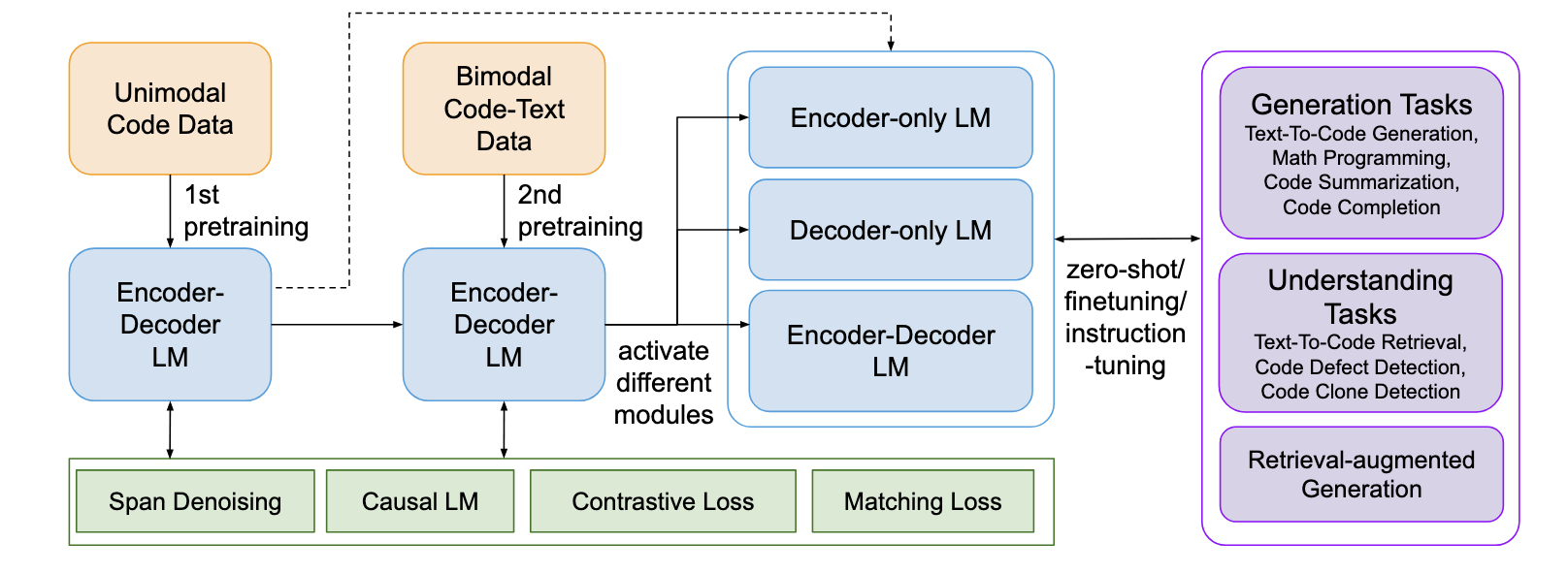
- CodeT5/CodeT5+ 旨在通过多任务训练 encoder-decoder 架构的基模, CodeT5+ 在此基础上进一步丰富任务类型, 同时强调在推理时应当采用不同的组件 (encoder-only, decoder-only, 或者 encoder-decoder) 来解决.
| 任务 | 模型 | 描述 |
|---|---|---|
| Span Denoising | CodeT5/CodeT5+ | 预测 15% 被 mask 的 tokens |
| Identifier Tagging | CodeT5 | 预测 token 是否为有具体含义 (如变量名, 函数名) |
| Masked Identifier Prediction | CodeT5 | 自回归地预测专门被 mask 的 identifier |
| Causal Language Modeling | CodeT5+ | “将 [CLM]XXX” 输入 Encoder 并利用 Decoder 预测 XXX, 通常采样 10%~90% 的序列片段作为 Encoder 的输入, 或者最极端情况, Encoder 输入仅 “[CLM]” 相当于单纯的生成任务 |
| Bimodal Dual Generation | CodeT5/CodeT5+ | Text -> Code 和 Code -> Text 的生成 |
| Text-Code Contrastive Learning | CodeT5+ | 仅通过 Encoder 提取 Text 和 Code 的向量表示, 利用对比学习监督 |
| Text-Code Matching | CodeT5+ | 将 “[Mask] (T, C) [EOS]” 输入到 Decoder 中然后对 [EOS] 的输出通过线性层做二分类预测: Match/NOT Match |
- (训练技巧) CodeT5+ 采取 “shallow encoder and deep decoder” 的架构, 利用已有的预训练模型进行初始化并冻结 Decoder 的参数. 此外, 在 Decoder 的 top-$L$ 层中加入可学习的 cross-attention layer, 该设计能够显著降低训练开销.
参考文献
- Wang Y., Wang W., Joty S. and Hoi S. C. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. ACL, 2021. [PDF] [Code]
- Wang Y., Le H., Gotmare A. D., Bui N. D., Li J. and Hoi S. C. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. ACL, 2023. [PDF] [Code]