Understanding Embedding Scaling in Collaborative Filtering
预备知识
(Collaborative Filtering) 协同过滤主要是估计 User-Item 的相关性分数, 然后用于后续的预测. 一般来说, 协同过滤方法都比较简单, (User/Item) 的 Embedding 往往占据了最多的参数量.
(Embedding Scaling) 由于一般的推荐模型都比较简单, 所以推荐的 Scaling 有不少是直接 Scaling Embedding 的. 然而现实情况是往往直接 Scaling Embedding 往往不会直接带来效果的提升. 例如, 在 [1] 中, 作者观察到在 scaling up 的过程中, 会出现明显的 embedding 坍缩问题 (绝大部分 energy 集中在部分维度上).
核心思想
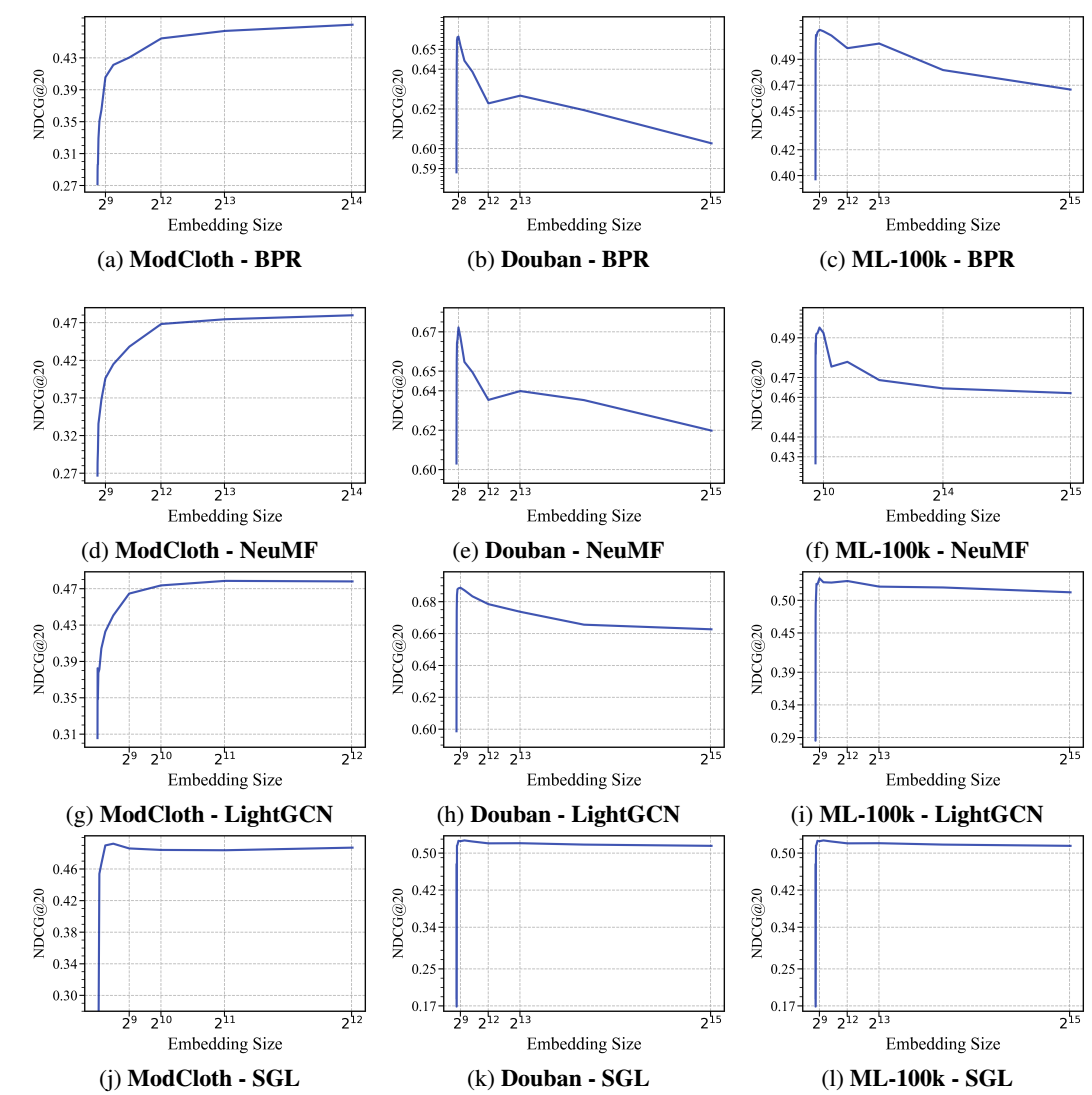
(经验观察) 上图, 作者拿 BPR, NeuMF, LightGCN, SGL 在 ModCloth, Douban, ML-100K 三个数据集上进行了测试:
- 在 ModCloth 数据集上, 基本上随着维度增加, 效果都能有一定程度的增加 (虽然逐渐变缓), 呈现 logarithmic 的曲线变化.
- BPR, NeuMF 这两个模型, 在 Douban, ML-100K 出现了明显的 double-peak, 即一开始随着维度增加, 效果递增, 然后到达第一个峰后逐步下降, 接着会缓慢再增加一次, 最后一直呈现下降的趋势.
(猜想) 作者认为, 倘若整体的趋势是按照前文所说的那样, 随着维度增加先增加后降低, 那么可以简单套用 overfitting 来解释, 但是 double-peak 的出现一定有一些其他原因. 作者假设随着维度增加, 出现了四个阶段:
- Clean learning stage: 一开始增加维度直接增加模型拟合干净数据的能力, 因此体现出明显的效果提升;
- Noise memorization stage: 继续增加维度所带来的表达能力用于记忆噪声, 因此会观察到效果的下降;
- Sweet stage: 模型开始适应噪声, 因此继续增加维度可以一定程度上提高模型的鲁棒性;
- Overfitting stage: 此时模型已经过度拟合 training set 了.
注: 第三阶段的解释有点牵强.
因此决定出现 Logarithmic 还是 Double-peak 现象的因素有两个:
- 数据中所含的噪声的比例;
- 模型的鲁棒性.
(理论分析) 作者对 BPR, NeuMF, LightGCN, SGL 分别进行了分析, 下面是大致的结论:
- BPR 对于噪声的敏感程度和一个不受限制的梯度相关, 因此会有较差的鲁棒性;
- NeuMF 对于噪声的敏感性主要来自于串联的 MLP, 其导致的扰动上界是一个乘积的形式;
- LightGCN 的鲁棒性主要来自于图卷积的低秩特性;
- SGL 的鲁棒性除了图卷积的低秩特性, 还有隐含的 Embedding Space 约束.
注: 理论分析和猜想比较割裂, 而且假设有点不符合实际.