Unifying Generative and Dense Retrieval for Sequential Recommendation
Content
预备知识
- 请了解 TIGER 和 UniSRec.
核心思想
- 本文投稿 ICLR 2025 被惨拒, 我看主要问题集中在方法层面过于简单. 个人认为确实如此, 不过有一些实验观察我感觉还是很有趣的, 至少我之前不清楚生成式推荐在冷启动上居然存在问题 (我一直认为这方面应该是其优势才对).

这里需要先声明一下实验设置:
- Dense: 采用的 UnisRec 的训练方式, 同时依赖 text embedding 和 id embedding 的版本, Dense 是指其推荐的方式最终是通过一个编码得到的 user embedding 和所有的 item embedding 进行一一匹配计算相似度然后排名得到的. 其输入 item embedding 为:
- Generative: 采用的是 TIGER, 其首先通过 RQ-VAE 将 item 的文本信息编码成离散的 token 表示, 称之为 semantic ID, 然后基于 semantic ID 进行推荐. 相较于 Dense, 它的词表会小很多, 因此某种程度上会更加高效一些.
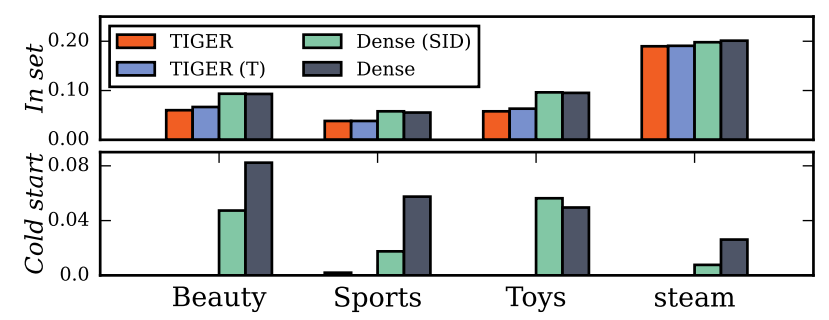
如上图所示, 相比于 Dense, TIGER 在 In-set 和 Cold-start 场景下的效果都不尽如人意. 特别是后者, 会让人感觉特别奇怪.
首先一个值得怀疑的点是不是通过向量量化得到的 semantic ID 不能像独立的 ID embedding 那样抓住 item-item 间的关系, 为此作者将 (1) 中的 ID $i$ 替换为 semantic ID $(s_i^1, s_i^2, \cdots, s_i^m)$:
$$ \tag{2} \mathbf{e}{s_i^j} = \underbrace{\mathbf{x}{s_i^j}}_{ID} + \underbrace{\mathbf{x}i^{\text{text}}}{text} + \underbrace{\mathbf{x}_i^{\text{pos}} + \mathbf{x}j^{\text{pos}}}{positional}. $g’g
于是, 此时每个 item 通过一组 embeddings 表示:
$ben'wen \mathbf{E}_{i} = [\mathbf{e}_{s_i^1}, \mathbf{e}_{s_i^2}, \cdots, \mathbf{e}_{s_i^m}]. $$
比较的结果如下: Dense (SID) 即 (2) 能够和普通的 UniSRec (Dense) 结果相当了, 且在冷启动上也有不错的效果, 这说明 semantic ID 本身对于 item-item 的关系的学习其实并不差. 如果将 TIGER 中的 semantic ID 替换为一般的 ID (TIGER (T)), 效果也并没有什么增长, 这进一步验证了这一点.
Overfitting
- 作者认为, 导致 TIGER 等生成式推荐在冷启动商品上的推荐效果不太理想的主要原因是 TIGER 过拟合到了那些见过的 semantic ID. 如下图所示, 那些冷启动商品的得分 (概率) 不例外的远远低于很多 in-set 的 semantic ID.

- 作者提的改进有两点 (LIGER):
- 采用 (2) 的方式并同时用 UniSREC 的 cosine similarity loss 和 TIGER 的 next-token prediction loss 来训练.
- 推理的时候对冷启动商品进行一个特殊处理: 相当于将冷启动商品单独摘出来, 然后和通过生成式检索出来的商品一起再通过传统的相似度计算来排名, 从而规避上述的问题 (算是取巧吧, 没有真正解决这个问题).
