CoFiRec: Coarse-to-Fine Tokenization for Generative Recommendation
Content
研究背景
-
(生成式推荐中的 Tokenization)生成式推荐 (Generative Recommendation) 将 item 映射为离散 token 序列, 通过自回归模型预测下一个 item. RQ-VAE 等残差量化方法是主流 tokenization 方案, 但它们在量化前将所有 item 属性 (ID, 类别, 标题, 描述等) 扁平化为单一 embedding, 丢失了自然的语义层级结构.
-
(真实情况) 用户在 web 场景中的偏好是逐步细化的: 从大类 (乐器) → 子类 (电吉他) → 系列 (Yamaha Pacifica) → 具体单品. 现有方法忽略了这一从粗到细 (coarse-to-fine) 的自然语义递进过程.
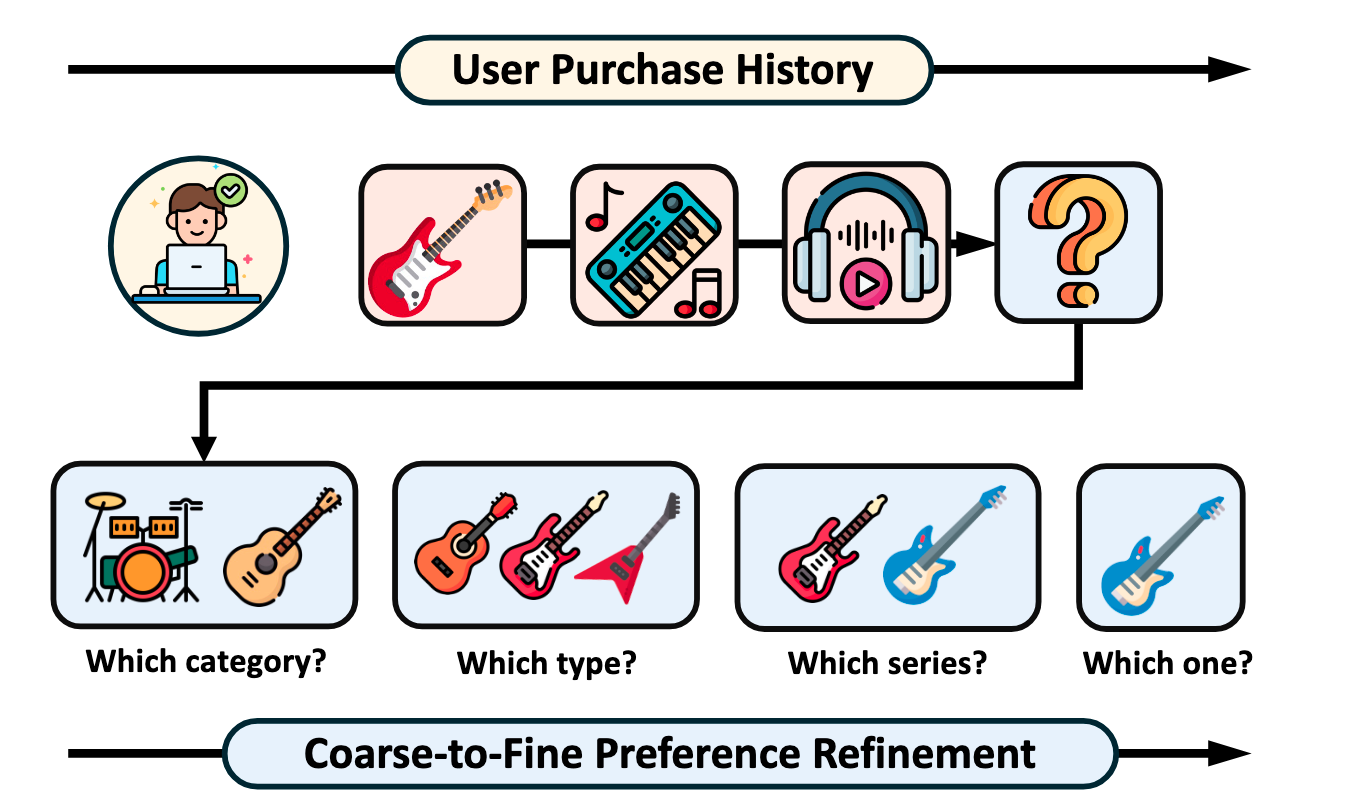
核心思想
-
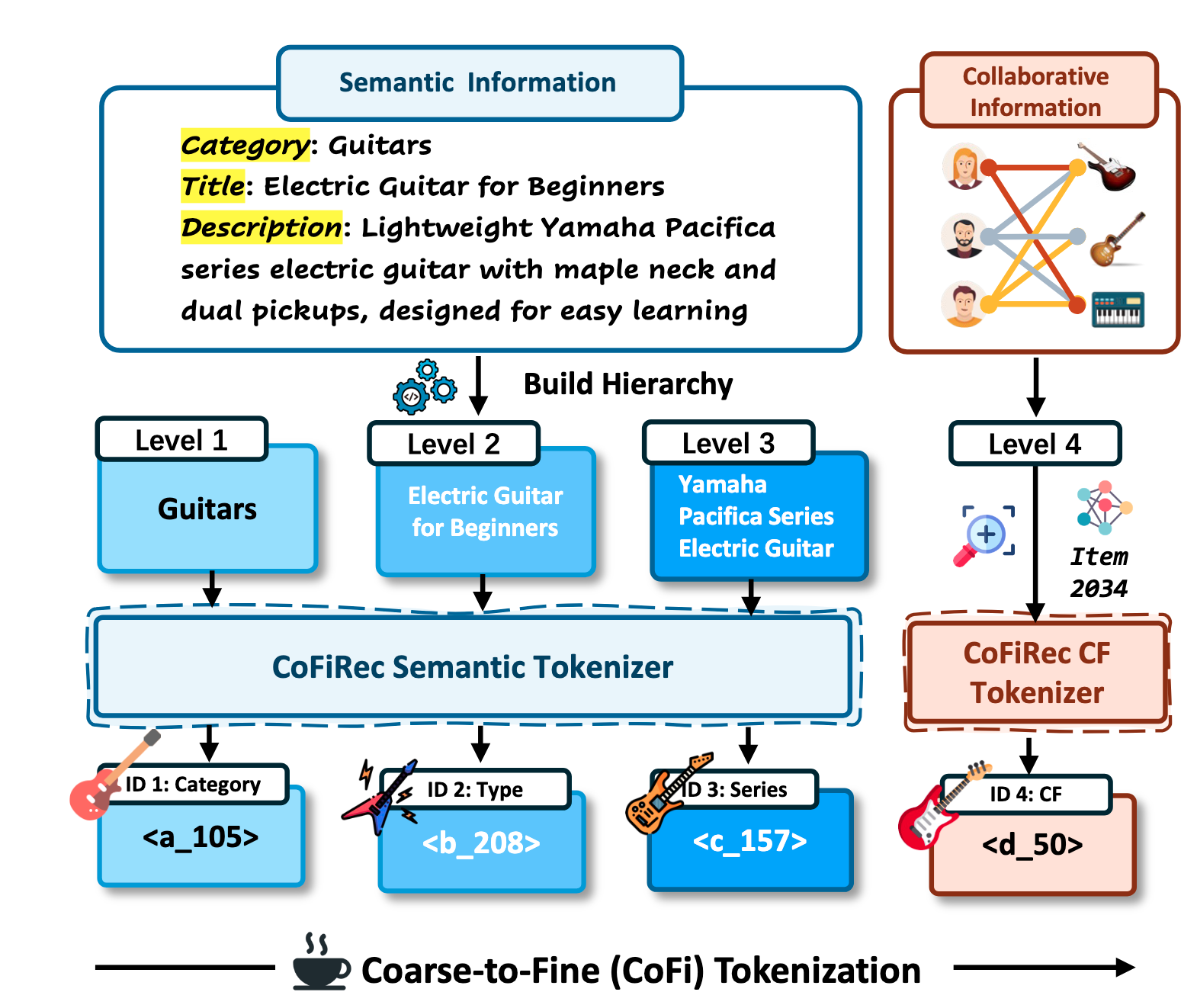
(层级构建) 对每个 item $i$, 基于其元数据构建 $K$ 级语义层级 $[x_i^{(1)}, x_i^{(2)}, \ldots, x_i^{(K)}]$, 其中前 $K-1$ 级对应文本语义 (如 category → title → description), 最后一级 $x_i^{(K)}$ 编码协同过滤 (CF) 信息:
$$ S_i = [s_i^{(1)}, \ldots, s_i^{(K-1)}, s_i^{(K)}]. $$ -
CoFiRec Semantic Tokenizer. 对每个语义层级 $k \in \{1, \ldots, K-1\}$, 先用预训练 LLM 提取 embedding $\mathbf{e}_i^{(k)}$, 再通过共享的语义编码器 $f_{\text{Sem}}$ 和独立的 VQ 模块 $Q_k$ 量化:
$$ \mathbf{h}_i^{(k)} = f_{\text{Sem}}(\mathbf{e}_i^{(k)}), \quad s_i^{(k)} = Q_k(\mathbf{h}_i^{(k)}). $$ -
CoFiRec CF Tokenizer. 对最后一级, 从预训练 CF 模型 (如 SASRec) 获取协同 embedding $\mathbf{e}_i^{\text{cf}}$, 通过独立的 CF 编码器量化:
$$ \mathbf{h}_i^{(K)} = f_{\text{CF}}(\mathbf{e}_i^{\text{cf}}), \quad s_i^{(K)} = Q_{\text{CF}}(\mathbf{h}_i^{(K)}). $$每个 codebook 独立维护, tokenizer 训练目标为重构损失 + 承诺损失: $\mathcal{L}_{\text{Tokenizer}} = \mathcal{L}_{\text{Recon}} + \mathcal{L}_{\text{Commit}}$.
-
Coarse-to-Fine 自回归生成. Tokenizer 训练完成后, 下游语言模型按 coarse-to-fine 顺序逐 token 生成:
$$ P(s^{(K)}, \ldots, s^{(1)} | H_u) = \prod_{k=0}^{K} P(s^{(k)} | s^{(分别编码 token ID、语义层级和序列位置.
关键洞察
- 消融实验表明: (i) 打乱 token 顺序 (reverse/random) 显著降低性能, 验证了 coarse-to-fine 结构的必要性; (ii) 去掉 CF token 导致退化, 说明行为信号对区分语义相似 item 至关重要; (iii) 移除 $E_{\text{level}}$ 和 $E_{\text{pos}}$ 同样造成明显下降.
-
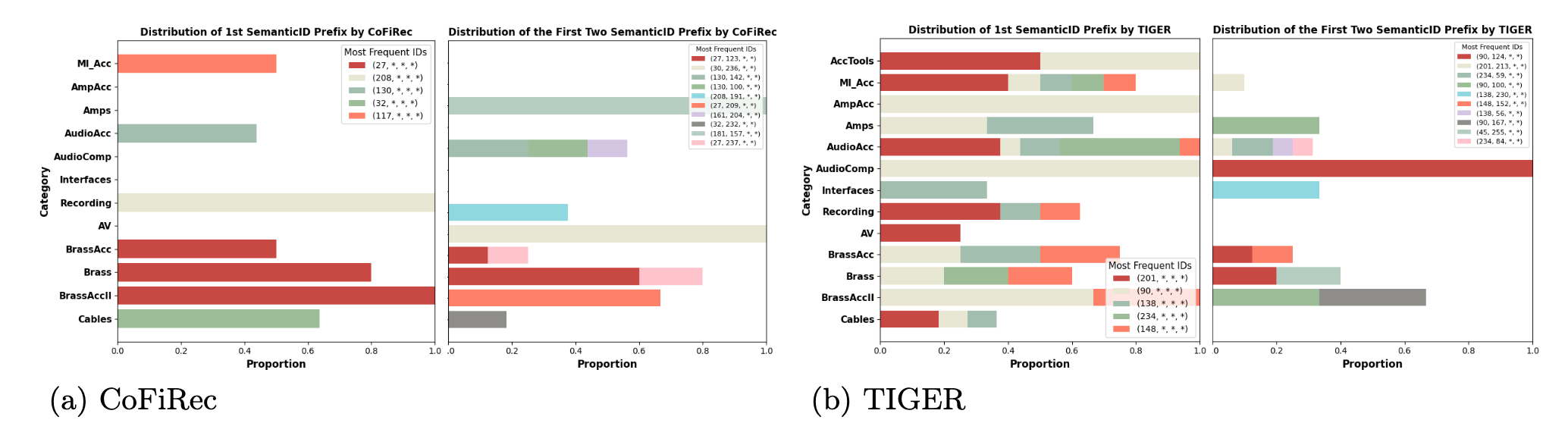
可视化显示 CoFiRec 的语义 ID 前缀与 item 类别高度对齐 (相同大类共享 first token), 而 TIGER 的 ID 分布则较为散乱, 缺乏语义一致性.
-
Codebook 利用率从粗到细递增 (79% → 88% → 75% → 99%), 细粒度层级需要更大的容量来区分相似 item.