DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
预备知识
- 利用 PPO 进行强化学习训练需要配置一个和策略模型同等规模的 value function, 这会导致训练的成本和难度大大上升.
核心思想
对于 query $q$, LLM policy model 输出 response $o$ (一串序列), 则 PPO 的优化目标为:
$$ \mathcal{J}_{PPO}(\theta) =\underset{q \sim P, o \sim \pi_{\theta_{old}}(\cdot | q)}{\mathbb{E}} \left[ \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left\{ \frac{ \pi_{\theta}(o_t| q, o_{\lt t}) }{ \pi_{\theta_{old}}(o_t|q, o_{\lt t}) } A_t, \text{clip} \left( 1 - \epsilon, 1 + \epsilon \right) A_t \right\} \right]. $$这里 $\pi_{\theta}$ 和 $\pi_{\theta_{old}}$ 代表当前和旧的策略模型, $\epsilon$ 是为了稳定训练的超参数.
注: 可以认为, LLM policy model 输出每个 token 就是做一次 action, 因此链路为:
$$ q \xrightarrow{\text{action}} o_1 \xrightarrow{\text{update}} (q, o_1) \xrightarrow{\text{action}} o_2 \xrightarrow{\text{update}} (q, o_1, o_2) \rightarrow \cdots $$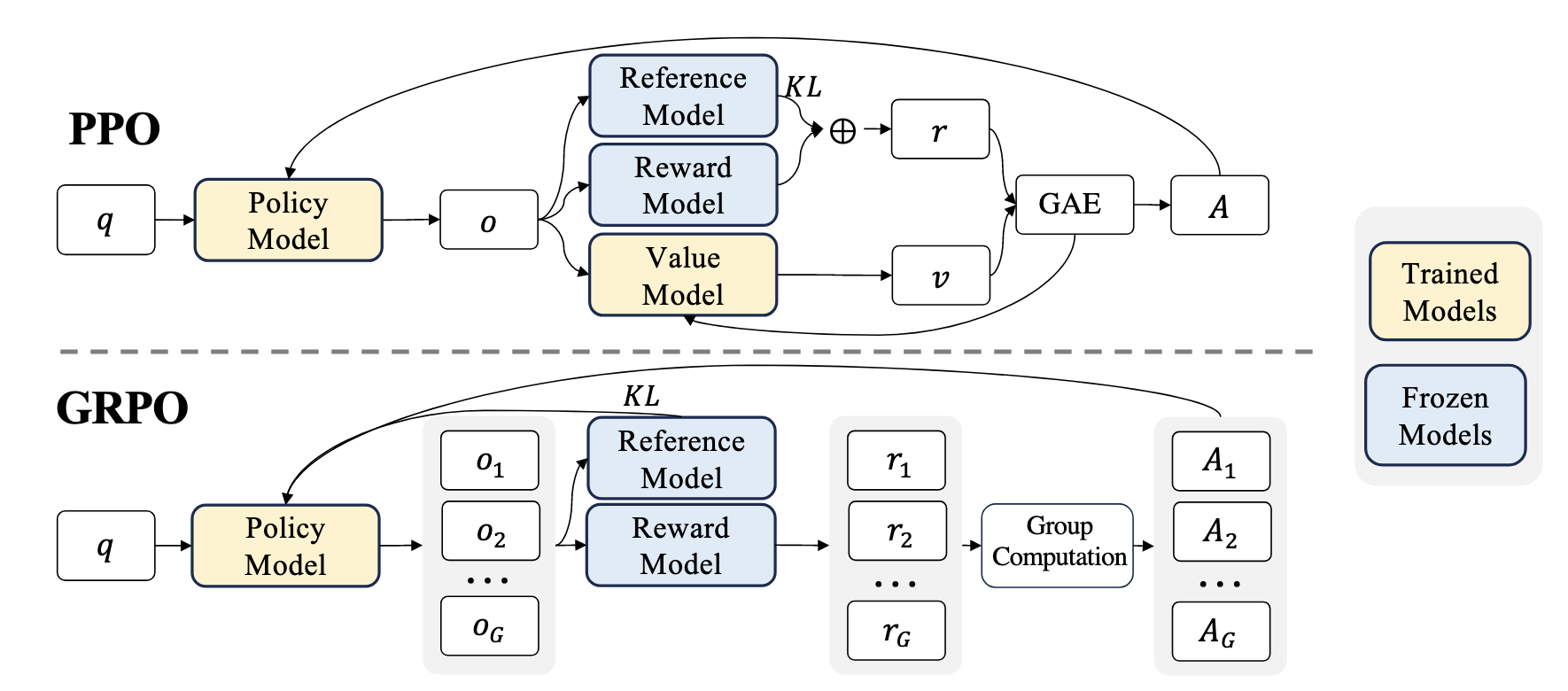
(GRPO) 为了避免利用额外的价值函数来估计 $A_t$, GRPO 提出通过在 query $q$ 的基础上, 采样 $G$ 个输出 $\{o_i\}_{i=1}^G$, 并利用其上的 reward 来估计 $\hat{A}_{i, t}$, 得到如下的优化目标:
$$ \mathcal{J}_{GRPO}(\theta) =\underset{q\sim P, \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(\cdot | q)}{\mathbb{E}} \left [ \frac{1}{G}\sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left\{ \frac{\pi_{\theta}(o_{i, t}| q, o_{i,\lt t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i, \lt t})} \hat{A}_{i, t}, \text{clip}\left( 1 - \epsilon, 1 + \epsilon \right) \hat{A}_{i, t} \right\} - \beta \mathbb{D}_{KL}(\pi_{\theta} \| \pi_{ref}) \right]. $$这里引入了额外的 KL 散度用于约束 $\pi_{\theta}$ 的更新, 特别地, 通过如下方式近似计算 (请参考 John Schulman-Approximating KL Divergence):
$$ \mathbb{D}_{KL}(q\|p) \approx \frac{p}{q} - \log \frac{p}{q} - 1. $$(Outcome Supervision) 倘若对于整个输出 $o$ 仅有一个 reward $r$, 则对于 $G$ 个采样有
$$ \mathbf{r} = \{r_1, r_2, \ldots, r_G\}, $$在此基础上通过如下方式估计:
$$ \hat{A}_{i, t} = \tilde{r}_t = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}. $$注意到, 对于输出的不同 token $o_{i, t}$, 是应用的相同的 $\hat{A}_{i, t} = \tilde{r}_t$.
(Process Supervision) 假设在整个 $o$ 上有多个 reward:
$$ \mathbf{R} = \{ \{r_1^{index(1)}, \ldots, r_{K_1}^{index(K_1)}\}, \ldots, \{r_G^{index(1)}, \ldots, r_{K_G}^{index(K_G)}\} \} $$这里 $index(j)$ 表示能获取到 reward 的 token 的序. 此时, 可以通过如下方式估计:
$$ \hat{A}_{i, t} = \sum_{index(j) \ge t} \tilde{r}_i^{index(j)}, \\ \tilde{r}_i^{index(j)} = \frac{ r_i^{index(j)} - \text{mean}(\mathbf{R}) }{ \text{std}(\mathbf{R}) }. $$
注: $r_i - \text{mean}(\mathbf{r})$ 的操作相对来说是比较好理解的, 因为 $r_i$ 类似 $Q(s, a)$, $\text{mean}(\mathbf{r})$ 类似 $V(s)$.
疑问: 为什么 process supervision 的过程中不添加折扣因子?