Transformers need glasses! Information Over-Squashing in Language Tasks
预备知识
- 对 Large Language Model (LLM) 有基本的了解.
核心思想
在 LLM 领域常常被诟病其在最简单的’数数’和’复读’能力上的缺陷, 经典的例子 “‘strawberry’中有几个 ‘r’” 很多大模型都败北了.
本文认为这是由于随着序列长度增长过程中 LLM 的 ‘Representational Collpase’ 导致的.
经验性的观察
- 作者在 Gemini 1.5 上进行这部分实验.
Copying
first-token copying:
- Input: ‘$0111\ldots 111$’;
- Target: ‘$0$’
last-token copying:
- Input: ‘$111\ldots 1110$’;
- Target: ‘$0$’
通过增加 ‘1’ 的数量可以增加整个序列的长度. 结果如下:

上图 (A) 是输出的结果, 可以发现在整个序列长度控制在 300 以内时, first-token, last-token copying 均能很好地完成, 然而当继续增加 ‘1’ 的数量时, 对于 last-token copying 的完成度就下降了.
进一步, 作者尝试为这个问题增加 prompt (“Hint: It’s not necessarily a 1, check carefully.”) 来提醒 LLM 最终结果不一定是 1, 结果会有明显变好.
作者进一步发现, 将 ‘$0111 \ldots 11$’ 替换为 ‘$0111 \ldots 11 \: 0111 \ldots 11 \: \ldots$’ 这种重复出现的序列时, 效果也能够有明显的变好.
Counting
考虑如下几个任务:
- 求和: $1 + \cdots + 1$;
- 简单计数: 统计一串均为 1 的序列中有多少个 1;
- 简单计数: 统计一串 0/1 序列中有多少个 1 (1 出现的概率为 70%);
- 单词计数: 统计一串序列中某个词出现的次数.
同时考虑如下 3 种指令:
- 直接输出结果 (No Shot);
- 思维链 (CoT Zero-Shot);
- 例子 + 思维链 (CoT Few-Shot).
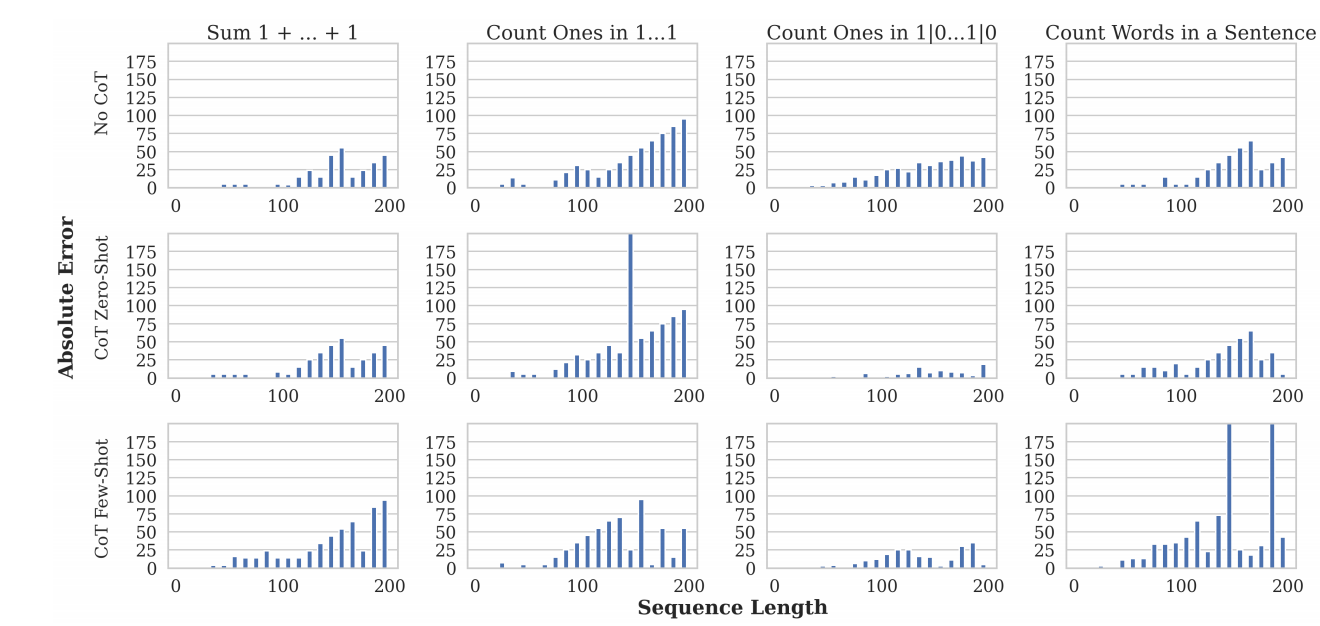
- 如上图所示:
- 随着序列长度的增加, 误差迅速增加;
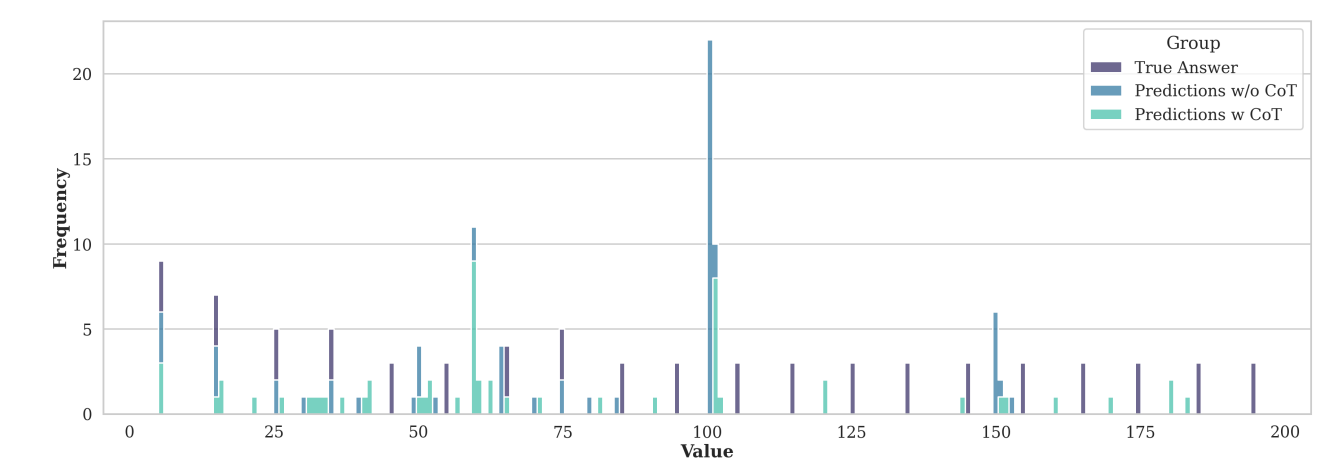
- 一旦序列长度达到了 100 左右, LLM 倾向于预测 counts 为 100:
理论分析
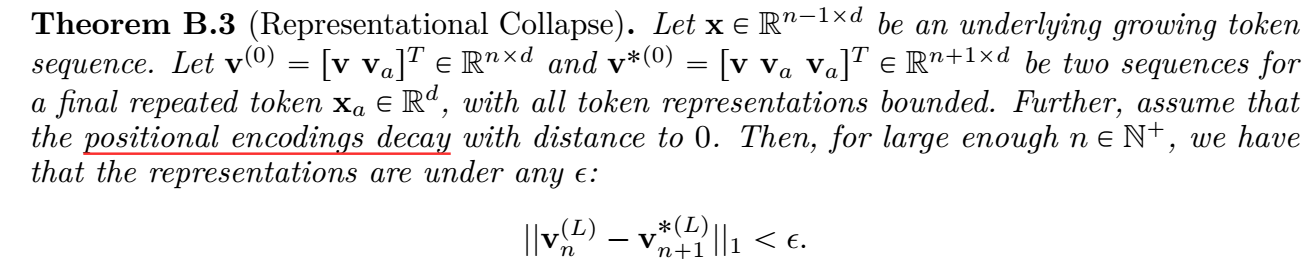
- 作者证明了, 只要序列长度足够长, 最后收敛的是一样的.
注: 作者的证明思路: 证明 attention 部分在有限 precision 的条件下会随着 $n$ 的增加趋于一致, 但是作者的证明过于粗糙和不严谨了.
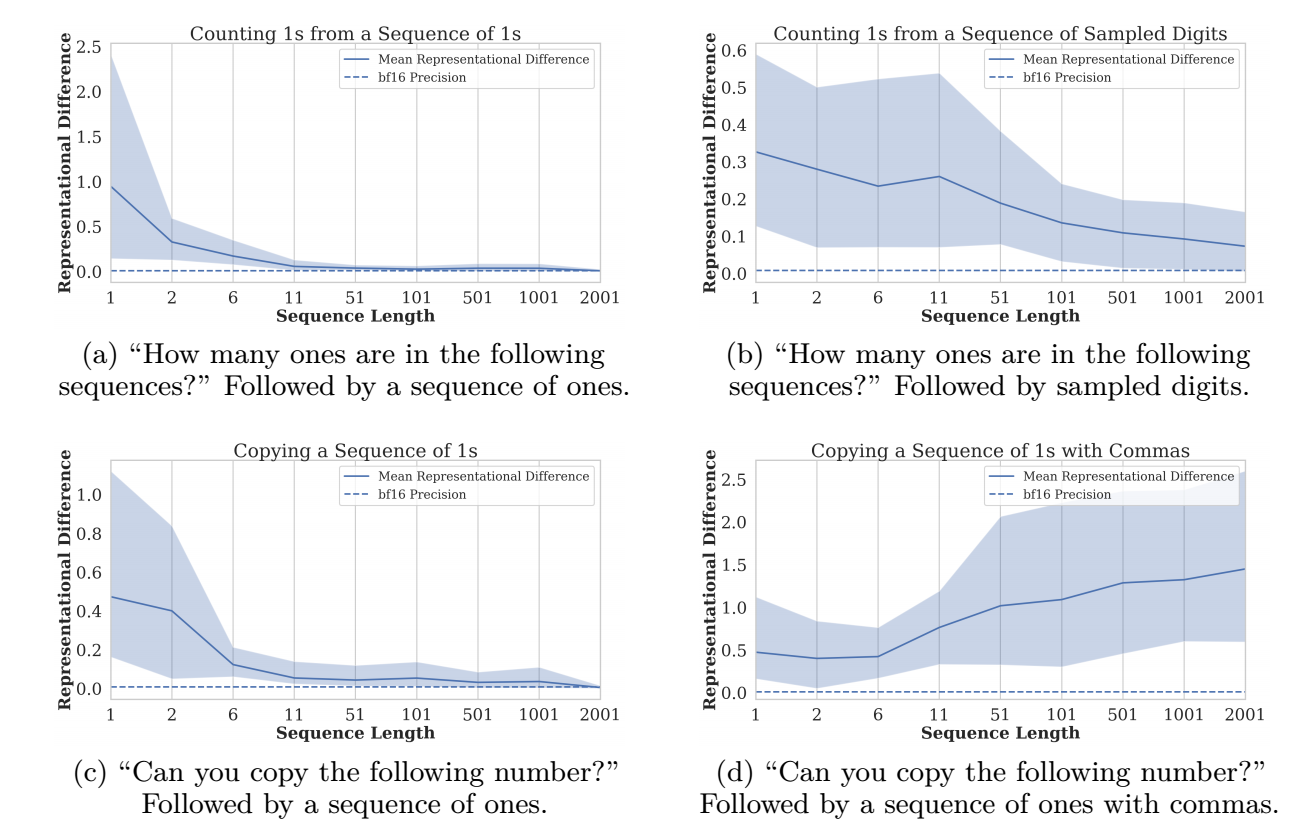
- 作者建议通过增加一些 ‘间隔’ token (如 ‘commas’) 来避免重复 token 上的问题. 但是这个很难直接从上述的理论分析得出吧, 从实验上倒是能够 get 到一二:
Seq-VCR
- Seq-VCR [2] 为了解决这个问题, 提出了一些方法用于增加每个维度的方差, 同时降低不同维度的协方差, 以促进表示的区别性.
参考文献
- Barbero F., Banino A., Kapturowski S., Kumaran D., Araujo J. G. M., Vitvitskyi A., Pascanu R., and Velickovic P. Transformers need glasses! Information Over-Squashing in Language Tasks. NeurIPS, 2024. [PDF] [Code]
- Arefin M. R., Subbaraj G., Gontier N., LeCun Y., Rish I., Shwartz-Ziv R., and Pal C. Seq-VCR: Preventing Collapse in Intermediate Transformer Representations for Enhanced Reasoning. ICLR, 2025. [PDF] [Code]