HiD-VAE: Interpretable Generative Recommendation via Hierarchical and Disentangled Semantic IDs
Content
研究背景
-
(Generative Recommendation) 传统推荐系统遵循 “retrieve-then-rank” 两阶段范式: 先召回候选集, 再打分排序. 近期的 generative recommendation (TIGER, LC-Rec) 将这一流程统一为端到端的自回归生成: 模型直接生成商品的 Semantic ID, 不再依赖外部 ANN 检索.
-
(Semantic ID 的质量瓶颈) 生成式推荐的性能高度依赖 Semantic ID 的质量. 现有方法 (RQ-VAE / PQ) 在无监督条件下学习离散编码, 存在两个根本性问题:
- 语义扁平 (semantically flat): 学习到的层级结构是量化过程的隐式副产物, 缺乏显式语义对齐, ID 不可解释;
- 表示纠缠 (representation entanglement): 不同商品可能被映射到相同的 ID, 即 “ID collision”, 损害推荐的准确性与多样性.
-
(现有方案的不足) TIGER 等工作的解决方式是 post-hoc: 对碰撞 ID 追加一个自增整数来区分不同商品. 这种做法破坏了 ID 的语义完整性, 属于治标不治本.
-
(符号说明)
- 商品特征: $\mathbf{x} \in \mathbb{R}^{d_{\text{in}}}$;
- 语义 ID: $\mathbf{y}_i = (y^{(1)}_i, y^{(2)}_i, \ldots, y^{(L)}_i)$, 其中 $y^{(l)}_i$ 是第 $l$ 层 codebook 的索引;
- 层级标签: $\{c^{(l)}\}_{l=1}^L$, 对应的标签 embedding 为 $\{\mathbf{t}^{(l)}\}_{l=1}^L$.
核心思想
整体框架
HiD-VAE 采用两阶段设计: Stage 1 离线学习层次化解耦的 item tokenizer; Stage 2 基于冻结的 tokenizer 训练序列推荐模型.
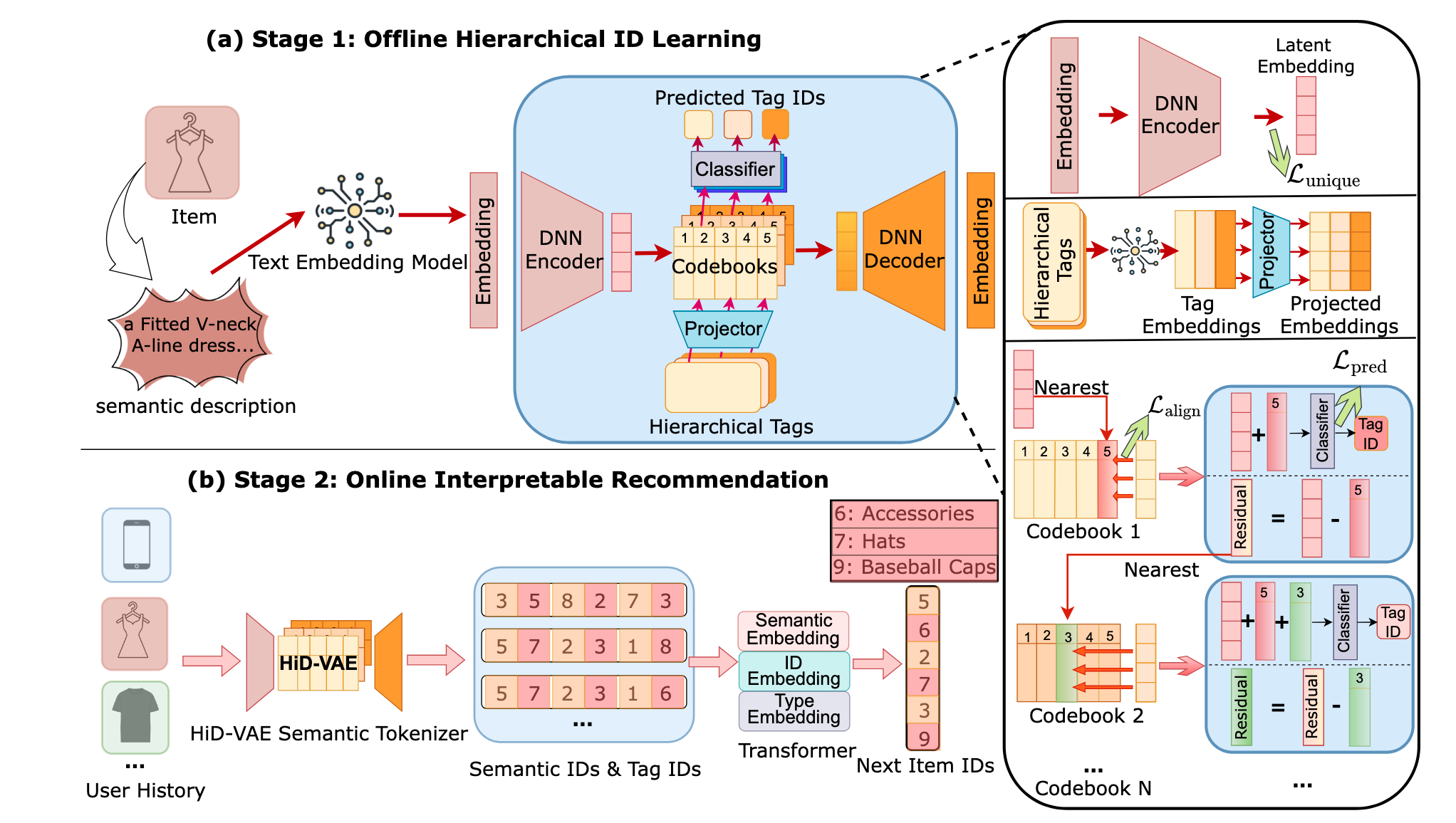
Stage 1: 层次化与解耦的语义 ID 学习
-
(RQ-VAE 骨架) 采用 $L$ 层残差量化器. 给定编码器输出 $\mathbf{z}_0 = E(\mathbf{x})$, 第 $l$ 层量化器选择最近码字 $\mathbf{e}^{(l)} = q_l(\mathbf{r}_{l-1})$, 残差更新为 $\mathbf{r}_l = \mathbf{r}_{l-1} - \mathbf{e}^{(l)}$. 累积量化嵌入为 $\mathbf{z}^{(l)}_q = \sum_{j=1}^l \mathbf{e}^{(j)}$.
-
(层次化监督量化) 这是 HiD-VAE 的第一个核心创新, 通过两个损失函数将每层 codebook 显式对齐到对应层级的类别标签:
-
Tag Alignment Loss (对比对齐): 将 ground-truth 标签嵌入 $\mathbf{t}^{(l)}$ 通过投影器 $P_l$ 映射到商品潜在空间, 用对比损失拉近累积量化嵌入 $\mathbf{z}^{(l)}_q$ 与对应标签投影的距离:
$$ \mathcal{L}^{(l)}_{\text{align}} = -\log \frac{\exp(\text{sim}(\mathbf{z}^{(l)}_q, P_l(\mathbf{t}^{(l)})) / \tau)}{\sum_{j=1}^B \exp(\text{sim}(\mathbf{z}^{(l)}_q, P_l(\mathbf{t}^{(l)}_j)) / \tau)}. $$ -
Tag Prediction Loss (分类预测): 每层配备独立的分类器 $C_l$, 根据累积嵌入预测该层标签:
$$ \mathcal{L}^{(l)}_{\text{pred}} = \text{CrossEntropy}(C_l(\mathbf{z}^{(l)}_q), c^{(l)}). $$分类器容量随层级加深而增大 (更大的隐层维度、更高的 dropout), 以适应细粒度标签类别多、预测难度大的特点.
-
-
(Uniqueness Loss 解耦机制) 这是 HiD-VAE 的第二个核心创新. 对于同一 batch 内 ID 碰撞的不同商品对 $(i, j)$, 直接惩罚其编码器输出 $\mathbf{z}_{0,i}$ 与 $\mathbf{z}_{0,j}$ 的余弦相似度:
$$ \mathcal{L}_{\text{unique}} = \frac{1}{|\mathcal{P}|} \sum_{(i,j) \in \mathcal{P}} \max\left(0, \frac{\mathbf{z}_{0,i} \cdot \mathbf{z}_{0,j}}{\|\mathbf{z}_{0,i}\|_2 \|\mathbf{z}_{0,j}\|_2} - m\right), $$其中 $\mathcal{P}$ 为 batch 内所有 ID 碰撞的不同商品对, $m$ 为 margin 超参数. 该损失在量化前就强制不同商品的表示相互推开, 从根源上减少 ID collision.
-
(完整训练目标)
$$ \mathcal{L}_{\text{HiD-VAE}} = \mathcal{L}_{\text{recon}} + \beta_{\text{commit}} \mathcal{L}_{\text{commit}} + \beta_{\text{sup}} \sum_{l=1}^L (\mathcal{L}^{(l)}_{\text{align}} + \mathcal{L}^{(l)}_{\text{pred}}) + \beta_{\text{unique}} \mathcal{L}_{\text{unique}}. $$
层级标签生成 (可选 Stage 0)
对于缺少天然层级标签的数据集 (如 KuaiRand), HiD-VAE 提供了一套 LLM-based 的 “retrieval-then-classification” 流程:
- 候选检索: 用预训练句子编码器将商品文本和候选标签编码为向量, 通过 ANN 检索每层 top-K 候选标签;
- LLM 分类: 以商品内容、上级标签和候选集为 prompt, 让 LLM 从候选中选出最合适的标签.
该流程保证生成的标签始终来自预定义候选集, 避免了 LLM 幻觉问题.
Stage 2: 可解释的生成式推荐
-
(Hierarchy-Aware Semantic Embeddings) 将语义 ID 的每个 token 映射为 tag 文本, 用预训练模型编码为语义向量, 再与可学习的 ID embedding 和层级 type embedding 拼接. 这使得模型能感知从粗到细的语义路径.
-
(Constrained Decoding) 推理时构建合法 ID 前缀树, 动态 mask 无效 token, 保证生成的 ID 始终对应真实商品.
关键洞察
-
(ID Collision Rate 从 ~22% 降至 ~2%) 全量 HiD-VAE 将 ID collision rate 从 RQ-VAE 的 18.7% 降至 2.1% (Beauty 数据集). 值得注意的是, 去掉层次化监督只保留 DUL 时碰撞率为 5.8%, 说明层次化监督虽不直接解耦, 但通过赋予潜在空间语义结构, 间接促进了表示的分离.
-
(量化层数的边际收益递减) $\mathbf{L}=3 \to 4$ 仅有微弱提升, $\mathbf{L}=4 \to 5$ 反而下降. 更深层级带来了更长的自回归序列和更大的量化误差累积, 性价比不高.
继往开来
- 提取 tag 的过程有一些繁琐, 不过
Sports上效果有点好.
参考文献
- Fang D., Gao J., Zhu C., Li Y., Zhao X. and Chang Y. HiD-VAE: Interpretable Generative Recommendation via Hierarchical and Disentangled Semantic IDs. arXiv, 2025. [PDF]