Is Every Item Worth An Embedding?
黑暗源头
在大部分语言模型中, 并非每个词都有其对应的向量表示, 往往采用一些分词器来组合表示 (即一个词由拆成多个’词根’). 最近在这篇文章中 ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation 也提出了在推荐中的类似思想.
我的问题便是: 是否每个 Item 都值得一个独立的 Embedding 表示呢?
我目前的怀疑是:
- 那些接近冷启动的商品或许不值得一个独立的 Embedding 表示: 因为冷启动的商品更新频率很低, 很难想象这种情况下会能学到什么有用的东西.
- 最热门的商品或许也不一定值得一个独立的 Embedding: 和所有用户都交互或许反而就是和谁的没有交互.
因此:
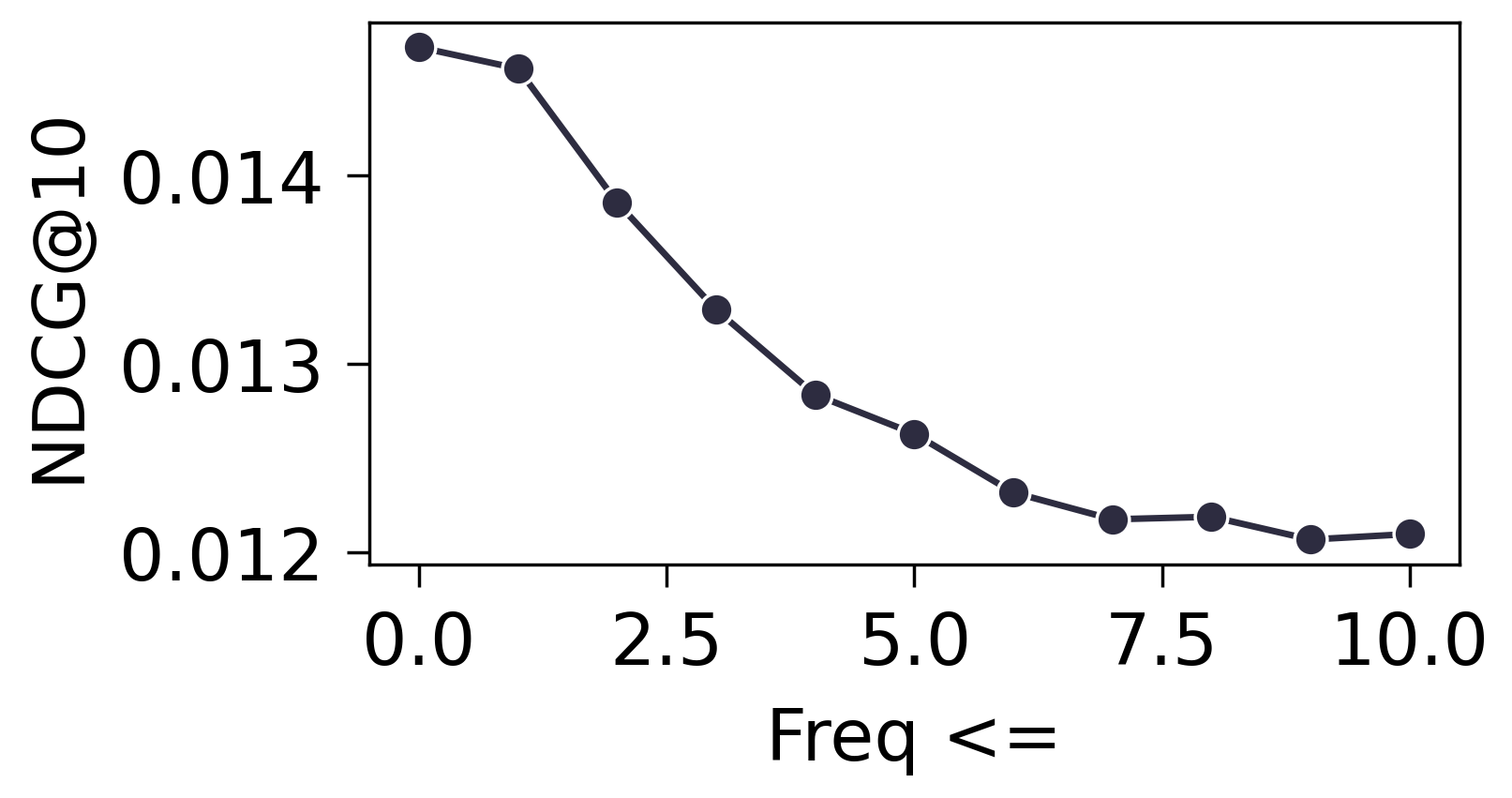
- 首先验证频率对于结果的影响, 是否会有比如说出现频率很低的商品被预测准确的概率会低.
- 部分商品是否可以不建立单独的可学习 Embedding, 而是利用其周围邻居的平均作为替代.
实验结果
频率的影响
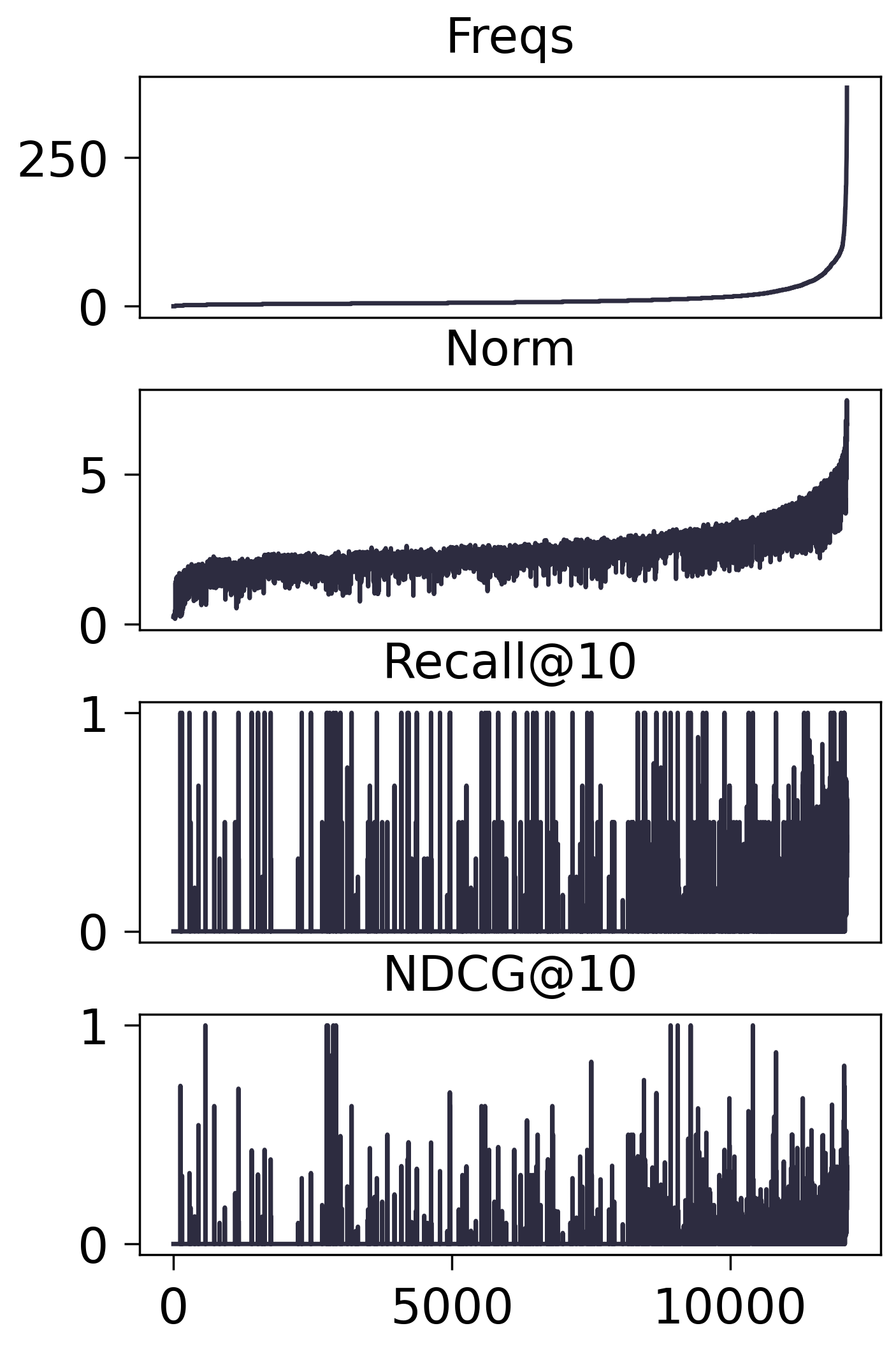
Amazon2014Beauty_550_LOU
- MF-BPR:
- SASRec:
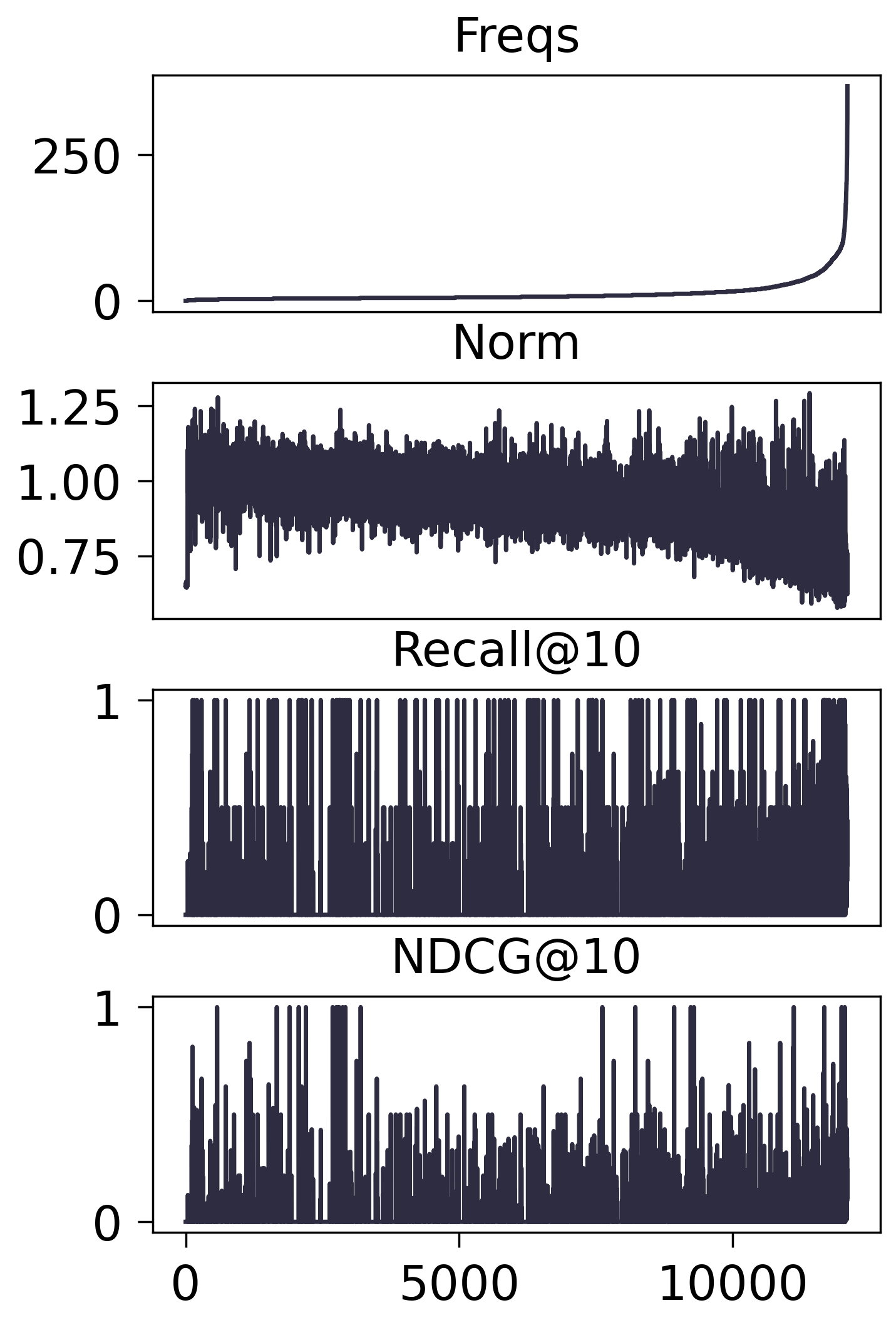
Amazon2014Beauty_1000_LOU
注: 有 9,282 个 items 从未出现在训练集中
- MF-BPR:
- SASRec:
Norm <= 0.6 的数量恰好是 9,282
Yelp2019_550_S3Rec
- MF-BPR:
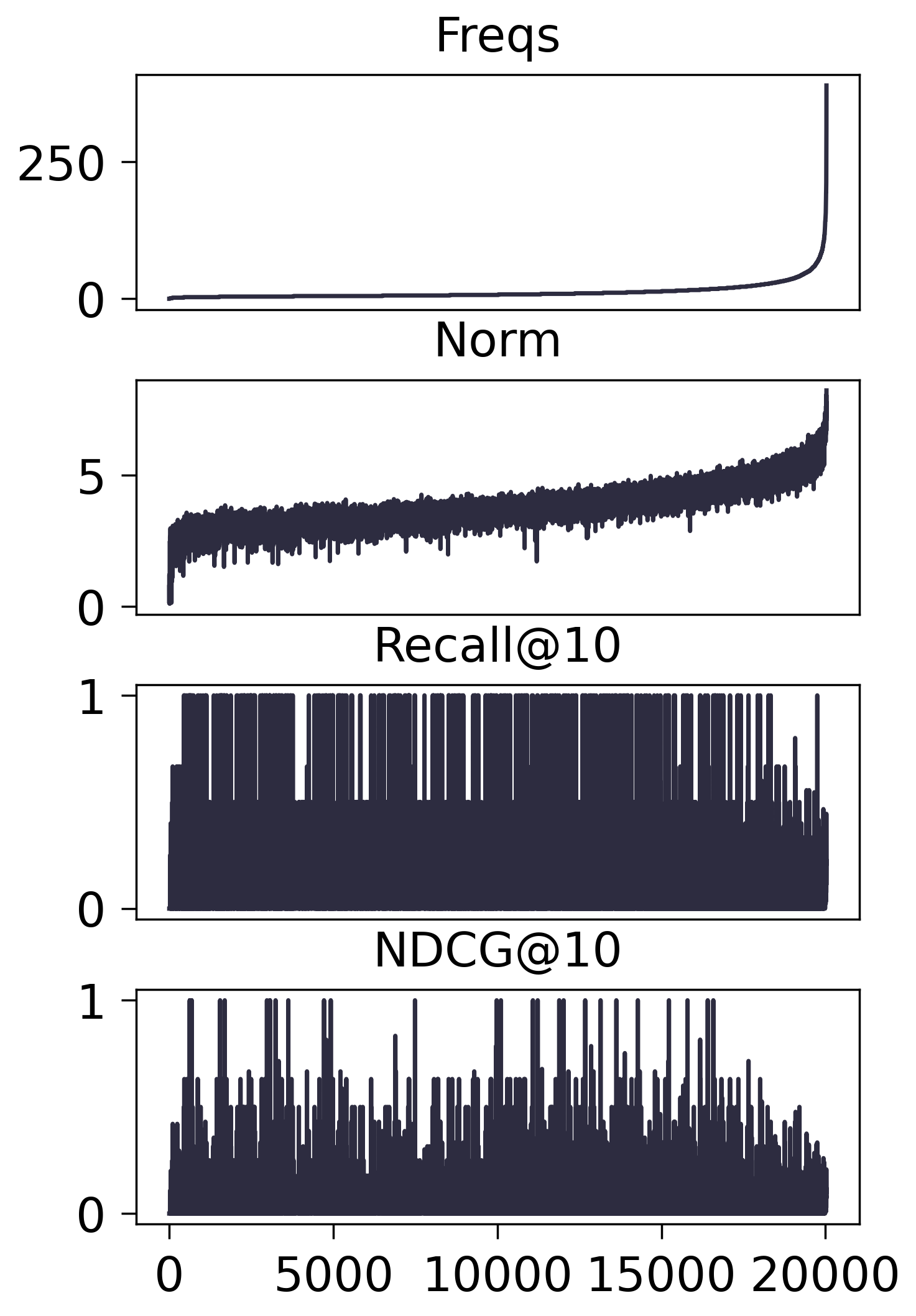
- SASRec:
对于传统的协同过滤模型, 的确有 频率高 $\rightarrow$ 模长大 的趋势, 但是在序列模型之上, 却并没有观察到这一点, 只要出现在训练集中的频率不怎么为 0, 就基本上会有相当的模长.
我一开始怀疑, 是不是因为 SASRec 的 user embedding 经过了 LayerNorm, 这导致对应的 Item embedding 没法吸收到有效的模长信号, 但是多番测试下, LayerNorm 对此没有丝毫影响.
舍弃部分 Embeddings
- 我们对一定频率内的商品的 Embedding 不做单独的 Embedding 训练, 而是利用其周围邻居的 Embedding 的平均.
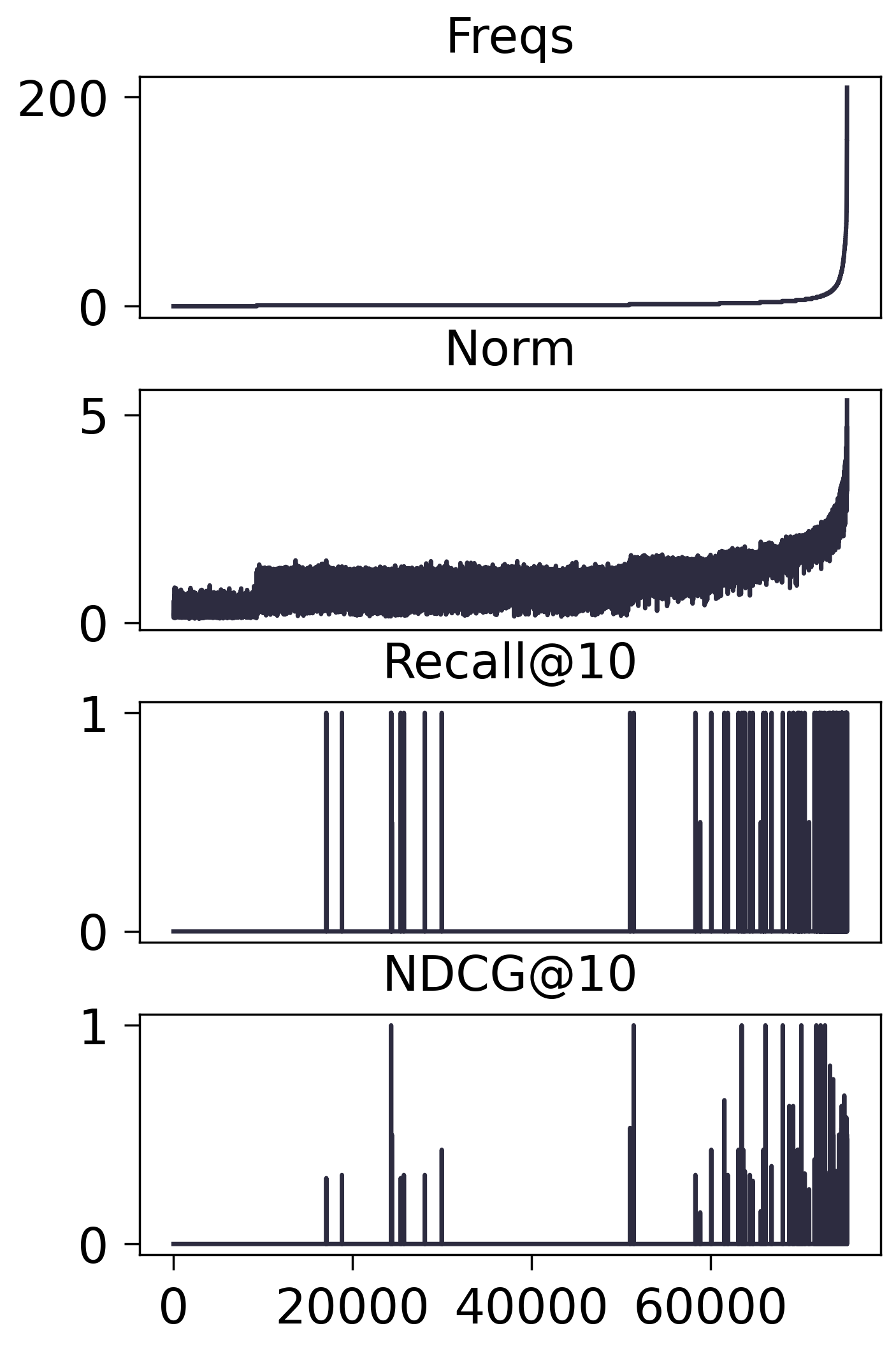
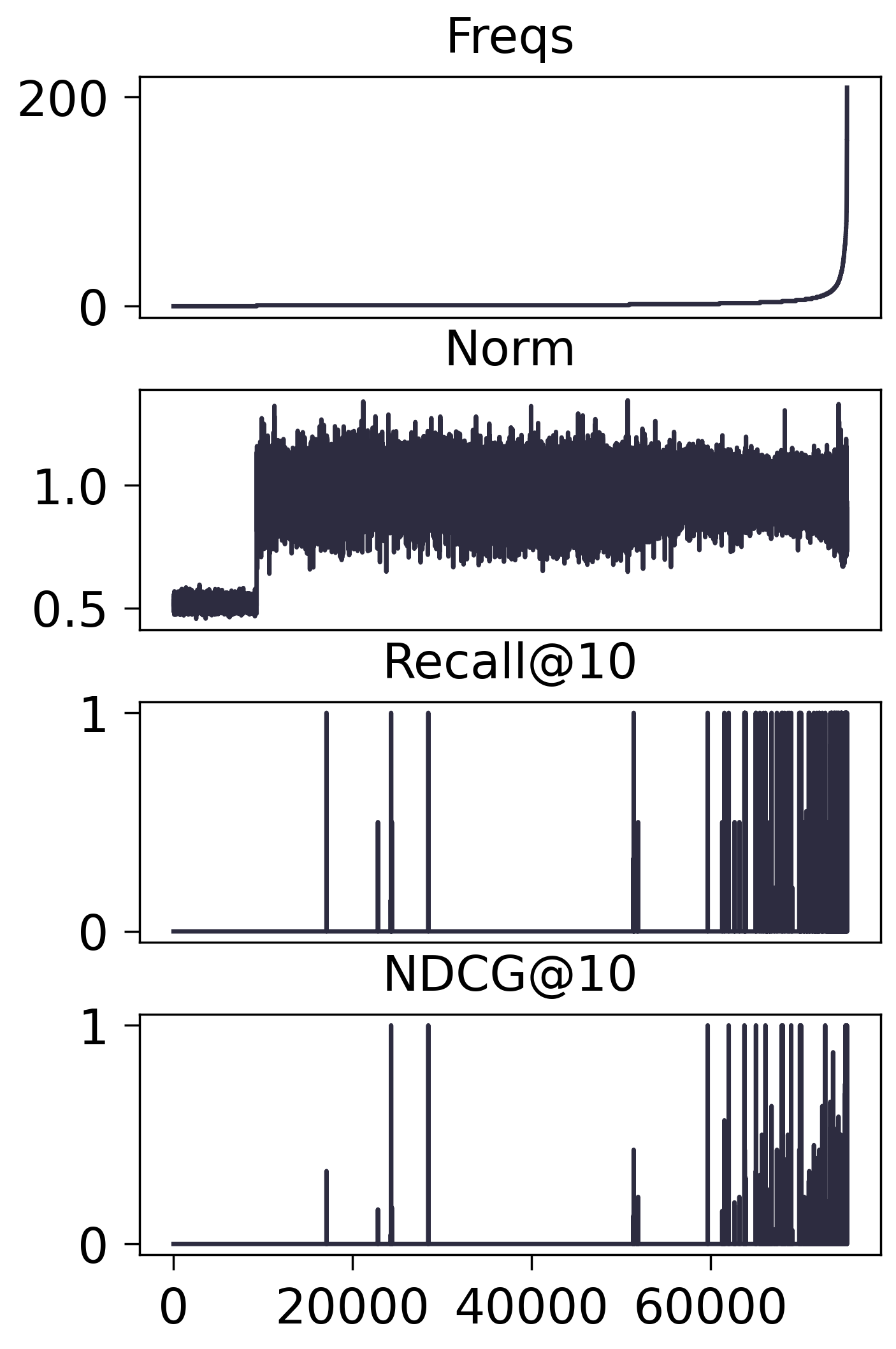
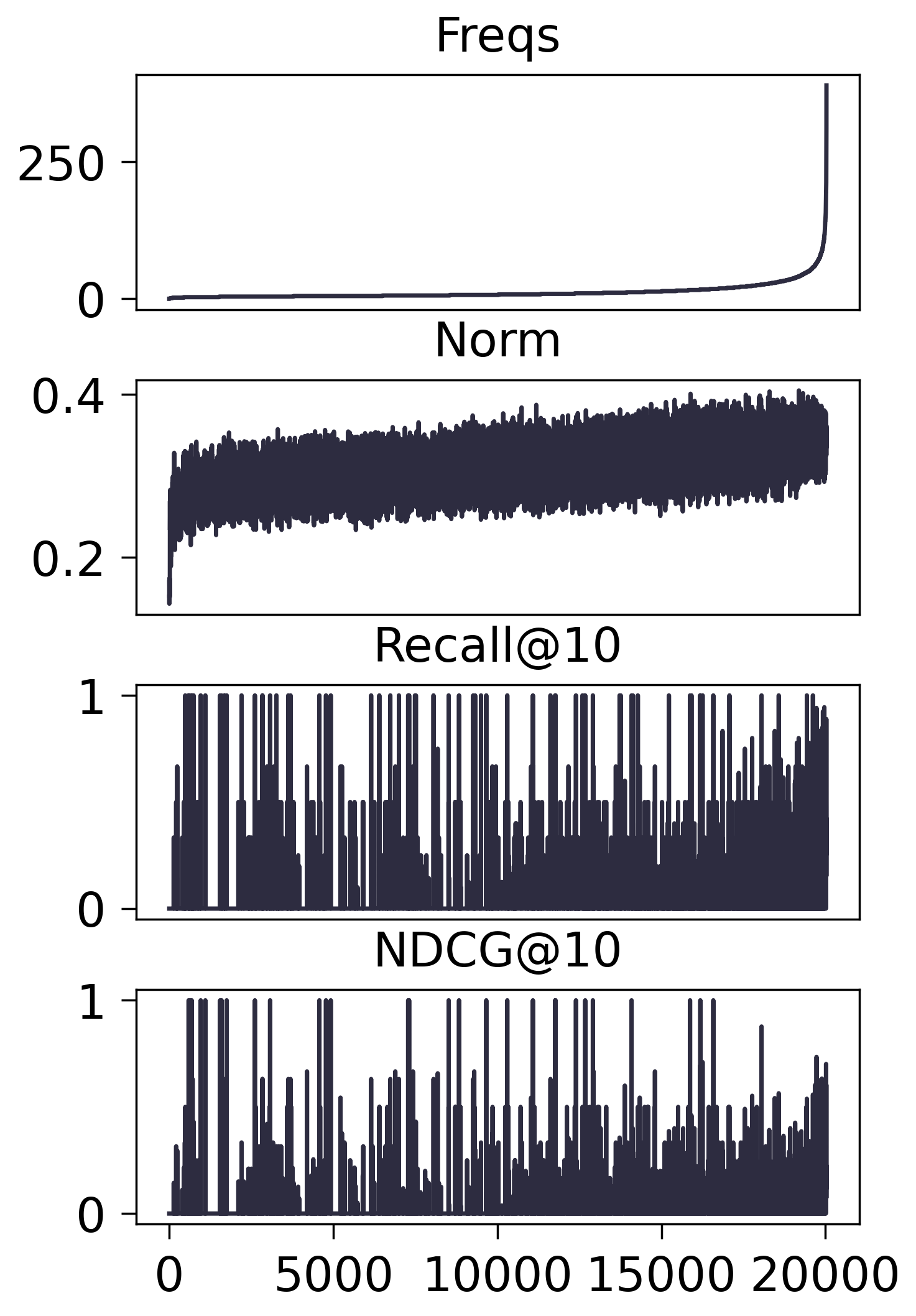
Amazon2014Beauty_1000_LOU
- MF-BPR:
- SASRec:
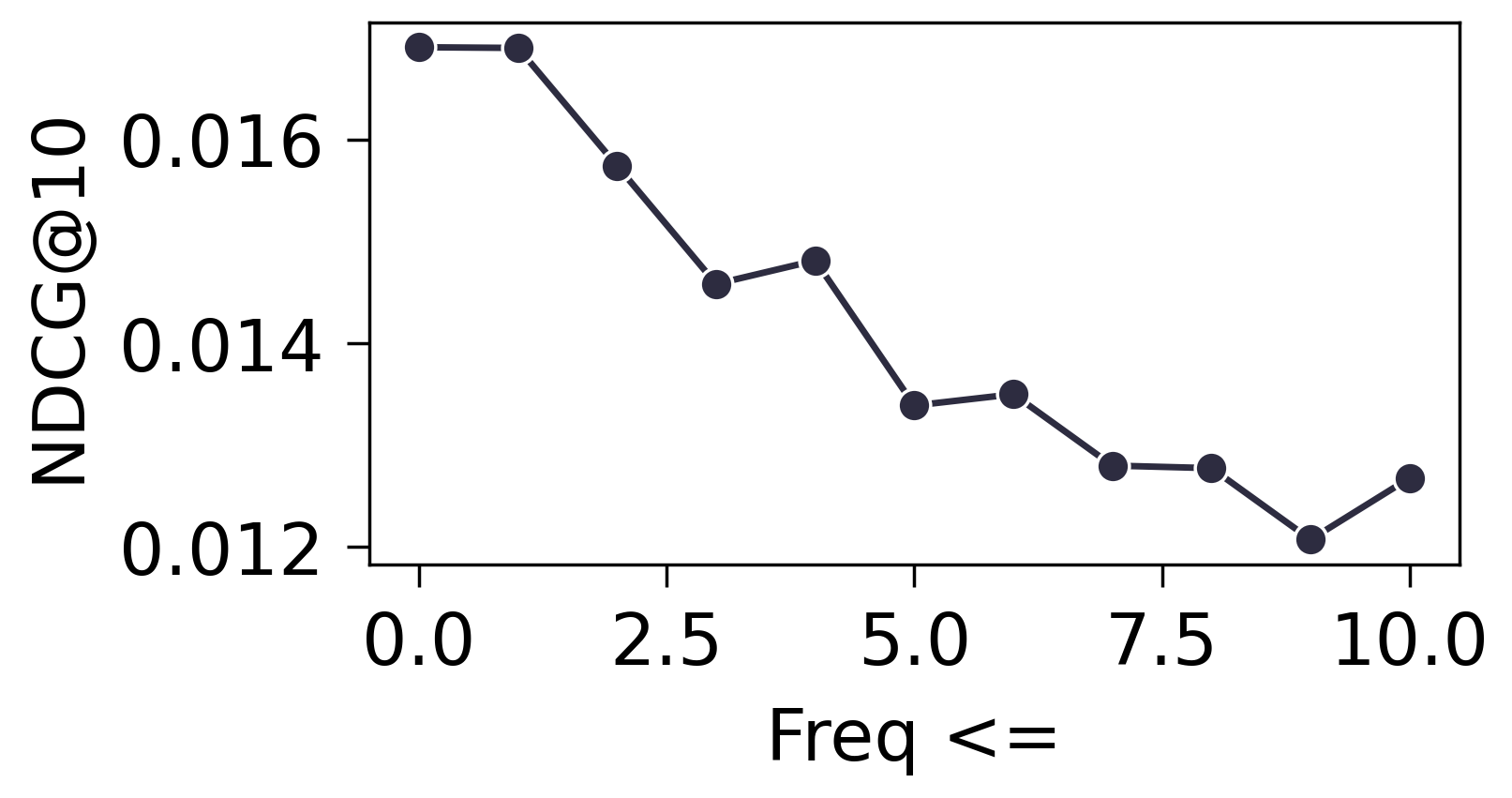
- 进一步测试所有 Freqs 落在 $[l, u]$ 内的 Items 均不训练, 结果如下:
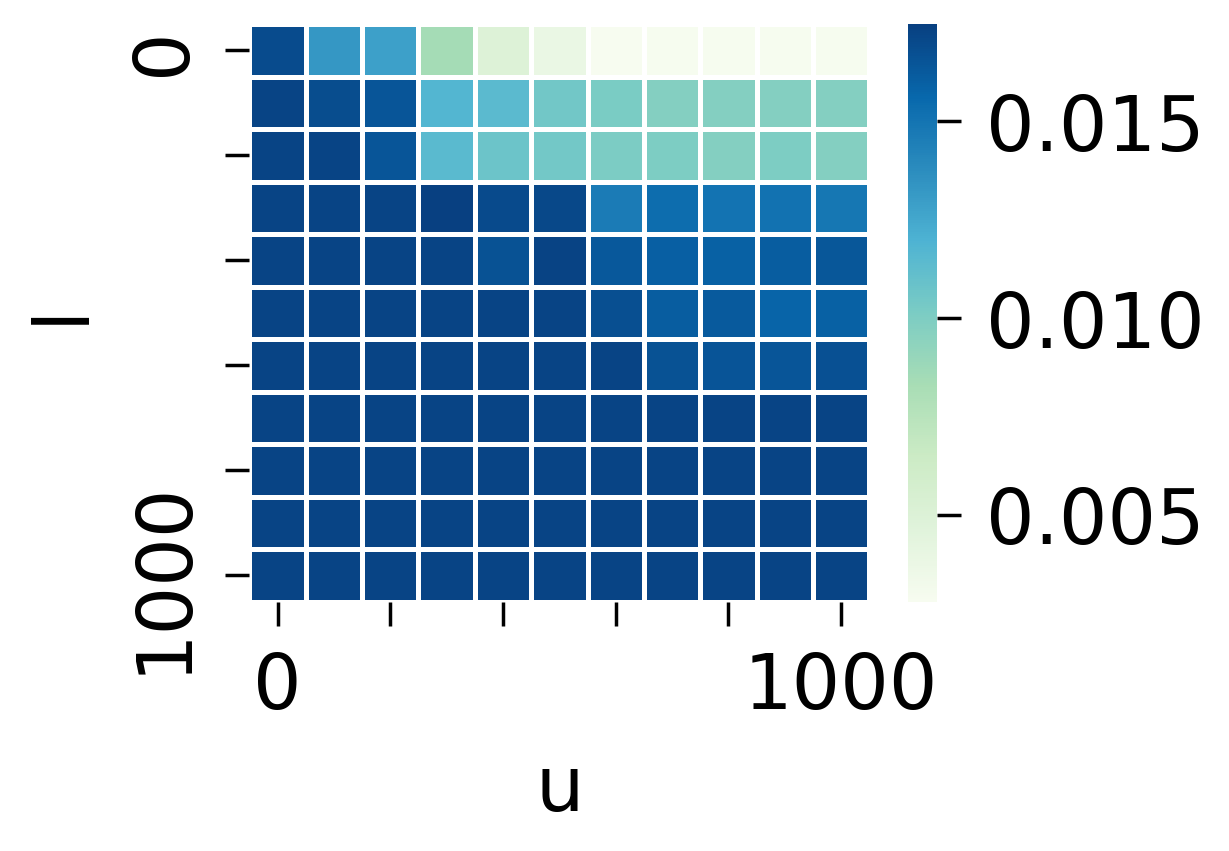
- 从上面的实验可以发现, 冷启动的商品和热门的商品, 都比较依赖 Embedding. 相比较下, 个人感觉热门商品相对来说不那么吃 Embedding. 当然这和我们的策略有关, 既然我们采取的是周围邻居的平均, 最热门的商品往往就是最大众化的. 冷门商品的连接, 相对而言可能反而有那么点随机性.
代码
train.py
- 训练模型的脚本,
lower-freq和upper-freq用来指定哪个区域内的 items 不训练.
# train.py
from typing import Dict, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
import freerec
freerec.declare(version='1.0.1')
cfg = freerec.parser.Parser()
cfg.add_argument("--maxlen", type=int, default=50)
cfg.add_argument("--num-heads", type=int, default=1)
cfg.add_argument("--num-blocks", type=int, default=2)
cfg.add_argument("--lower-freq", type=int, default=0)
cfg.add_argument("--upper-freq", type=int, default=5)
cfg.add_argument("--embedding-dim", type=int, default=64)
cfg.add_argument("--dropout-rate", type=float, default=0.2)
cfg.add_argument("--loss", type=str, choices=('BPR', 'BCE', 'CE'), default='BCE')
cfg.set_defaults(
description="SASRec",
root="../../data",
dataset='Amazon2014Beauty_550_LOU',
epochs=200,
batch_size=256,
optimizer='adam',
lr=1e-3,
weight_decay=0.,
seed=1,
)
cfg.compile()
class PointWiseFeedForward(nn.Module):
def __init__(self, hidden_size: int, dropout_rate: int):
super(PointWiseFeedForward, self).__init__()
self.conv1 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.relu = nn.ReLU()
self.conv2 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout2 = nn.Dropout(p=dropout_rate)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
# inputs: (B, S, D)
outputs = self.dropout2(self.conv2(self.relu(
self.dropout1(self.conv1(inputs.transpose(-1, -2)))
))) # -> (B, D, S)
outputs = outputs.transpose(-1, -2) # -> (B, S, D)
outputs += inputs
return outputs
class SASRec(freerec.models.SeqRecArch):
def __init__(
self, dataset: freerec.data.datasets.RecDataSet,
maxlen: int = 50, embedding_dim: int = 64,
dropout_rate: float = 0.2, num_blocks: int = 1, num_heads: int = 2,
) -> None:
super().__init__(dataset)
self.embedding_dim = embedding_dim
self.num_blocks = num_blocks
self.Item.add_module(
'embeddings', nn.Embedding(
num_embeddings=self.Item.count + self.NUM_PADS,
embedding_dim=embedding_dim,
padding_idx=self.PADDING_VALUE
)
)
self.Position = nn.Embedding(maxlen, embedding_dim)
self.embdDropout = nn.Dropout(p=dropout_rate)
self.register_buffer(
"positions",
torch.tensor(range(0, maxlen), dtype=torch.long).unsqueeze(0)
)
self.attnLNs = nn.ModuleList() # to be Q for self-attention
self.attnLayers = nn.ModuleList()
self.fwdLNs = nn.ModuleList()
self.fwdLayers = nn.ModuleList()
self.lastLN = nn.LayerNorm(embedding_dim, eps=1e-8)
for _ in range(num_blocks):
self.attnLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.attnLayers.append(
nn.MultiheadAttention(
embed_dim=embedding_dim,
num_heads=num_heads,
dropout=dropout_rate,
batch_first=True # !!!
)
)
self.fwdLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.fwdLayers.append(PointWiseFeedForward(
embedding_dim, dropout_rate
))
# False True True ...
# False False True ...
# False False False ...
# ....
# True indices that the corresponding position is not allowed to attend !
self.register_buffer(
'attnMask',
torch.ones((maxlen, maxlen), dtype=torch.bool).triu(diagonal=1)
)
edge_index = dataset.train().to_bigraph(edge_type='U2I')['U2I'].edge_index
R = torch.sparse_coo_tensor(
edge_index, torch.ones_like(edge_index[0], dtype=torch.float),
size=(self.User.count, self.Item.count)
)
freqs = torch.sparse.sum(R, dim=0).to_dense()
item_item_graph = (R.t() @ R).to_sparse_coo()
edge_index, edge_weight = item_item_graph.indices(), item_item_graph.values()
edge_index, edge_weight = freerec.graph.to_normalized(
edge_index, edge_weight, normalization='left'
)
self.register_buffer(
'iAdj',
freerec.graph.to_adjacency(
edge_index + self.NUM_PADS, edge_weight,
num_nodes=self.Item.count + self.NUM_PADS
)
)
freqs = torch.cat((torch.zeros_like(freqs)[:self.NUM_PADS], freqs), dim=0)
self.register_buffer(
'itrigger',
((cfg.lower_freq <= freqs) & (freqs <= cfg.upper_freq)).float().unsqueeze(-1),
)
if cfg.loss == 'BCE':
self.criterion = freerec.criterions.BCELoss4Logits(reduction='mean')
elif cfg.loss == 'BPR':
self.criterion = freerec.criterions.BPRLoss(reduction='mean')
elif cfg.loss == 'CE':
self.criterion = freerec.criterions.CrossEntropy4Logits(reduction='mean')
self.reset_parameters()
def reset_parameters(self):
"""Initializes the module parameters."""
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0.)
elif isinstance(m, nn.Embedding):
nn.init.xavier_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d)):
nn.init.constant_(m.weight, 1.)
nn.init.constant_(m.bias, 0.)
def sure_trainpipe(self, maxlen: int, batch_size: int):
return self.dataset.train().shuffled_seqs_source(
maxlen=maxlen
).seq_train_yielding_pos_(
start_idx_for_target=1, end_idx_for_input=-1
).seq_train_sampling_neg_(
num_negatives=1
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq,)
).lpad_(
maxlen, modified_fields=(self.ISeq, self.IPos, self.INeg),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
def mark_position(self, seqs: torch.Tensor):
positions = self.Position(self.positions) # (1, maxlen, D)
return seqs + positions
def after_one_block(self, seqs: torch.Tensor, padding_mask: torch.Tensor, l: int):
# inputs: (B, S, D)
Q = self.attnLNs[l](seqs)
seqs = self.attnLayers[l](
Q, seqs, seqs,
attn_mask=self.attnMask,
need_weights=False
)[0] + seqs
seqs = self.fwdLNs[l](seqs)
seqs = self.fwdLayers[l](seqs)
return seqs.masked_fill(padding_mask, 0.)
def encode(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
itemEmbds = self.Item.embeddings.weight
smoothed = self.iAdj @ itemEmbds
itemEmbds = itemEmbds * (1 - self.itrigger) + smoothed * self.itrigger
seqs = data[self.ISeq]
padding_mask = (seqs == self.PADDING_VALUE).unsqueeze(-1)
seqs = F.embedding(seqs, itemEmbds, padding_idx=self.PADDING_VALUE) # (B, S) -> (B, S, D)
seqs *= self.embedding_dim ** 0.5
seqs = self.embdDropout(self.mark_position(seqs))
seqs.masked_fill_(padding_mask, 0.)
for l in range(self.num_blocks):
seqs = self.after_one_block(seqs, padding_mask, l)
userEmbds = self.lastLN(seqs) # (B, S, D)
return userEmbds, itemEmbds[self.NUM_PADS:]
def fit(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
userEmbds, itemEmbds = self.encode(data)
indices = data[self.ISeq] != self.PADDING_VALUE
userEmbds = userEmbds[indices] # (M, D)
if cfg.loss in ('BCE', 'BPR'):
posEmbds = itemEmbds[data[self.IPos][indices]] # (M, D)
negEmbds = itemEmbds[data[self.INeg][indices]] # (M, D)
posLogits = torch.einsum("MD,MD->M", userEmbds, posEmbds) # (M,)
negLogits = torch.einsum("MD,MD->M", userEmbds, negEmbds) # (M,)
if cfg.loss == 'BCE':
posLabels = torch.ones_like(posLogits)
negLabels = torch.zeros_like(negLogits)
rec_loss = self.criterion(posLogits, posLabels) + \
self.criterion(negLogits, negLabels)
elif cfg.loss == 'BPR':
rec_loss = self.criterion(posLogits, negLogits)
elif cfg.loss == 'CE':
logits = torch.einsum("MD,ND->MN", userEmbds, itemEmbds) # (M, N)
labels = data[self.IPos][indices] # (M,)
rec_loss = self.criterion(logits, labels)
return rec_loss
def recommend_from_full(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
userEmbds = userEmbds[:, -1, :] # (B, D)
return torch.einsum("BD,ND->BN", userEmbds, itemEmbds)
def recommend_from_pool(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
userEmbds = userEmbds[:, -1, :] # (B, D)
itemEmbds = itemEmbds[data[self.IUnseen]] # (B, K, D)
return torch.einsum("BD,BKD->BK", userEmbds, itemEmbds)
class CoachForSASRec(freerec.launcher.Coach):
def train_per_epoch(self, epoch: int):
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.monitor(
loss.item(),
n=len(data[self.User]), reduction="mean",
mode='train', pool=['LOSS']
)
def main():
dataset: freerec.data.datasets.RecDataSet
try:
dataset = getattr(freerec.data.datasets, cfg.dataset)(root=cfg.root)
except AttributeError:
dataset = freerec.data.datasets.RecDataSet(cfg.root, cfg.dataset, tasktag=cfg.tasktag)
model = SASRec(
dataset, maxlen=cfg.maxlen,
embedding_dim=cfg.embedding_dim, dropout_rate=cfg.dropout_rate,
num_blocks=cfg.num_blocks, num_heads=cfg.num_heads,
)
# datapipe
trainpipe = model.sure_trainpipe(cfg.maxlen, cfg.batch_size)
validpipe = model.sure_validpipe(cfg.maxlen, ranking=cfg.ranking)
testpipe = model.sure_testpipe(cfg.maxlen, ranking=cfg.ranking)
coach = CoachForSASRec(
dataset=dataset,
trainpipe=trainpipe,
validpipe=validpipe,
testpipe=testpipe,
model=model,
cfg=cfg
)
coach.fit()
if __name__ == "__main__":
main()
collect.py
- 复制通过 train.py 训练得到的 best.pt 路径, 收集一些有用的信息
# collect.py
from typing import Dict, Tuple, Union
import torch
import torch.nn as nn
import freerec
from freerec.metrics import recall, normalized_dcg
freerec.declare(version='1.0.1')
cfg = freerec.parser.Parser()
# cfg.add_argument("--path", type=str, default="./logs/SASRec/Amazon2014Beauty_550_LOU/0611195953")
# cfg.add_argument("--path", type=str, default="./logs/SASRec/Amazon2014Beauty_1000_LOU/0612210619")
# cfg.add_argument("--path", type=str, default="./logs/SASRec/Yelp2019_550_S3Rec/0612213117")
cfg.add_argument("--path", type=str, default="./logs/No-Any-LN/Amazon2014Beauty_550_LOU/0613105721")
cfg.add_argument("--maxlen", type=int, default=50)
cfg.add_argument("--num-heads", type=int, default=1)
cfg.add_argument("--num-blocks", type=int, default=2)
cfg.add_argument("--embedding-dim", type=int, default=64)
cfg.add_argument("--dropout-rate", type=float, default=0.2)
cfg.add_argument("--loss", type=str, choices=('BPR', 'BCE', 'CE'), default='BCE')
cfg.set_defaults(
description="SASRec-Freq-Test",
root="../../data",
dataset='Amazon2014Beauty_550_LOU',
epochs=200,
batch_size=256,
optimizer='adam',
lr=1e-3,
weight_decay=0.,
seed=1,
)
cfg.compile()
cfg.epochs = 0
class PointWiseFeedForward(nn.Module):
def __init__(self, hidden_size: int, dropout_rate: int):
super(PointWiseFeedForward, self).__init__()
self.conv1 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.relu = nn.ReLU()
self.conv2 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout2 = nn.Dropout(p=dropout_rate)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
# inputs: (B, S, D)
outputs = self.dropout2(self.conv2(self.relu(
self.dropout1(self.conv1(inputs.transpose(-1, -2)))
))) # -> (B, D, S)
outputs = outputs.transpose(-1, -2) # -> (B, S, D)
outputs += inputs
return outputs
class SASRec(freerec.models.SeqRecArch):
def __init__(
self, dataset: freerec.data.datasets.RecDataSet,
maxlen: int = 50, embedding_dim: int = 64,
dropout_rate: float = 0.2, num_blocks: int = 1, num_heads: int = 2,
) -> None:
super().__init__(dataset)
self.embedding_dim = embedding_dim
self.num_blocks = num_blocks
self.Item.add_module(
'embeddings', nn.Embedding(
num_embeddings=self.Item.count + self.NUM_PADS,
embedding_dim=embedding_dim,
padding_idx=self.PADDING_VALUE
)
)
self.Position = nn.Embedding(maxlen, embedding_dim)
self.embdDropout = nn.Dropout(p=dropout_rate)
self.register_buffer(
"positions",
torch.tensor(range(0, maxlen), dtype=torch.long).unsqueeze(0)
)
self.attnLNs = nn.ModuleList() # to be Q for self-attention
self.attnLayers = nn.ModuleList()
self.fwdLNs = nn.ModuleList()
self.fwdLayers = nn.ModuleList()
self.lastLN = nn.LayerNorm(embedding_dim, eps=1e-8)
for _ in range(num_blocks):
self.attnLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.attnLayers.append(
nn.MultiheadAttention(
embed_dim=embedding_dim,
num_heads=num_heads,
dropout=dropout_rate,
batch_first=True # !!!
)
)
self.fwdLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.fwdLayers.append(PointWiseFeedForward(
embedding_dim, dropout_rate
))
# False True True ...
# False False True ...
# False False False ...
# ....
# True indices that the corresponding position is not allowed to attend !
self.register_buffer(
'attnMask',
torch.ones((maxlen, maxlen), dtype=torch.bool).triu(diagonal=1)
)
if cfg.loss == 'BCE':
self.criterion = freerec.criterions.BCELoss4Logits(reduction='mean')
elif cfg.loss == 'BPR':
self.criterion = freerec.criterions.BPRLoss(reduction='mean')
elif cfg.loss == 'CE':
self.criterion = freerec.criterions.CrossEntropy4Logits(reduction='mean')
self.reset_parameters()
def reset_parameters(self):
"""Initializes the module parameters."""
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0.)
elif isinstance(m, nn.Embedding):
nn.init.xavier_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d)):
nn.init.constant_(m.weight, 1.)
nn.init.constant_(m.bias, 0.)
def sure_trainpipe(self, maxlen: int, batch_size: int):
return self.dataset.train().shuffled_seqs_source(
maxlen=maxlen
).seq_train_yielding_pos_(
start_idx_for_target=1, end_idx_for_input=-1
).seq_train_sampling_neg_(
num_negatives=1
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq,)
).lpad_(
maxlen, modified_fields=(self.ISeq, self.IPos, self.INeg),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
def mark_position(self, seqs: torch.Tensor):
positions = self.Position(self.positions) # (1, maxlen, D)
return seqs + positions
def after_one_block(self, seqs: torch.Tensor, padding_mask: torch.Tensor, l: int):
# inputs: (B, S, D)
Q = self.attnLNs[l](seqs)
seqs = self.attnLayers[l](
Q, seqs, seqs,
attn_mask=self.attnMask,
need_weights=False
)[0] + seqs
seqs = self.fwdLNs[l](seqs)
seqs = self.fwdLayers[l](seqs)
return seqs.masked_fill(padding_mask, 0.)
def encode(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
seqs = data[self.ISeq]
padding_mask = (seqs == self.PADDING_VALUE).unsqueeze(-1)
seqs = self.Item.embeddings(seqs) # (B, S) -> (B, S, D)
seqs *= self.embedding_dim ** 0.5
seqs = self.embdDropout(self.mark_position(seqs))
seqs.masked_fill_(padding_mask, 0.)
for l in range(self.num_blocks):
seqs = self.after_one_block(seqs, padding_mask, l)
userEmbds = self.lastLN(seqs) # (B, S, D)
return userEmbds, self.Item.embeddings.weight[self.NUM_PADS:]
def fit(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
userEmbds, itemEmbds = self.encode(data)
indices = data[self.ISeq] != self.PADDING_VALUE
userEmbds = userEmbds[indices] # (M, D)
if cfg.loss in ('BCE', 'BPR'):
posEmbds = itemEmbds[data[self.IPos][indices]] # (M, D)
negEmbds = itemEmbds[data[self.INeg][indices]] # (M, D)
posLogits = torch.einsum("MD,MD->M", userEmbds, posEmbds) # (M,)
negLogits = torch.einsum("MD,MD->M", userEmbds, negEmbds) # (M,)
if cfg.loss == 'BCE':
posLabels = torch.ones_like(posLogits)
negLabels = torch.zeros_like(negLogits)
rec_loss = self.criterion(posLogits, posLabels) + \
self.criterion(negLogits, negLabels)
elif cfg.loss == 'BPR':
rec_loss = self.criterion(posLogits, negLogits)
elif cfg.loss == 'CE':
logits = torch.einsum("MD,ND->MN", userEmbds, itemEmbds) # (M, N)
labels = data[self.IPos][indices] # (M,)
rec_loss = self.criterion(logits, labels)
return rec_loss
def recommend_from_full(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
userEmbds = userEmbds[:, -1, :] # (B, D)
return torch.einsum("BD,ND->BN", userEmbds, itemEmbds)
def recommend_from_pool(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
userEmbds = userEmbds[:, -1, :] # (B, D)
itemEmbds = itemEmbds[data[self.IUnseen]] # (B, K, D)
return torch.einsum("BD,BKD->BK", userEmbds, itemEmbds)
class CoachForSASRec(freerec.launcher.Coach):
def set_other(self):
self.ndcgs = {item: {'val': 0, 'num': 0} for item in range(self.Item.count)}
self.recalls = {item: {'val': 0, 'num': 0} for item in range(self.Item.count)}
def train_per_epoch(self, epoch: int):
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.monitor(
loss.item(),
n=len(data[self.User]), reduction="mean",
mode='train', pool=['LOSS']
)
def evaluate(self, epoch: int, step: int = -1, mode: str = 'valid'):
self.get_res_sys_arch().reset_ranking_buffers()
for data in self.dataloader:
bsz = data[self.Size]
data = self.dict_to_device(data)
scores = self.model(data, ranking='full')
if self.remove_seen:
seen = self.Item.to_csr(data[self.ISeen]).to(self.device).to_dense().bool()
scores[seen] = -1e23
targets = self.Item.to_csr(data[self.IUnseen]).to(self.device).to_dense()
self.monitor(
scores, targets,
n=bsz, reduction="mean", mode=mode,
pool=['HITRATE', 'PRECISION', 'RECALL', 'NDCG', 'MRR']
)
recalls = recall(scores, targets, k=10, reduction='none').flatten().tolist()
ndcgs = normalized_dcg(scores, targets, k=10, reduction='none').flatten().tolist()
for item, recall_val, ndcg_val, in zip(data[self.IUnseen].flatten().tolist(), recalls, ndcgs):
self.recalls[item]['val'] += recall_val
self.recalls[item]['num'] += 1
self.ndcgs[item]['val'] += ndcg_val
self.ndcgs[item]['num'] += 1
if mode == 'test':
freerec.utils.export_pickle(
self.recalls, f"{self.cfg.dataset}_recalls.pkl"
)
freerec.utils.export_pickle(
self.ndcgs, f"{self.cfg.dataset}_ndcgs.pkl"
)
freerec.utils.export_pickle(
self.model.Item.embeddings.weight[1:].cpu(),
f"{self.cfg.dataset}_embds.pkl"
)
def main():
dataset: freerec.data.datasets.RecDataSet
try:
dataset = getattr(freerec.data.datasets, cfg.dataset)(root=cfg.root)
except AttributeError:
dataset = freerec.data.datasets.RecDataSet(cfg.root, cfg.dataset, tasktag=cfg.tasktag)
model = SASRec(
dataset, maxlen=cfg.maxlen,
embedding_dim=cfg.embedding_dim, dropout_rate=cfg.dropout_rate,
num_blocks=cfg.num_blocks, num_heads=cfg.num_heads,
)
# datapipe
trainpipe = model.sure_trainpipe(cfg.maxlen, cfg.batch_size)
validpipe = model.sure_validpipe(cfg.maxlen, ranking=cfg.ranking)
testpipe = model.sure_testpipe(cfg.maxlen, ranking=cfg.ranking)
coach = CoachForSASRec(
dataset=dataset,
trainpipe=trainpipe,
validpipe=validpipe,
testpipe=testpipe,
model=model,
cfg=cfg
)
coach.load(cfg.path, "best.pt")
coach.fit()
if __name__ == "__main__":
main()
analyze.py
- 分析以及画图的脚本
# analyze.py
# %%
import torch
import freerec
from freerec.data.datasets import Amazon2014Beauty_550_LOU, Amazon2014Beauty_1000_LOU, Yelp2019_550_S3Rec
from freerec.data.tags import USER, ITEM, ID, SEQUENCE
from freeplot import FreePlot
import numpy as np
# %%
dataset = Amazon2014Beauty_550_LOU(
"../../data"
)
# dataset = Amazon2014Beauty_1000_LOU(
# "../../data"
# )
# dataset = Yelp2019_550_S3Rec(
# "../../data"
# )
User = dataset.fields[USER, ID]
Item = dataset.fields[ITEM, ID]
ISeq = Item.fork(SEQUENCE)
# %%
embeddings = freerec.utils.import_pickle(f"{dataset.__class__.__name__}_embds.pkl")
ndcgs = freerec.utils.import_pickle(f"{dataset.__class__.__name__}_ndcgs.pkl")
recalls = freerec.utils.import_pickle(f"{dataset.__class__.__name__}_recalls.pkl")
freqs = {item: 0 for item in range(Item.count)}
# %%
ndcgs = {key: val['val'] / max(1, val['num']) for key, val in ndcgs.items()}
recalls = {key: val['val'] / max(1, val['num']) for key, val in recalls.items()}
for row in dataset.train().to_seqs(maxlen=50):
seq = row[ISeq]
for item in seq:
freqs[item] += 1
norms = embeddings.norm(dim=-1).numpy()
freqs = np.array([freqs[item] for item in range(Item.count)])
ndcgs = np.array([ndcgs[item] for item in range(Item.count)])
recalls = np.array([recalls[item] for item in range(Item.count)])
sort_indices = np.argsort(freqs)
freqs = freqs[sort_indices]
norms = norms[sort_indices]
ndcgs = ndcgs[sort_indices]
recalls = recalls[sort_indices]
# %%
fp = FreePlot(
(4, 1),
figsize=(1.2, 3),
titles=('Freqs', 'Norm', 'Recall@10', 'NDCG@10'),
sharey=False
)
x = list(range(Item.count))
fp.lineplot(
x, freqs,
marker='',
index=(0, 0)
)
fp.lineplot(
x, norms,
marker='',
index=(1, 0)
)
fp.lineplot(
x, recalls,
marker='',
index=(2, 0)
)
fp.lineplot(
x, ndcgs,
marker='',
index=(3, 0)
)
for i in range(3):
fp.set_ticks([], index=(i, 0), axis='x')
fp.subplots_adjust(hspace=0.3)
fp.set_title()
fp.show()
# %%