Physics of Language Models: Part 3.1, Knowledge Storage and Extraction
核心思想
LLM 已经惊艳了所有人, 尤其是它广博的知识面, 几乎可以说是博古通今 (当然了, 有幻觉问题). 所以, 一个很自然的问题是, LLM 存储和提取知识的机制是怎么样的呢? 虽然已经有一些工作在现有的 LLM 的基础上进行探索, 但是并没有严格控制变量, 导致其得出的结论并不那么严谨. 比如询问 “高斯的出生日期?”, LLM 得到的答案可能来自两种: 1. 记忆了 wikipedia 等知识库并从中抽取; 2. 训练语料里中恰好有这个问题, 从而能够很好地回答.
为了避免上述第二种情况引发的一个干扰, 作者人为构造一些数据集, 并从头训练以严格控制变量.
Setting
数据集
- bioS: 从 $N=100,000$ 个体中随机生成 profiles: 每个个体的出生日期, 出生的城市, 毕业院校, 就职公司, 工作城市等独立随机生成. 每个个体的 full name 是独一无二的. 如下是一个例子,
Anya Briar Forger was born on October 2, 1996. She spent her early years in Princeton, NJ. She received mentorship and guidance from faculty members at Massachusetts Institute of Technology. She completed her education with a focus on Communications. She had a professional role at Meta Platforms. She was employed in Menlo Park, CA.
对于 bioS, 在后续的实验中可能会涉及 3 种不同的数据增强方法:
- multiM: 即用 $M$ 种模板为每个个体生成多样的人物传记;
- fullname: 将 he/she/they 等代词替换为个体的 fullname;
- permute: 上述传记有 6 个句子, 这个数据增强就是将 6 个句子进行一个随机打乱.
bioR: 这个数据集借助 Llama 生成更为接近现实的任务传记 (风格上更为符合), 如下是一个例子:
Anya Briar Forger is a renowned social media strategist and community manager. She is currently working as a Marketing Manager at Meta Platforms. She completed her graduation from MIT with a degree in Communications. She was born on 2nd October 1996 in Princeton, NJ and was brought up in the same city. She later moved to Menlo Park in California to be a part of Facebook’s team. She is an avid reader and loves traveling.
- QA dataset: 为了进一步评估模型的抽取 (而不仅仅是记忆) 知识的能力, 作者设计了 QA dataset: 对于每条人物传记, 可生成如下的六条 QA:
训练策略
主要采用 GPT2/Llama 进行训练, 最后也会讨论一下 BERT. 记 baseline 为按照数据集各个属性的多数进行猜测的方式.
Pretrain + Instruction finetune: 在 bioS/bioR 上从头预训练 LM, 然后用 QA data 的一半进行指令微调, 然后再用 QA 的剩下一半进行测试.
Mixed Training: 在 bioS/bioR + 一半的 QA data 上从头预训练 LM, 按照一定比例采样 BIO data 和 QA data (比如 2:8). 用剩下的 QA data 进行测试.
Mixed Training Enables Knowledge Extraction
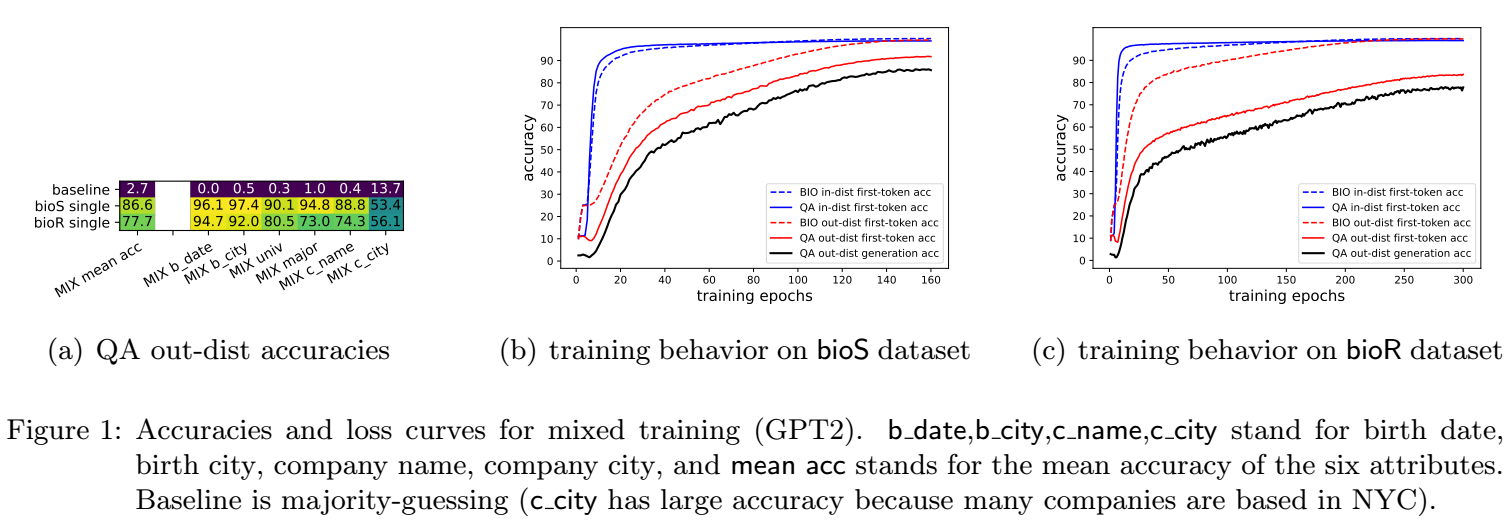
注: first-token accuracy 指的是对应 answer 的第一个 token 的预测正确率, generation accuracy 指的是完全回答出整个属性的正确率.
如上图所示, 采用 mixed training 可以很容易取得很高的正确率, 不论是 BIO 数据的 in/out-distribution accuracy, 还是 QA in/out-distribution accuracy.
特别地, 可以注意到, 通过 QA data 的学习能够很快地帮助 BIO data 的记忆, 渐渐地这种优势能够逐步泛化到 out-distribution data.
结论: Mixed Training 能够有效提高模型的知识提取能力.
Model Fails to Extract Knowledge After BIO Pretrain
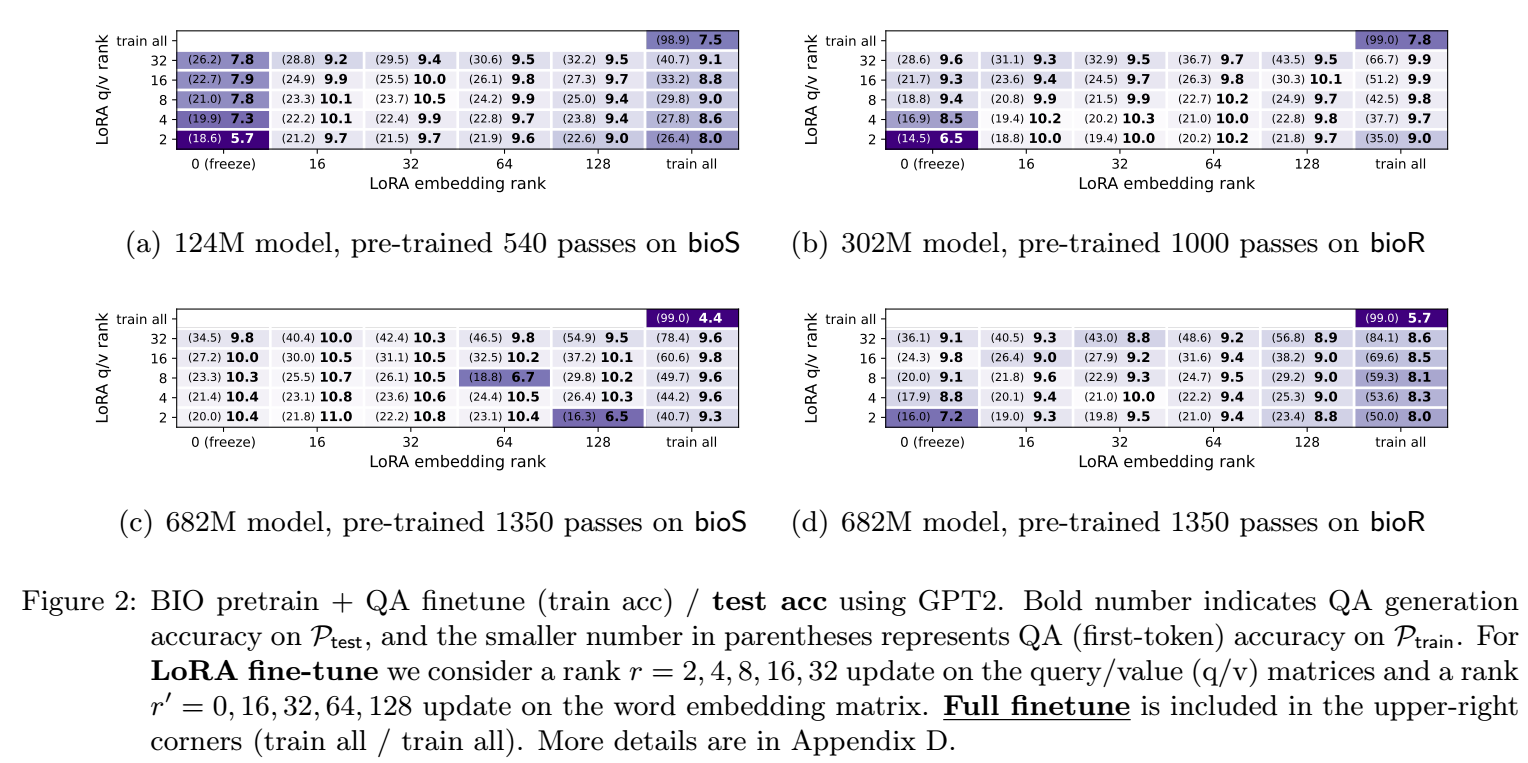
如上图所示, Pretrain + Instruction finetune 难以获得有效的 out-distribution QA generation accuracy, 无论是 LoRA finetune 还是 full finetune.
实际上, full finetune 是能够保证训练数据能够被记忆的, 但由于 pretraining 过程中没有接触过 QA 的数据类型, 后面 finetune 无法改变模型的推理逻辑. 这有种学生一个劲地死记硬背, 但是没有做过任何真题, 考试的时候就直接蒙圈了.
结论: 仅在知识库中训练可以记忆知识但是缺乏提取能力, 而且这种能力没法后天补足.
Knowledge Augmentation
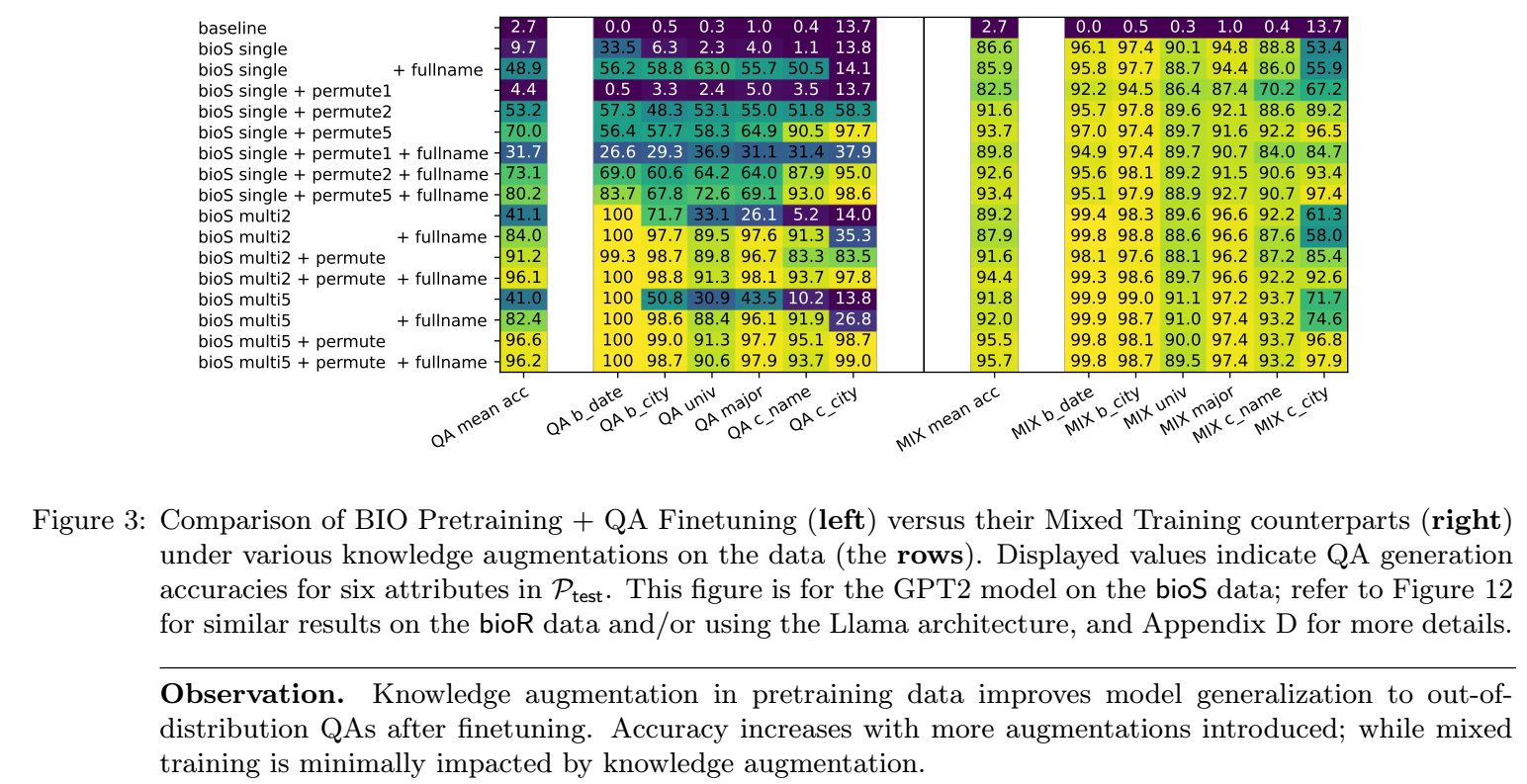
有一个问题是, QA 这种数据类型对于知识提取是否是必须的? 能不能通过其它方式学习到呢? 上图就是探索, 在 bioS 上应用三种数据增强后的效果:
- multiM: 即用 $M$ 种模板为每个个体生成多样的人物传记;
- fullname: 将 he/she/they 等代词替换为个体的 fullname;
- permute: 上述传记有 6 个句子, 这个数据增强就是将 6 个句子进行一个随机打乱.
可以发现, multi5 + permute 就能够取得和 mixed training 相当的效果了!
结论: 数据增强尤其是多样的模板 + 属性位置打乱能够完全替代 QA 在知识提取能力增强方面的作用.
Position-Based Probing
- 其实看完上面的实验, 大概率会有这样一种感觉, 就是纯的 bioS/bioR 的预训练可能会导致模型将知识绑定到一些奇奇怪怪的东西上面. 而加入了数据增强之后, 大概率这些数据就能够被绑定到 full name 之上了. 所以作者做了一些实验进行验证.

如上图所示, 作者定义了 6 个 special token positions, 每个 token position 都可以定义 6 个任务, 分别是 c_name/univ/major/b_data/b_city/c_city, 所以实际上总共有 $6 \times 6$ 个任务.
对于每个任务, 固定预训练的网络, 然后对于 embedding layer 加一个 rank-2 的 LoRA 然后在网络最后加一个额外的可训练的分类线性层.

如上图所示, 在纯的 bioS 上训练, 基本上 special token 对于预测所对应的属性比较准 (比如根据上面的例子, ‘at’ 容易预测对公司, ‘on’ 容易预测对生日). 这实际上说明了, 在纯的 bioS 上训练, 模型会以一种奇怪的方式记忆知识. 而不是将这些信息和 full name 绑定在一起.
而加入了数据增强之后, 基本上每个 special token 都能预测对后面的属性.
结论: 越多的数据增强能够大大提高 $P$-probing 的正确率, 衍生出正确关联关系.
Query-Based Probing

实际上, 我们可以对 full name 也进行类似上面的过程, 可以得到一样的结论, 即数据增强能够促使模型将知识绑定到 full name 上而不是一些奇怪的联系. 如上图所示, 当我们的输入仅包括 full name 的时候, 只有经过数据增强的预训练能够取得较高的分类精度 (即此时 full name 绑定了很多对应的属性).
结论: 越多的数据增强能够大大提高 $Q$-probing 的正确率, 将属性正确地绑定到 full name 之上.
Celebrity Can Help Minority
- 现在有一个问题, 因为实际的数据, 我们很难对每条数据都进行合理的数据增强. 那么仅对部分数据数据增强是否能够帮助对未进行过数据增强的数据的知识抽取呢?

- 结论: 应用部分数据上的数据增强也能够帮助其它数据的知识抽取.
Knowledge Storage for Bidirectional Models

- 结论: BERT 在知识抽取方面能力堪忧, 大概率的原因是 BERT 是双向的, 导致其错误的关联更甚, 比如 城市 ‘Bellevue’ 和州 ‘WA’ 可能产生相互关联, 而不是把这个信息引导向 full name. 而 birth, major 这类较为独立的词, 反而能够较好地和 full name 关联上.