HLLM-Creator: Hierarchical LLM-based Personalized Creative Generation
预备知识
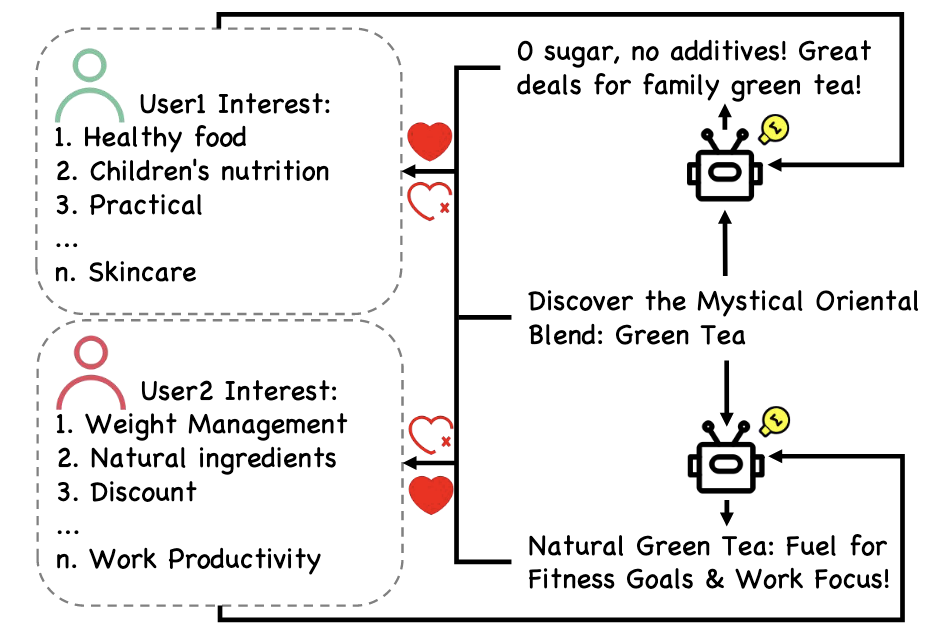
- (Personalized Creative Generation) 一般的广告推荐的核心就是将’固定’的广告推荐给其所感兴趣的用户, 从而增加收益. 生成式模型 (主要是 LLM, LVM 等) 的发展给这项任务带来了变革的契机. 要知道, 同一个广告, 以不同的方式呈现出来往往会有天翻地覆的变换, 本文希望实现的目标是"广告语/Title"的个性化: 为每个用户选择其可能感兴趣的广告, 并以一种’最’能吸引他的方式呈现. 如上图所示, 同一款绿茶:
- 从 User1 的交互序列中我们可以推断出他更注重健康, 因此我们在广告标题中强调 “0 糖 0 添加”.
- 从 User2 的交互序列中我们可以推断出她关注体重管理和工作效率, 因此在广告语中强调此款绿茶对于’健身目标’和’工作效率’的好处.
核心思想
个人认为"个性化广告语"的确是内容生产推荐的一条可落地的路子. 本文的技术创新主要集中在如何构建有效的数据训练 LLM 以及高效推理方面.
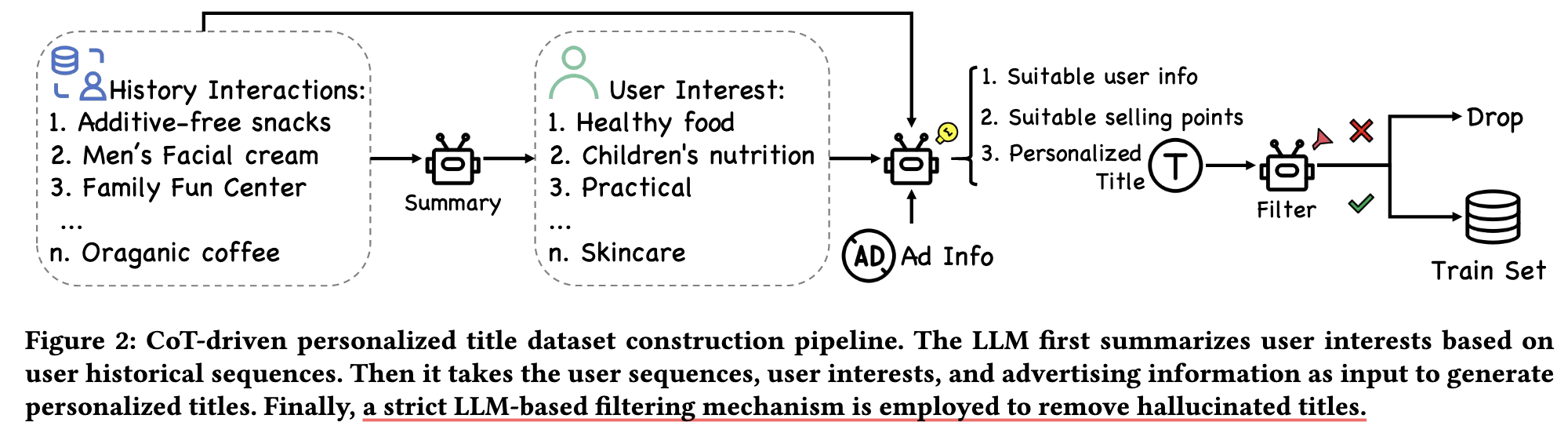
(CoT-driven Personalized Title Dataset Construction) 数据集的构建流程也全部是 LLM 完成的:
- 利用 LLM 根据 User 的交互历史总结兴趣点;
- 根据兴趣点生成个性化的广告语;
- 利用 LLM 过滤掉那些不符合事实的广告语.
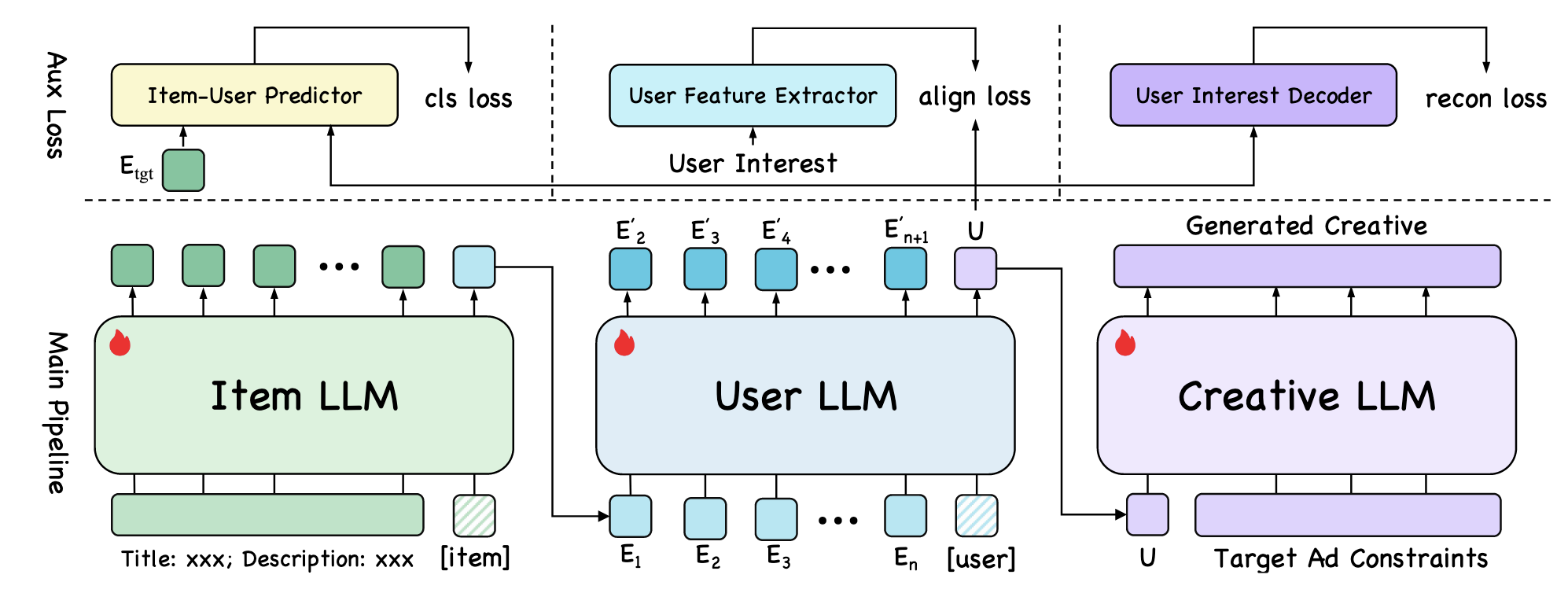
(HLLM-Creator) HLLM-Creator 分成三个阶段:
Item LLM for Item Representation: Item LLM 首先根据广告的标题和描述生成对应的表示. 注意到, 这里添加了一个额外的 [Item] Token, 广告的表示为此 Token 对应的输出.
User LLM for User Representation: 通过 User 的交互序列 (每个 Item 的表示由 Item LLM 得到), 得到用户的表示, 和上面类似, 表示由 [User] Token 得到.
Creative LLM: Creative LLM 以刚刚得到的 User 表示以及目标 Item 的 word tokens 为输入, 输出新的个性化的广告语. 似乎上面给的图有那么一点错误, 实际上广告语是接着最后一个 word token 序列生成的, 因为其训练目标是:
$$ -\frac{1}{L} \sum_{i=1}^L \log \left( p(r_i| U, \underbrace{f_1, f_2, \ldots, f_a}_{\text{target item}}, \underbrace{r_1, r_2, \ldots, r_{i-1}}_{\text{new title}}) \right). $$
除了正常的 Next-Token 预测, 作者还引入了 Recommendation Loss, Semantic Alignment Loss, Reconstruction Loss 来保证 User/Item 表示正确表示了兴趣和语义.
(Inference) 显然, 为每一个 User/Item 组合生成个性化广告语是不可能的. 因此, 在实际推理的时候, 首先将 User 聚类成一个一个 Group, 聚类中心作为 Group 的表示. 因此, 个性化广告只需要为每个 Group 生成即可.