Generative Recommendation with Semantic IDs: A Practitioner’s Handbook
预备知识
- (Generative Recommendation) 生成式推荐目前主要分为三个阶段:
- Semantic Features: 通过预训练好的 Encoder 将一些多媒体信息 (通常是文本) 提取为 semantic features.
- Semantic ID, SID: 通过 Residual KMeans 或者 RQ-VAE 将上述得到的 Semantic Features 编码为 Item 对应的离散编码, 如 $(c^{(1)}, c^{(2)}, c^{(3)})) \in \mathbb{Z}_+^3$.
- 得到的 SID 用于训练生成式模型, 推理的时候一般使用 Beam Search 实现.
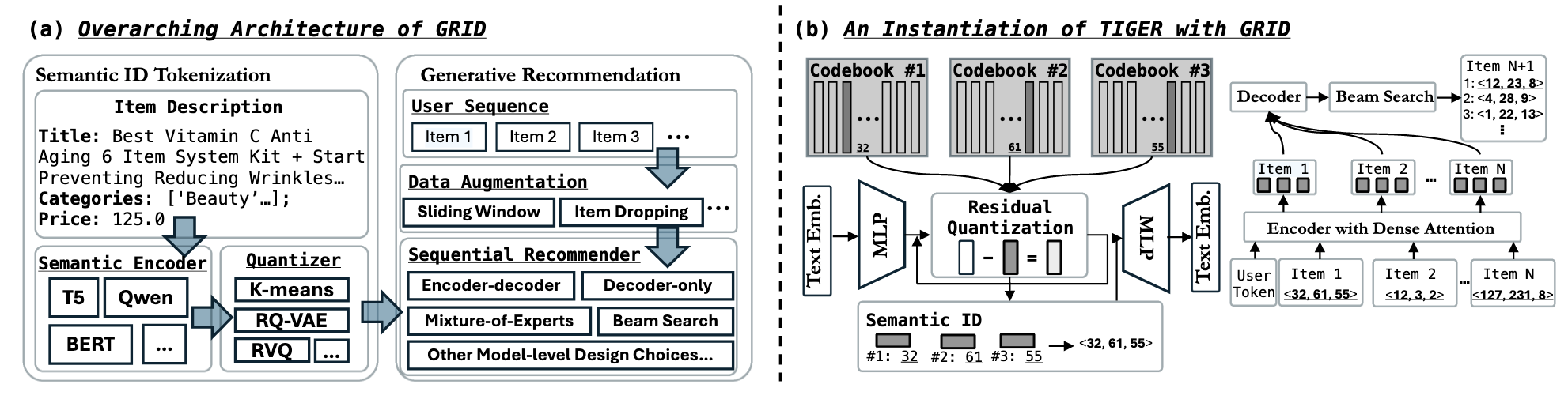
- (Bag of Tricks) 在生成式推荐中涉及到如下的几个 Tricks:
- Semantic Encoder: 一般来说, 编码模型越大越好;
- Quantizer: 采用 Residual KMeans, RQ-VAE 或者其他, 这直接影响了 SID 的生成质量;
- Codebook Size: Codebook Size 包含 (i) codebook 的数量 $L$; (ii) 每个 codebook 包含的词表大小 $M$;
- 生成式推荐的 Backbone: 过往的方法往往采用 Flan-T5 (Encoder-Decoder) 作为推荐模型的 backbone, 另一种是现在比较流行 Decoder-only 的方案;
- User Token: 在 TIGER 中, T5 的 encoder 除了接收 Item 的 SID 历史序列外, 还有一个 User Token (特别地是, 该 token 通过将 user 随机 hash 得到, 因此有些 user 会共享一个 user Token);
- SID de-duplication: SID 往往会存在一定的冲突, 即不同 Item 可能具有同一个 SID. 此时就有两种方式解决这个问题: (i) [TIGER] 建议在原本的 SID 外额外添加一个 token 以避免冲突; (ii) 选到同一个 SID 后随机选择一个 Item;
- Beam Search: Beam search 是选择多个候选商品的通用策略, 这里有两种选择: (i) 受限搜索, 即要求每次生成的 SID 都是有效的; (ii) 自由搜索, 无所谓有效不有效.
核心思想
- 本文是一篇实现性文章, 对上述的 Tricks 进行了实验验证.

- Semantic Encoder: 如上图所示, 随着 language encoders 逐步增大规模, 效果的增加是极其微弱的.

- Quantizer: 虽然 RQ-VAE 在生成式推荐中最为常用, Residual Kmeans 的实际效果是最好的.
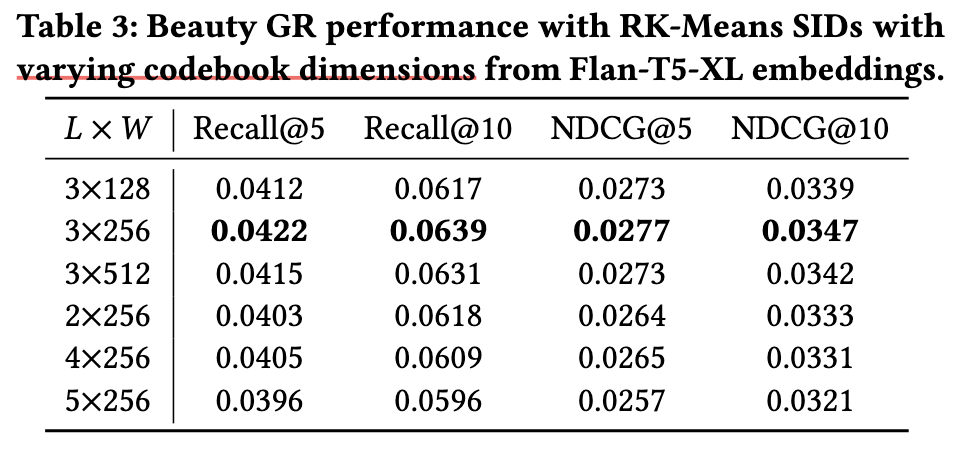
- Codebook Size: 默认的 (3x256) 效果的确是最好的, 而且随着 size 的增加, 效果明显变差 (特别的 codebook 的数量).
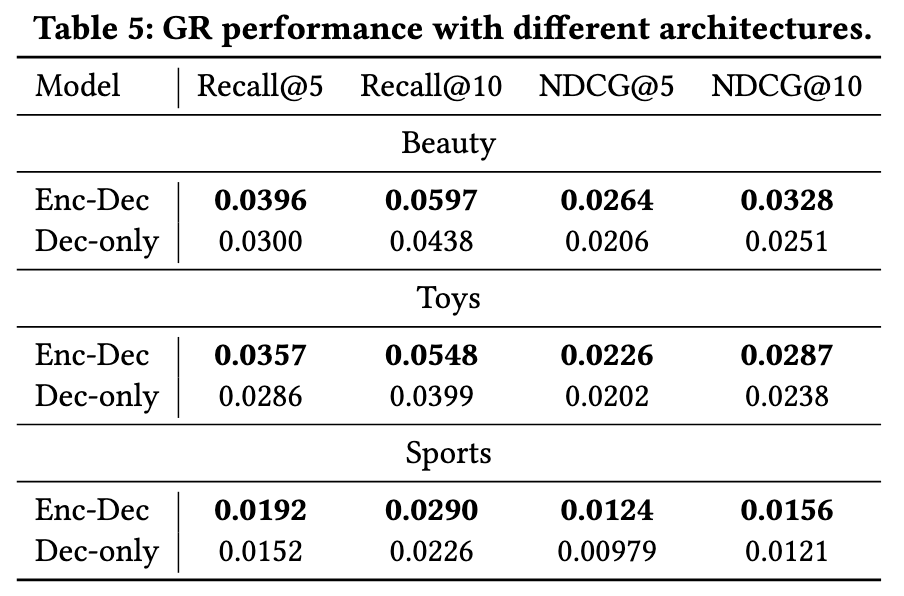
- 生成式推荐的 Backbone: 显然 Encoder-Decoder 的效果比起 Decoder-only 的效果要明显好, 这解释了为什么之前的方法都优先采用 T5.
注: 我大概知道为什么 Decoder-only 效果这么差, 就我个人的实验, Decoder-only 的 Output projector 共享 Input Embedding 的时候, 效果贼差, 但是采用和 Encoder-Decoder 类似独立的 Output projector 的时候, 效果就恢复了.
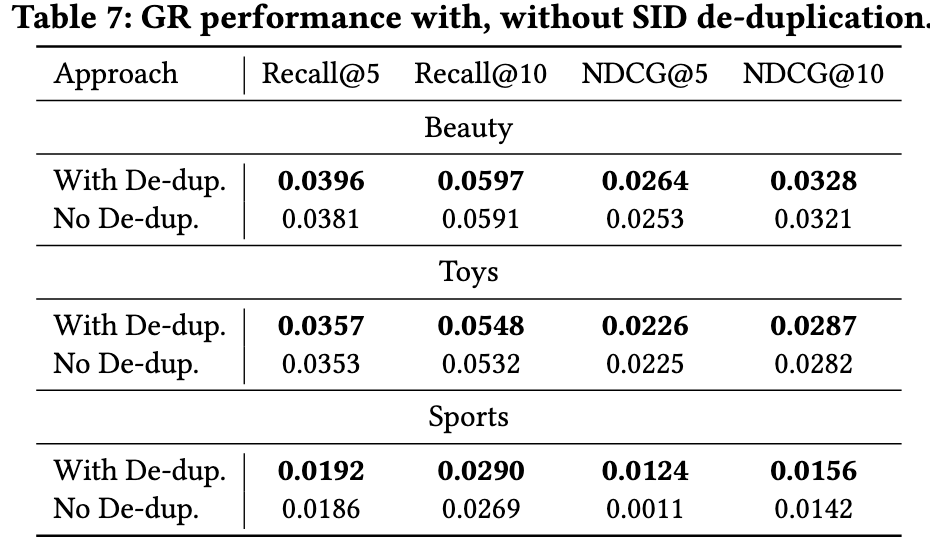
- SID de-duplication: 和我个人的实验结果一样, 只要层数够多, 生成式推荐的结果几乎能够保证都是有效的 SID.
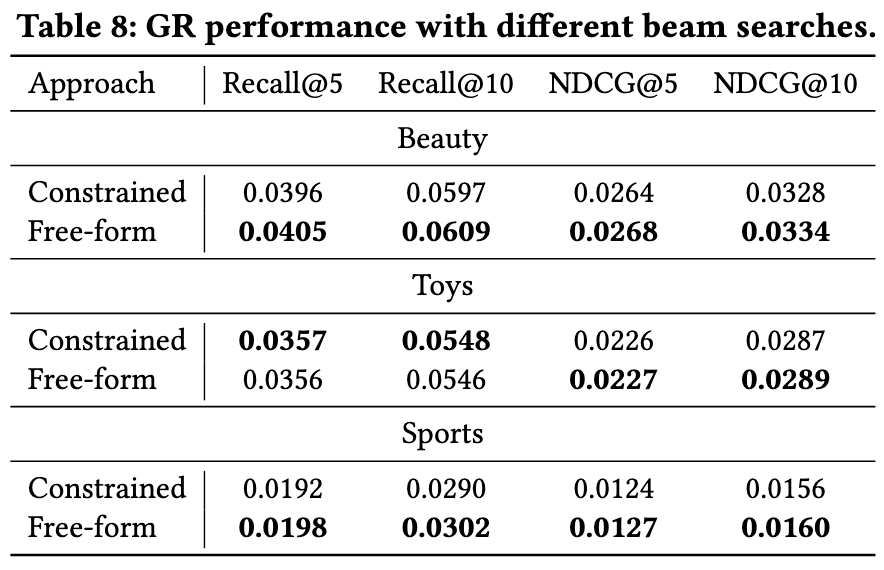
- Beam Search: 既然 SID 基本上都是有效的, 自然受不受限差别就不大了.