GraphLocator: Graph-guided Causal Reasoning for Issue Localization
预备知识
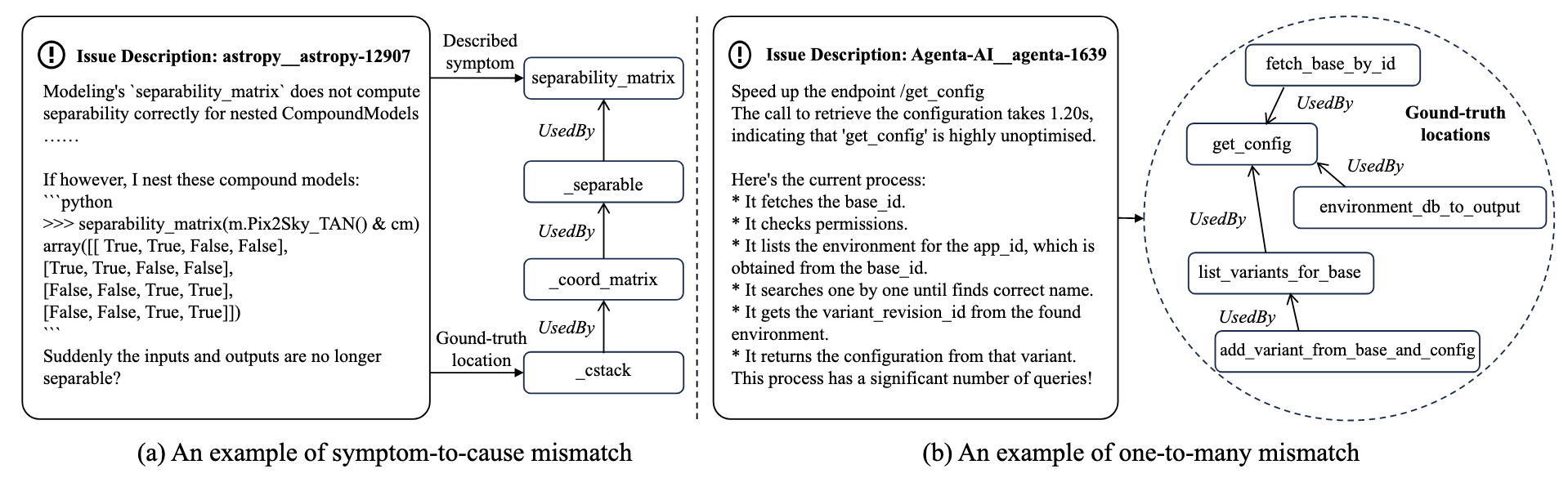
- (Issue Localization) 虽然 github 的仓库的 issues 通常包含相应的问题描述, 但这些描述与其所指向的具体代码块之间往往存在一定偏差, 进而与实际问题的根因不完全一致, 主要体现在以下两个方面: (1) symptom–to-cause mismatches: issue 中所陈述的表层现象与真实的根本原因之间可能存在显著距离, 往往需要经过多步依赖关系追溯或跨模块分析才能定位问题本源; (2) one-to-many mismatches: 在部分情形下, 单一 issue 的修复并非对应于某一个独立的 method/function, 而是需要同时对多个相关的 method/function 块进行协同修改。
核心思想
代码结构化: RDFS
GraphLocator 首先将代码结构化, 形成 “repository dependency fractal structure (RDFS)”, 记作 $\mathcal{R} = (V, E, T, C, type, code, layer)$:
- $V$ 是代码库中的元素集合;
- $E \subset V \times T_E \times V$ 是节点间的边的集合;
- $T = T_V \cup T_E$ 是节点和边的类型集合: $T_V = \{dir, pkg, file, class, interface, enum, field, method, function, global\_var\}$; $T_E = \{UsedBy, ImportedBy, ExtendedBy, ImplementedBy, HasMember\}$;
- $C$ 是代码片段集合, 每个元素节点均附带一个代码片段;
- type: $(V \rightarrow T_V) \cup (E \rightarrow T_E)$ 表示将节点和边映射至对应类型的函数集合;
- code: $V \rightarrow C$ 表示将元素节点映射至对应代码片段的函数;
- layer: $T_V \rightarrow \{1, 2, \ldots, L\}$ 表示将节点映射至层次的函数.
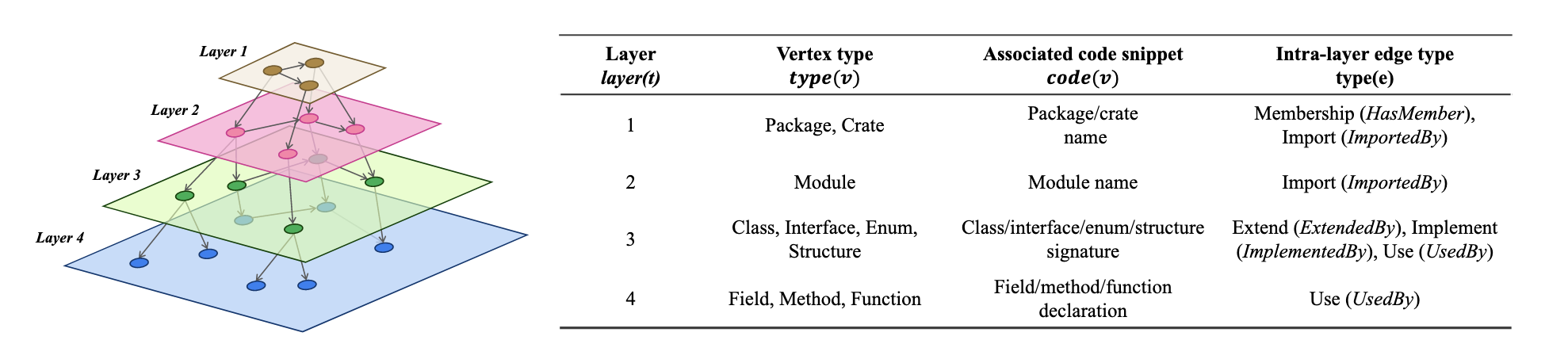
- 上图展示了 4 层的 RDFS, 覆盖从顶层的 package 到底层的方法层面.
Causal Issue Graph (CIG)
- GraphLocator 主张单个问题描述难以准确指向问题根因以及相关配套修改, 因此需要在 RDFS 的基础上迭代更新出 Causal Issue Graph $\mathcal{G} = (I, R) = (\mathcal{X}, \mathcal{Y}, \mathcal{R}, \phi, \psi)$:
- $\mathcal{X}$ 表示通过自然语言描述的 sub-issue 集合;
- $\mathcal{Y} \subset \mathcal{X} \times \mathcal{X}$ 表示 sub-issues 间的因果关系;
- $\mathcal{R}$ 表示代码库所形成的 RDFS;
- $\phi: \mathcal{X} \rightarrow 2^{V}$ 为将 sub-issue 映射至 $\mathcal{R}$ 中对应元素节点的函数;
- $\psi: \mathcal{Y} \rightarrow [0, 1]$ 表示 sub-issue 诱导 sub-issue 的条件概率.
GraphLocator
- 在 RDFS 和 CIG 的基本概念上, 需要探讨如何在给定代码库的基础上形成具体的 RDFS 和 CIG, 并由此进一步定位 issue.
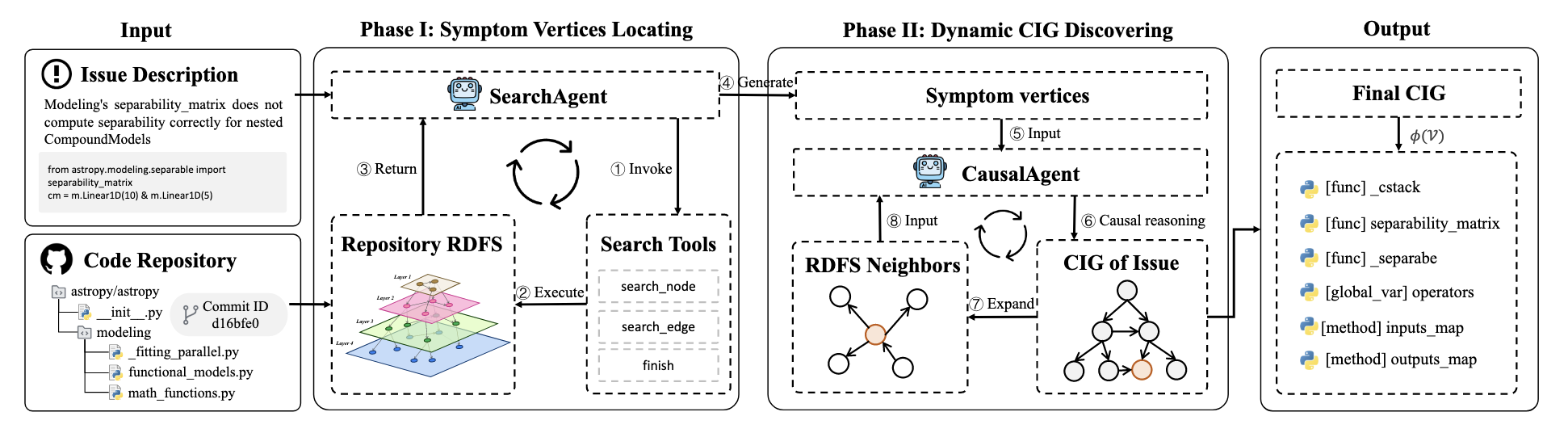
如上图所示, 总得来说, 在 RDFS 的基础上通过 SearchAgent 形成原始 issue 的关联节点, 并在基础上逐步形成 sub-issue 以及相应的关联节点.
(RDFS) RDFS 的生成是 issue-无关的, 通过 tree-sitter 可以快速实现.
(Symptom Vertices Locating) GraphLocator 通过 SearchAgent 在图上 (RDFS) 搜索和原始 issue 相关的元素节点, SearchAgent 所依赖的工具如下:

- (Dynamic CIG Discovering) 接着, GraphLocator 利用 CausalAgent 逐步扩展 CIG, 其大致流程如下:
计算 sub-issue 对其他 sub-issue 的综合影响力:
$$ \Psi(x) = 1 - \prod_{(x, y) \in \mathcal{Y}} (1 - \psi(x, y)). $$选择综合影响力最大的 sub-issue, 找到 RDFS 中和 sub-issue 相关元素节点的邻居 $\mathcal{O}^t$;
在此基础上 ($I, \mathcal{G}^{t-1}, x, \mathcal{O}^t$) 利用 CausalAgent 形成新的 sub-issue, 得到 $\mathcal{G}^t$.
注: CausalAgent 在处理 $\mathcal{G}^{t-1}$ 的时候采用 Mermaid format 进行序列化, 个人认为这种方式确实比较适配 LLM.
评价指标
本文主要关注在 file, module, function 三个层次的定位准确性, 对于每个层次均考虑如下四个指标:
Success Location:
$$ SL = \frac{1}{|\mathcal{I}|} \sum_{i \in \mathcal{I}} \mathbb{I}[L_i \subset L_i']. $$Recall:
$$ Rec = \frac{1}{|\mathcal{I}|} \sum_{i \in \mathcal{I}} \frac{|L_i \cap L_i'|}{|L_i|}. $$Precision:
$$ PRE = \frac{1}{|\mathcal{I}|} \sum_{i \in \mathcal{I}} \frac{|L_i \cap L_i'|}{|L_i'|}. $$F1-Score:
$$ F1 = \frac{1}{|\mathcal{I}|} \sum_{i \in \mathcal{I}} \frac{2 \cdot |L_i \cap L_i'|}{|L_i| + |L_i'|}. $$
这里 $\mathcal{I}$ 表示 issues 集合, $L_i$ 表示 ground-truth locations, $L_i'$ 则是预测结果. 显然, SL, Recall 主要关注能否"定位全", PRE 主要关注能否"定位准", F1 则是二者兼顾.