EARN: Efficient Inference Acceleration for LLM-based Generative Recommendation by Register Tokens
预备知识
当下主流的 Transformer 模型都是自回归式的, 因而在推理过程中 ‘prefix’ 部分的推理是重复的, 通过 KV cache 可能降低由这部分重复所带来的额外开销.
LLMRec 和一般的语言模型在 decoding 长度上有很大的区别, 通常预测下一个 item 只需要 $\ge 5$ tokens 即可.
EARN
出发点
LLMRec 是当下推荐系统领域中比较火的一个方向, 但是它有一个众所周知的问题: 其推理时间远远大于传统模型所需的时间, 对于推荐系统这种强调时效性的任务而言是不可接受的.
假设我们有一个 LLM $f(\cdot)$, 其推理方式为:
Prefilling: 给定 input prompt $x_{1:t}$ (对于推荐系统而言, 这部分通常包含用户的交互序列):
$$ \hat{x}_{t+1} \leftarrow f(x_{1:t}). $$Decoding: $\hat{x}_{t+2} \leftarrow f(x_{1:t}, \hat{x}_{t+1})$, 以此类推.
LLM 的推理过程是并行的, 因此正常的不加任何调整的情况下, 在 decoding 的过程中, $x_{1:t}$ 的 tokens 之间的 key, value 都会重复计算, 因此是相当消耗时间的.
KV cache, 顾名思义, 把计算过程中的 Key, Value 保存下来, 以此减少重复的计算量. 下面是 prefilling 和 decoding 部分的 KV cache 的示意图:
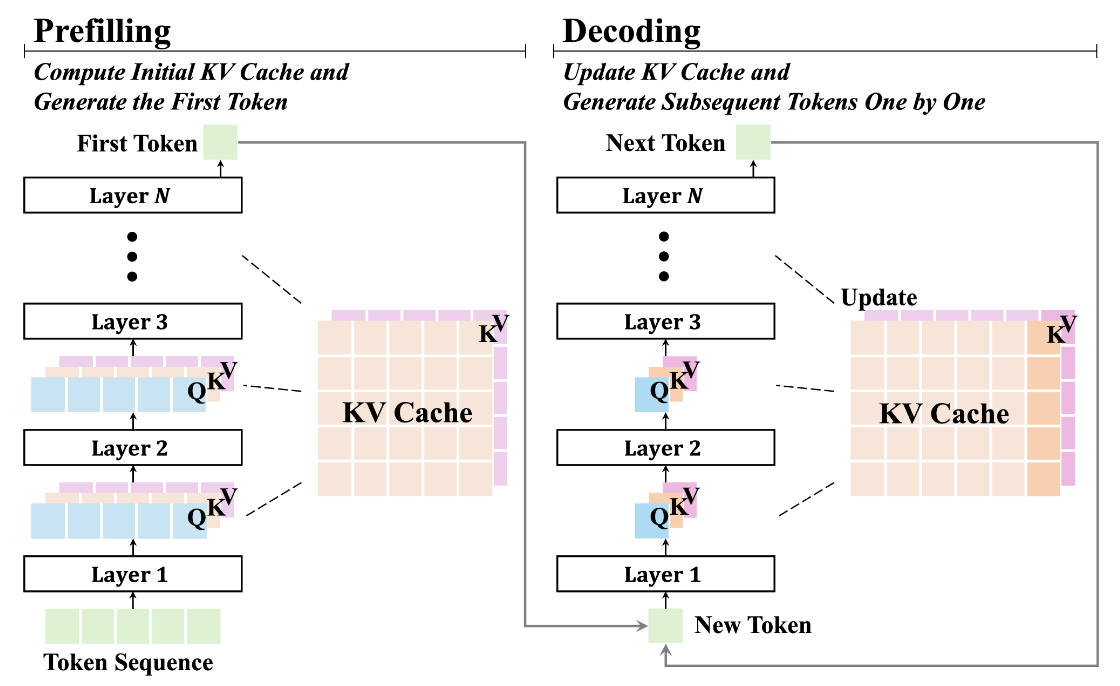
即 prefilling 过程首先将整体的 KV 初始化, decoding阶段即生成一个 token, 更新以此 KV.
但是, 对于 LLMRec 而言, 这样子的操作并不会带来巨大的效率提升: 因为 LLMRec 的 decoding 阶段通常只需要生成 $\le 5$ tokens.
因此, 真正有效的策略应该是怎么直接降低 prefilling 阶段的 KV cache size!
有趣的发现
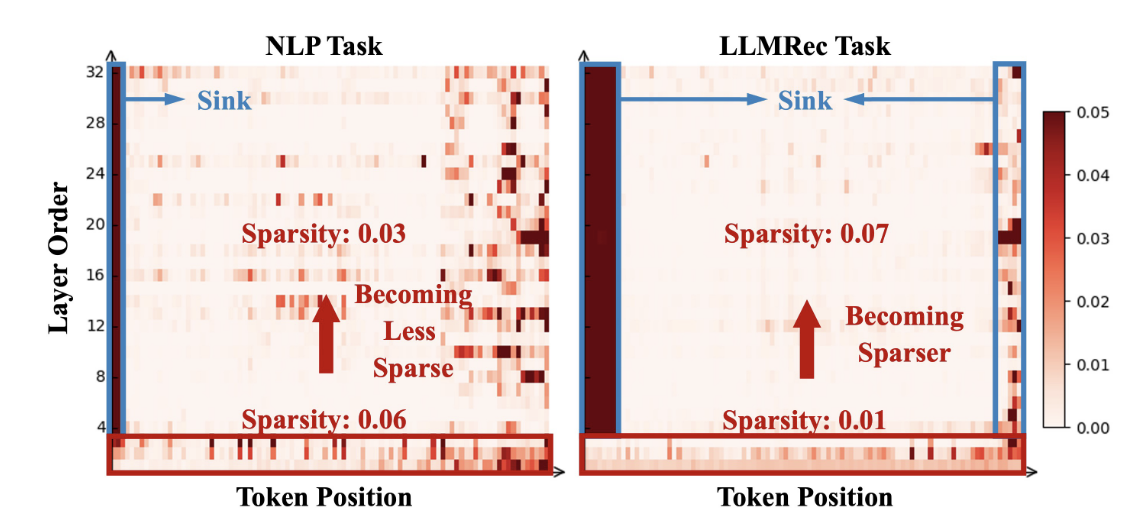
- LLM 的 attention sink${}^{\text{[2]}}$ 已经被很多人注意到, 作者在 LLMRec 任务上发现了一些特别的现象:
| Layer Order | Token Position | |
|---|---|---|
| NLP | Layer$\uparrow$ $\longrightarrow$ Less Sparse | head attention sink |
| LLMRec | Layer$\uparrow$ $\longrightarrow$ Sparser | head & tail attention sink |
相较于 NLP 的任务, LLMRec 随着层数的加深, attention 越发稀疏 (即更加集中), 而且主要集中在头部和尾部的 tokens 之上.
Head attention sink 是相对正常的, 因为这是 LLM 都有的特点, 而 Tail attention sink 可能是源自于: 1) 序列推荐尾部的更具价值导致的; 2) LLMRec 的尾部 token 能够凝聚之前的信息.
方法
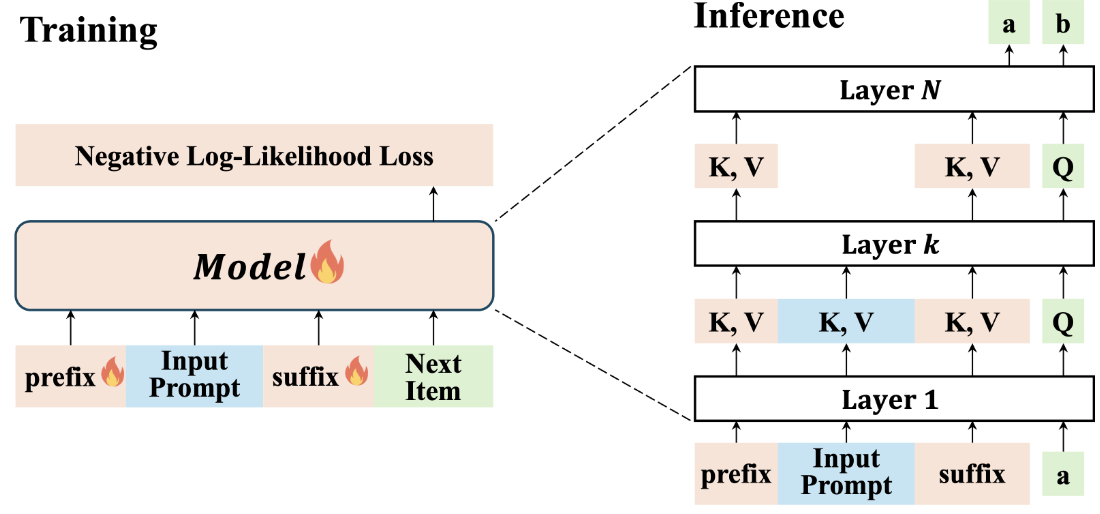
- 鉴于上面的发现, 本文提出了 EARN:
- Training: 引入额外的 prefix 和 suffix tokens, 即希望这两部分 tokens 能够和之前的发现一样, 大部分 attention 能够 sink 在这两部分之上.
- Inference: 既然随着层数的加深, head/tail sink 的现象逐渐加剧, 后面的层即使只用 prefix & suffix tokens 也不会造成太多的信息的损失. 因此, 只在前 k 层正常 inference, 后面 k 层舍弃掉 input prompt 对应的部分以加速整体的 inference.
参考文献
- Yang C., Lin X., Wang W., Li Y., Sun T., Han X. and Chua T. EARN: Efficient Inference Acceleration for LLM-based Generative Recommendation by Register Tokens. KDD, 2025. [PDF] [Code]
- Barbero F., Arroyo A., Gu X., Perivolaropoulos C., Bronstein M., Velickovic, P. and Pascanu R. Why Do LLMs Attend to the First Token? arXiv, 2025. [PDF] [Code]