Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
预备知识
- 请了解 TIGER.
核心思想
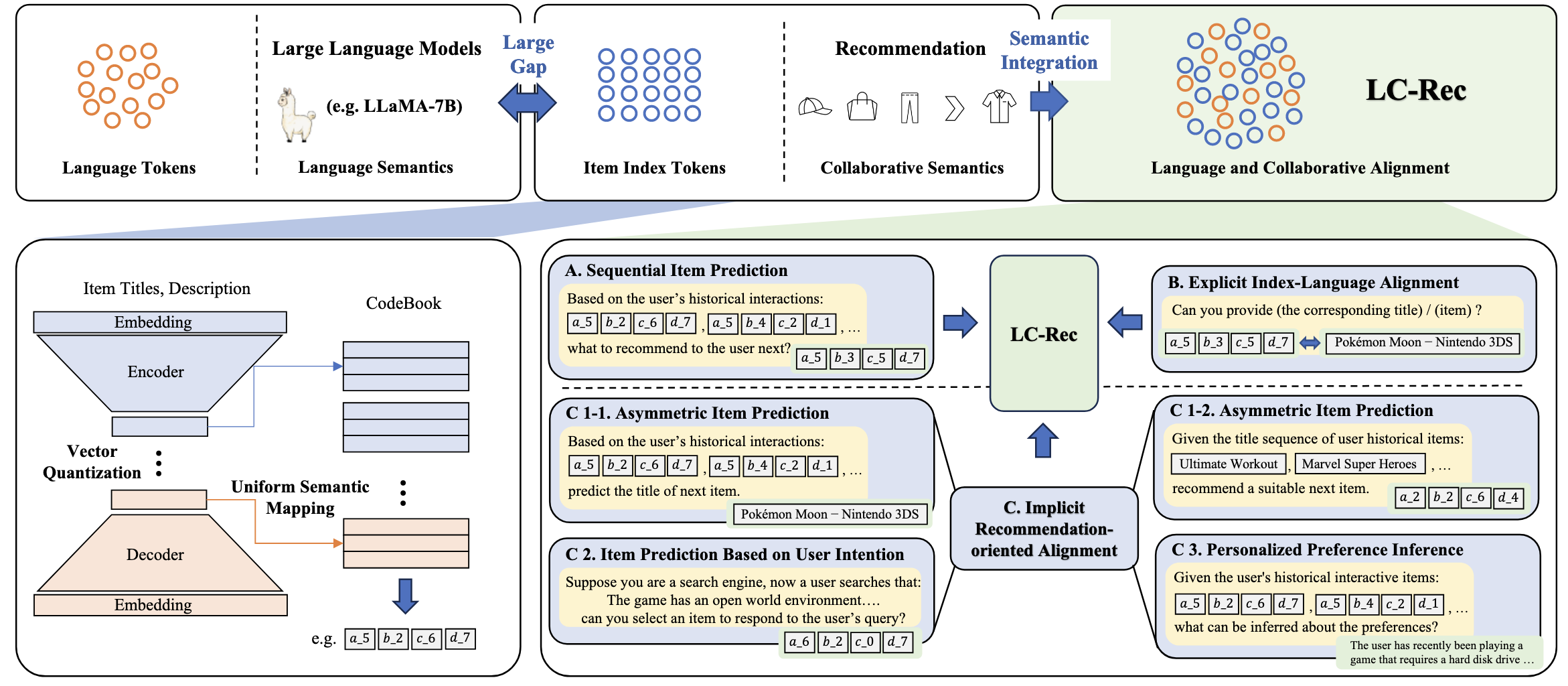
出发点: LLM 的语义空间和推荐系统中所蕴含的协同语义空间存在很大的 gap. 作者希望设计一些任务来弥补这个 gap, 从而使得 LLM 具备推荐的能力.
向量量化: 首先需要做的事情是将 Item 映射到 LLM 的语义空间中去:
- 以往这种方式可能是通过一个 projector 来将 Item 的语义 embedding 映射到 LLM 的语义空间当中去;
- LC-Rec 选择通过和 Tiger 类似的方法, 用 RQ-VAE 首先将所有的 Item 映射为一组语义 IDs, 然后这组 IDs 作为 LLM 原本的词表的扩展, 后续通过一系列任务进行学习.
注: 我不觉得从表达能力上来说, 向量量化会比直接用 projector 的方式好, 但是感觉向量量化的确更贴合 LLM 本身的设计.
Uniform Semantic Mapping: 向量量化有一个常被人诟病的问题, 即 allocation conflict (两个 Item 有可能会被分配到同一组 IDs). 类似 Tiger 使用额外的 level 来缓解这个问题. 本文提出在最后一个 level 采用 Uniform Semantic Mapping 而不是一贯的最近邻匹配. 从技术上来说, 对于最后一个 level 的 ID 的分配, 作者将其作为一个最优传输问题, 然后通过 Sinkhorn-Knopp 算法来近似求解. 我们知道, Sinkhorn 距离可以通过调节超参数来促使整个分配过程变得 ‘均匀’.
于是, 接下来的任务其实就是怎么训练新添加的 tokens 了.
- Sequential Item PredictionL 传统的用序列 IDs 预测下一个 ID (组合):

- Explicit Index-Language Alignment. 将 Item 的文本描述和 IDs 联系在一起的任务:

- Implicit Recommendation-oriented Alignment.
- Asymmetric item prediction: 将任务 1 中的 1) 序列 IDs 替换为 Title; 2) Target item ID 替换为 Title; 3) Target item ID 替换为 Text Description.
- Item prediction based on user intention: 基于用户意图 (query) 预测合适的 Item;
- Personalized preference inference: 根据用户交互 IDs 序列预测用户的个性化偏好 (preference 是通过 GPT-3.5 得到的).
Training: 通过普通的 next-token loss 训练.
Inference: Beam search, 但是会舍弃那些无意义的 IDs.