Differentiable Semantic ID for Generative Recommendation
Content
研究背景
-
生成式推荐 (Generative Recommendation) 因其紧凑的表示空间、良好的冷启动性质以及与 LLM 等现代范式的兼容性, 成为了社区的研究热点.
-
RQ-VAE 等向量量化方法是生成式推荐的基石, 其将 Item 映射为形如 (c₁, c₂, …, cₘ) 的语义 ID 序列 (Semantic IDs, SIDs), 在高效表示的同时具有良好的可解释性. 然而, 目前主流的量化方法多基于传统的重构损失进行学习, 难以有效捕捉对推荐系统至关重要的协同信号.
核心思想
-
根据 RQ-VAE 可知, 对于每个 item $v \in \mathcal{V}$, 我们可以得到其 SID, 即 $m$ 个离散的 codes:
$$ \mathbf{z}_v = (c_{v,1}, \ldots, c_{v, m}), \quad c_{v, j} \in \{1, \ldots, K\}. $$这里, $K$ 表示 RQ-VAE 中每一个 codebook 的大小.
-
因此, 对于一个用户, 假设其交互序列为 $\mathbf{h}_u = (v_1, \ldots, v_t)$, 则我们可以相应得到 SID 序列:
$$ \mathbf{x}_u^{(t)} = \mathbf{z}_{v_1} \oplus \cdots \oplus \mathbf{z}_{v_t}, $$这里 $\oplus$ 表示拼接操作.
-
生成式推荐模型自回归地预测目标:
$$ p_{\theta}(\mathbf{z}_{v_{t+1}} | \mathbf{x}_u) = \prod_{j=1}^m p_{\theta} \left( c_{v_{t+1}, j} | \mathbf{x}_u^{(t)}, c_{v_{t+1}, < j} \right). $$相应的自回归损失为
$$ \mathcal{L}_{gen} = -\sum_u \sum_t \log p_{\theta}(\mathbf{z}_{v_{t+1}} | \mathbf{x}_u^{(t)}). $$ -
生成式推荐通常采用两阶段范式:
- SID 生成阶段: 训练 RQ-VAE 等 tokenizer;
- 推荐训练阶段: 通过固定的 tokenizer 将 item 编码为 SIDs, 并基于 SIDs 以 $\mathcal{L}_{gen}$ 进行训练.
-
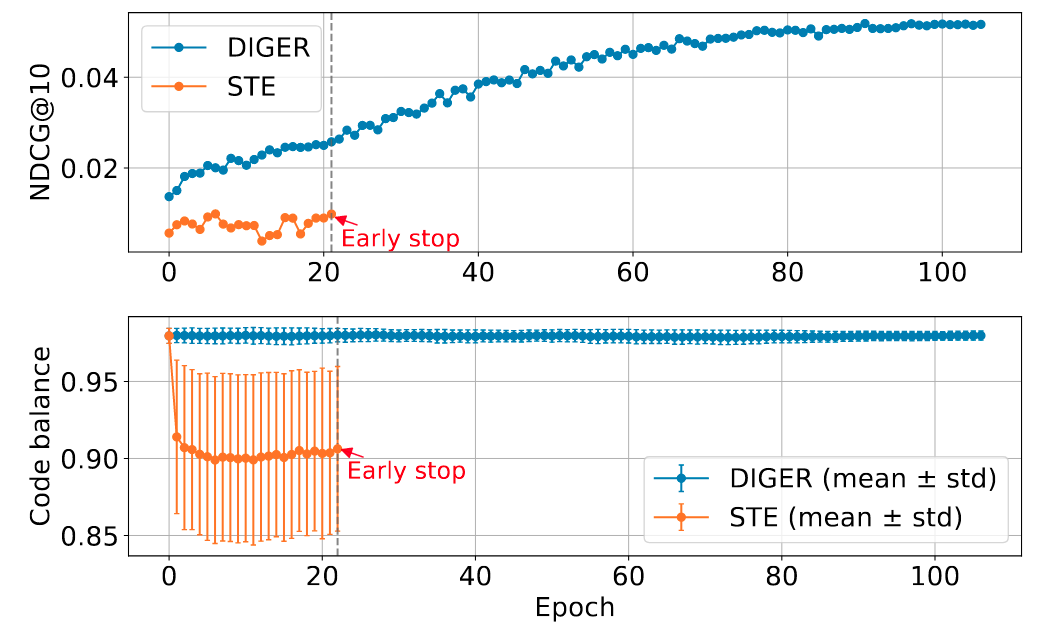
为了联合训练 tokenizer 和 recommender, 最直接的方式是采用 STE (Straight-Through Estimator) 实现梯度传播. 然而这种方式存在明显缺陷: 1. codebook 利用率低下; 2. 训练过程不稳定.
-
为此, 本文作者采用 Gumbel-Softmax Sampling 替代 STE:
$$ \tilde{y}_{v, j, i} = \frac{ \exp \left( (\ell_{v, j, i} + g_{v, j, i}) / \tau \right) }{ \sum_{k=1}^K \exp \left( (\ell_{v, j, k} + g_{v, j, k}) / \tau \right) }, \quad \ell_{v, j, i} = \text{sim}(\mathbf{r}_{v, j}, \mathbf{e}_i), \quad i \in \{1, \ldots, K\}. $$这里 $\mathbf{r}_{v, j}$ 是第 $j$ 个阶段的残差向量, $\tilde{y}_{v, j, i}$ 定义了 $\mathbf{r}_{v, j}$ 分配到 $\mathbf{e}_i$ 上的概率, $g_{v, j, i}$ 是采样自 Gumbel(0, 1) 的噪声. 在训练过程中, 实际采用的输出为
$$ \bar{\mathbf{e}}_{v, j} = \sum_{i=1}^K \tilde{y}_{v, j, i} \mathbf{e}_i. $$ -
Gumbel-Softmax 的关键在于退火策略的设计 (即 $\tau$ 的调整方式), DIGER 提出了两种方案:
-
Standard Deviation Uncertainty Decay (SDUD): 令 $\sigma = \text{std}(g / \tau)$, DIGER 通过最小化如下目标动态调整 $\sigma$ / $\tau$:
$$ \mathcal{L}_{\sigma} = \frac{\mathcal{L}_{gen}}{2 (\sigma + \lambda)^2} + \log (\sigma + \lambda). $$这里 $\lambda > 0$ 是一个超参数, 注意到
$$ \frac{\partial \mathcal{L}}{\partial \sigma} = 0 \Rightarrow (\sigma + \lambda)^2 = \mathcal{L}_{gen} \Rightarrow \sigma^* = \max(0, \sqrt{\mathcal{L}_{gen}} - \lambda). $$换言之, 当推荐损失逐步降低时, Gumbel-Softmax 采样的方差逐步降低, 趋于硬匹配.
-
Frequency-based Uncertainty Decay (FrqUD): SIDs 的重要指标之一是码本利用率, FrqUD 旨在平衡各码本的利用率, 避免部分码本未被充分利用. 通过如下 EMA 平均的方式记录每个 code 的利用率:
$$ f_i^{(e)} \leftarrow \beta f_i^{(e - 1)} + (1 - \beta) \hat{f}_i^{(e)}, \quad \beta \in [0, 1). $$设定阈值为 $\gamma = \frac{r}{K}$, 区分高频和低频 codes:
$$ \mathcal{I}_{high}^{(e)} = \{i | f_i^{(e)} > \gamma\}, \quad \mathcal{I}_{low}^{(e)} = \{1, \ldots, K\} \setminus \mathcal{I}_{high}^{(e)}. $$若 code $i \in \mathcal{I}_{high}$, 则加入 Gumbel-Softmax noise 促使其分配到其他 codes; 若 $i \in \mathcal{I}_{low}$, 则不添加 noise 以提高低频 codes 的利用率.
-
关键洞察
- 在看了作者提供的代码之后, 我发现我对于 DIGER 有着深深的误解, DIGER 压根就不能算是 “Differentiable Semantic ID”, 其实际训练流程为:
- 预训练 RQ-VAE: 首先和一般方法一样预训练 RQ-VAE;
- 联合训练阶段, Tokenizer 部分并不会受到推荐损失 $\mathcal{L}_{gen}$ 的直接监督, 仅仅是二者一块训练, 然后在每个 epoch 会重新计算 SIDs 而已.
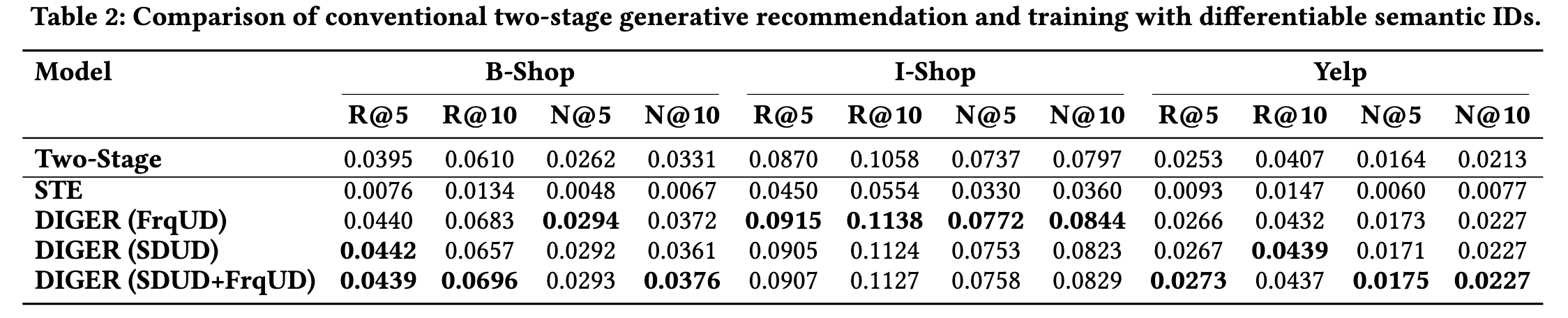
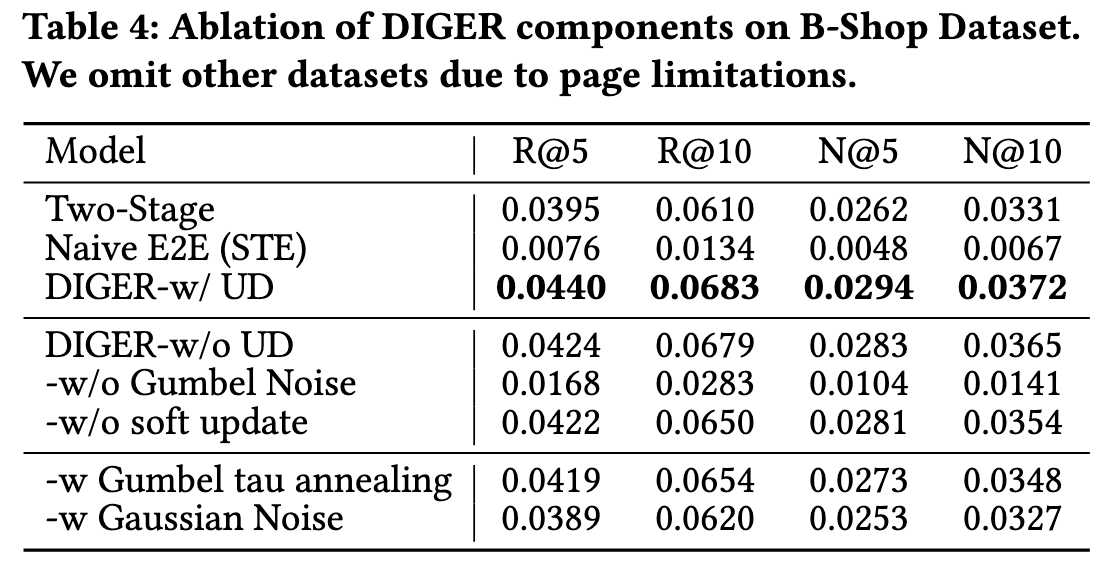
- 从 Table 2 可以发现, DIGER 相比 STE 性能大幅领先, 而
FrqUD,SDUD以及SDUD+FrqUD之间差异不大. 从 Table 4 亦可看出, DIGER w/o UD 的性能亦未出现明显退化, 这表明 Gumbel-Softmax Sampling 本身是 DIGER 的核心改进.
继往开来
- Tokenizer 与 Recommender 的联合优化是一个有价值的研究方向, 但 DIGER 的设计个人认为有些过于画蛇添足了.