Dynamic Key-Value Memory Networks for Knowledge Tracing
Content
预备知识
核心思想
之前的 DKT, 比如利用 RNN 的方式, 还是一种 序列特征提取 -> 二分类 这样的传统的方式, 这种方式没法给我们一些更多的信息: 学生在不同 concepts 上的掌握程度.
DKVMN (Dynamic Key-Value Memory Networks) 主要是通过改进一个记忆网络 MANN 来实现对习题的概念和学生的掌握情况的一个动态建模.
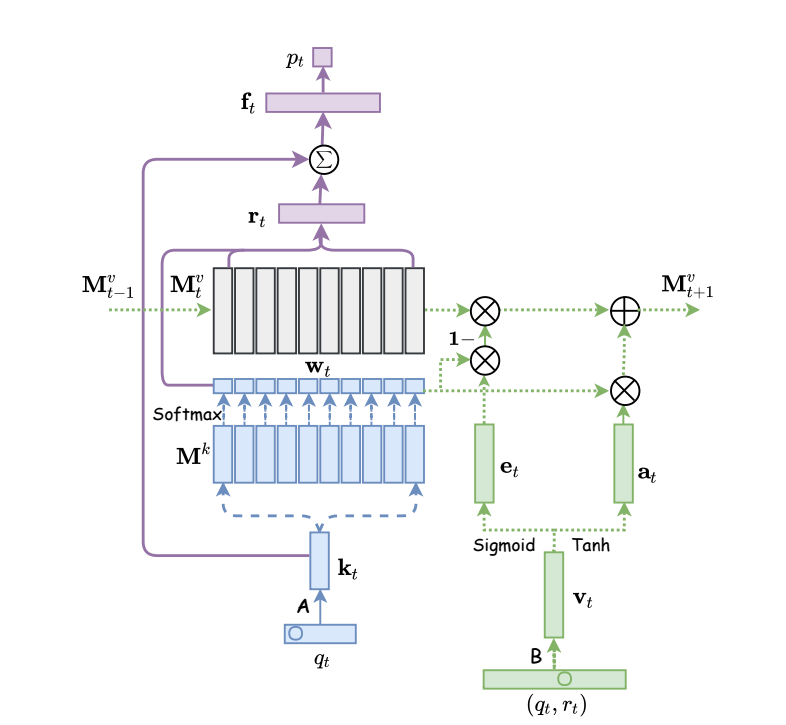
我们构建 $\mathbf{M}^k \in \mathbb{R}^{N \times d_k}$ 来建模 $N$ latent concepts $\{c^1, c^2, \ldots, c^N\}$, 以及 $\mathbf{M}^v \in \mathbb{R}^{N \times d_v}$ 来建模某个学生的对于不同 concept 的掌握情况 $\{\mathbf{s}_t^1, \mathbf{s}_t^2, \ldots, \mathbf{s}_t^N \}$. 并用 $\mathbf{M}_t^v$ 表示在了解 $q_t$ 做题情况后的状态.
Read: 通过 $q_t$ 从 $Q \times d_k$ 的 embedding table 中检索出其对应的 embedding $\mathbf{k}_t$:
计算 read 的权重分布:
$$ w_t(i) = \text{Softmax}(\mathbf{k}_t^T \mathbf{M}^k (i)). $$通过 value matrix 进行初步加权 read:
$$ \mathbf{r}_t = \sum_{i=1}^N w_t(i) \mathbf{M}_{t - 1}^v (i). $$由于每个题目都有其特别之处, 所以最终的用于预测题目错对的向量为:
$$ \mathbf{f}_t = \text{Tanh}\big( \mathbf{W}_1^T [\mathbf{r}_t, \mathbf{k}_t] + \mathbf{b}_1 \big). $$
通过如下方式进行预测:
$$ p_t = \text{Sigmoid}( \mathbf{W}_2^T \mathbf{f}_t + \mathbf{b}_2 ). $$Write: 更新 $\mathbf{M}_t^v$ 分为 “遗忘和加强” ($\mathbf{v}$ 是根据 $(q, r)$ 从 $2Q \times d_v$ 的 embedding table 中检索出的 embedding):
- 遗忘 (erasing):
- 增强:
通过 BCE 进行训练.