Markov Chain Estimation with In-Context Learning
预备知识
(Markov Chain) 对于序列 $\mathcal{X} = [x_1, x_2, \ldots, x_T] \subset \mathcal{S} = \{s_k\}_{k=1}^K$, 我们称其为马尔可夫链, 若:
$$ \mathbb{P}(x_{t+1}|x_1, \ldots, x_t) = \mathbb{P}(x_{t+1}|x_t), \forall t. $$即下一状态的发生仅和当前状态有关.
(转移概率矩阵) 马氏链可以通过状态空间 $\mathcal{S}$ 及其之上的定义的转移概率矩阵决定:
$$ P = [P_{ij} = \mathbb{P}(s_j| s_i)]_{i=1, j=1}^{i=K, j=K}. $$(In-Context Learning) Transformer 已经被证明其无与伦比的序列建模能力. 此外, 它的 In-Context Learning 能力也令人印象深刻, 即我们可以加入一些 Context (一些例子) 来暗示 Transformer 应该以什么方式做什么任务.
核心思想
本文想要进一步观察 Transformer 在这方面的能力. 以马氏链为例, 假设 Transformer 已经在一些马氏链上通过 Next-Token Loss 进行了训练, 那么是否 Transformer 可能预测那些不曾见过的马氏链的转移概率呢? 这相当于 Transformer 在推理过程中, 就完成了一个马氏链的在线估计任务.
(训练数据) 我们有 $N$ 类马氏链采样自:
$$ P_i \sim \text{Dir}(\alpha), $$这里 $\text{Dir}(\cdot)$ 表示 Dirichlet 分布. 然后训练集定义为:
$$ \mathcal{A}_N = \{\mathcal{X} \sim P_{i \text{ mod } N}\}_{1 \le i \le n}. $$(评估):
Loss: 用交叉熵损失评估:
$$ \tag{1} L(\theta) = \frac{1}{T} \sum_{i=1}^T l (f_{\theta}(\{x_1, \ldots, x_i\}), x_{i+1}). $$Oracle: 直接用真实的 $P$ 计算:
$$ \tag{2} L(\theta) = \frac{1}{T} \sum_{i=1}^T l (P_{ij}, x_{i+1}). $$Estimated: 通过 $\{x_1, \ldots, x_T\}$ 可以直接估计转移概率:
$$ \hat{P}_{ij} = \frac{c_{ij} + \alpha}{N_i + K \alpha}. $$这里 $c_{ij}$ 是 $s_i \rightarrow s_j$ 的出现次数, 而 $N_i$ 是 $s_i$ 的出现次数. 由此, 我们可以得到就估计的交叉熵 loss:
$$ \tag{3} L(\theta) = \frac{1}{M} \sum_{i=T - M}^M l (\hat{P}_{ij}, x_{i+1}). $$
比较 (1) (2) (3) 的差别, 可以判断 Transformer 在转移概率的估计上是否准确.
(Embedding) 我们当然可以像一般的 Transformer 那样采取 learnable 的 Embeddings, 但是这种方式就不能推广到更多的状态情况了. 因此, 本文研究了一种动态的 Embedding 策略:
$$ X_i = E_{x_i}', \\ E' = \text{QR}(E), \\ E \in \mathbb{R}^{K \times d} \sim \mathcal{N}(0, I). $$即从正态分布中随机采样, 然后正交化得到对应的 Embedding. 如此依赖可以很方便地进行推广.
实验结果
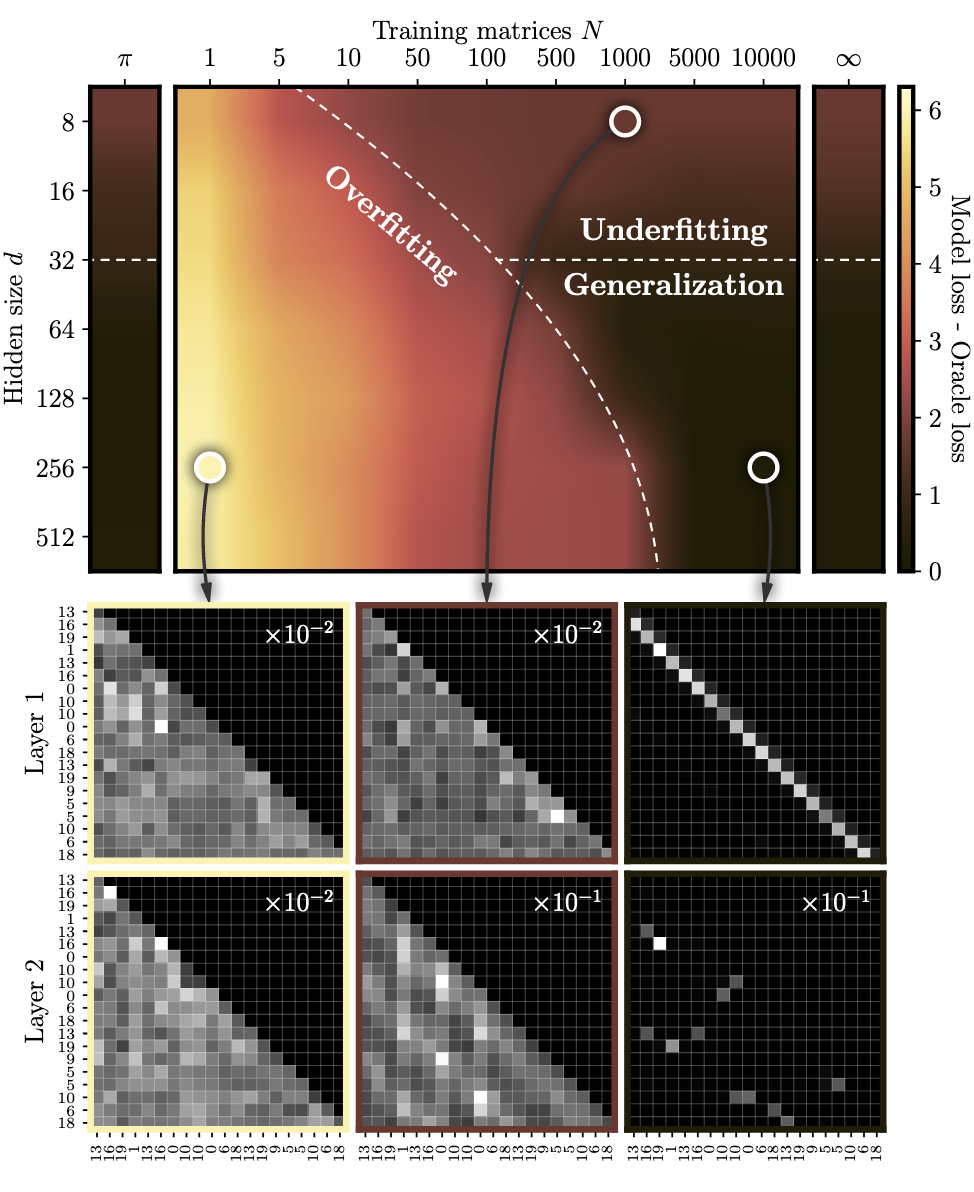
- 上图展示了随着马氏链的数量 $N$ 和 Embedding Size $d$ 的增加, 结果的变化情况. Top Panel 的颜色深浅表示的是 (1) - (2) 的大小, 颜色越深表示差异越小, 即对于转移概率估计的越准确. 结论显然是, 想要有足够的泛化能力, 需要充分的数据和表达能力.
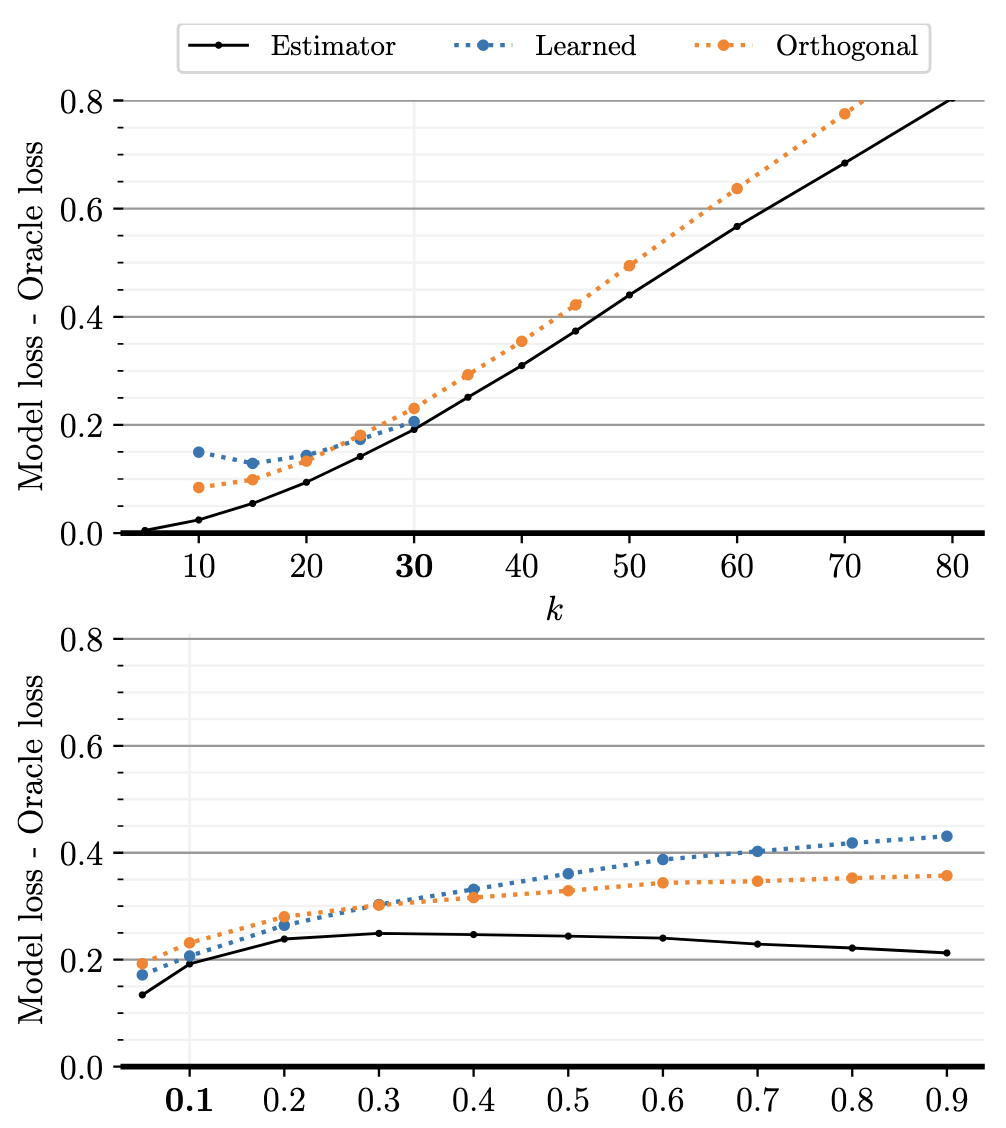
- 此外, 我们可以观察随着状态数目 $k$ 增加或者减少, 结果的变化情况. 可以发现, learnable embeddings, 一方面不能推广到更多的状态上, 另一方面, 在更少的状态数目上的泛化性也很一般. 而采用正交的 Embedding 则效果就好很多. 对于先验 $\alpha$ 类似.
个人测试
Loss 的变化曲线
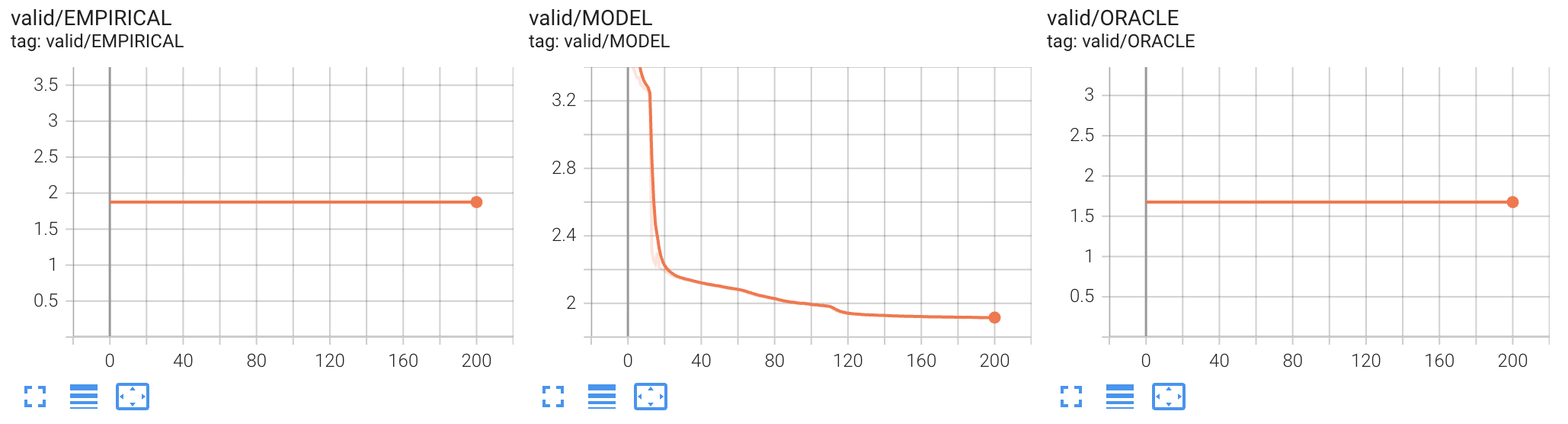
- 按照作者的建议的配置, 跑了 1000 epochs (每个 epoch 有 10000 条序列). 基本上, 已经能够到达 Empirical Loss 估计相同的结果了. 换言之, Transformer 在得到充分的数据训练之后, 的的确确展现出了 Markov Chain Estimator 的泛化能力.
Max_NUM_States
- 训练采用固定的 $K=30$ States, 测试的时候采用从 $30\sim \text{Max\_NUM\_States}$ 中均匀采样:
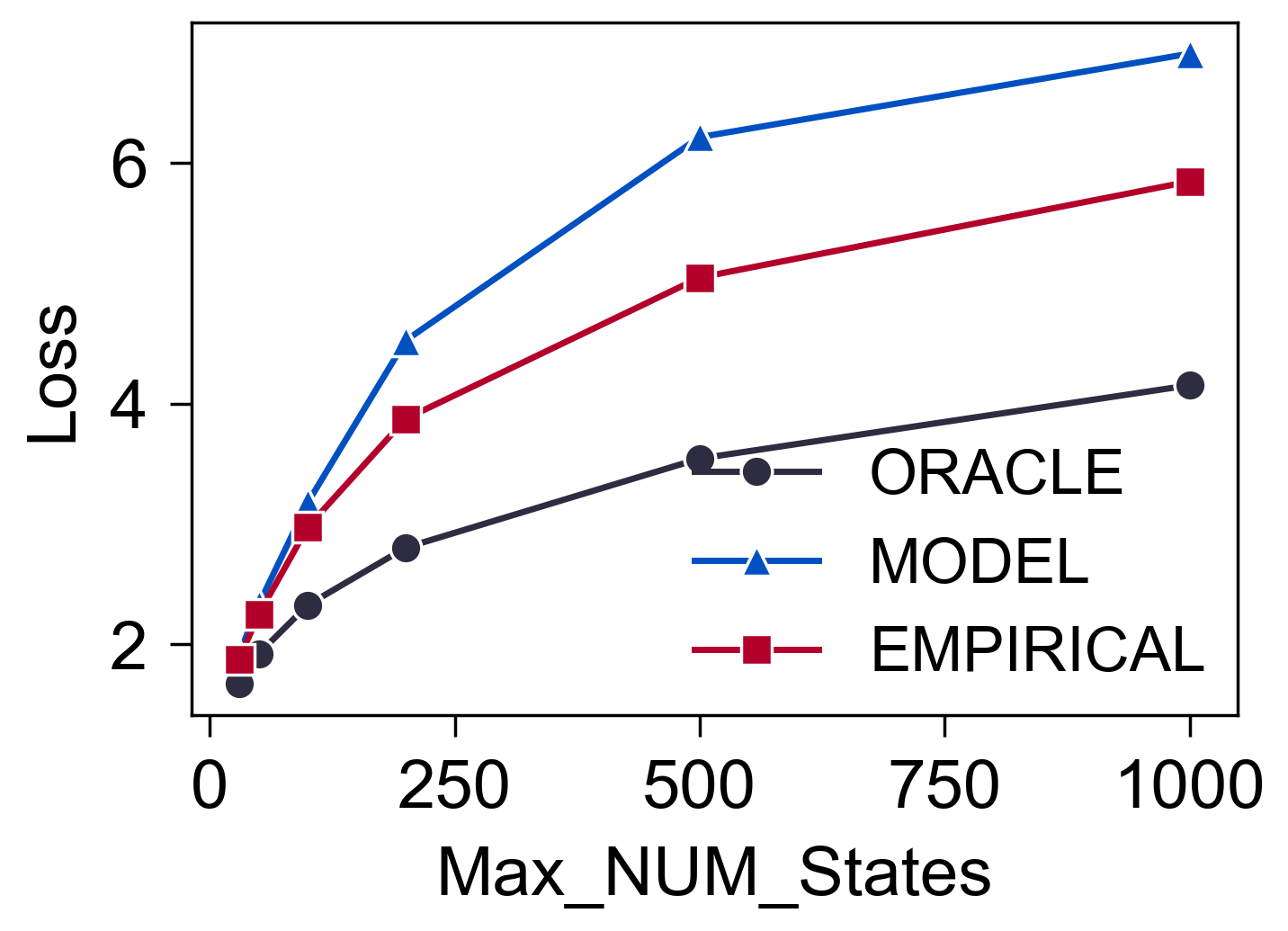
虽然整体来说, 随着 States 数量的增加, 差距是越发明显的, 但是其实还好, 完全可以接受的感觉.
此外, 我发现即使在训练过程就增加 Max_NUM_States, 其效果反而比不上只在
Max_NUM_States=30上的训练泛化性好.
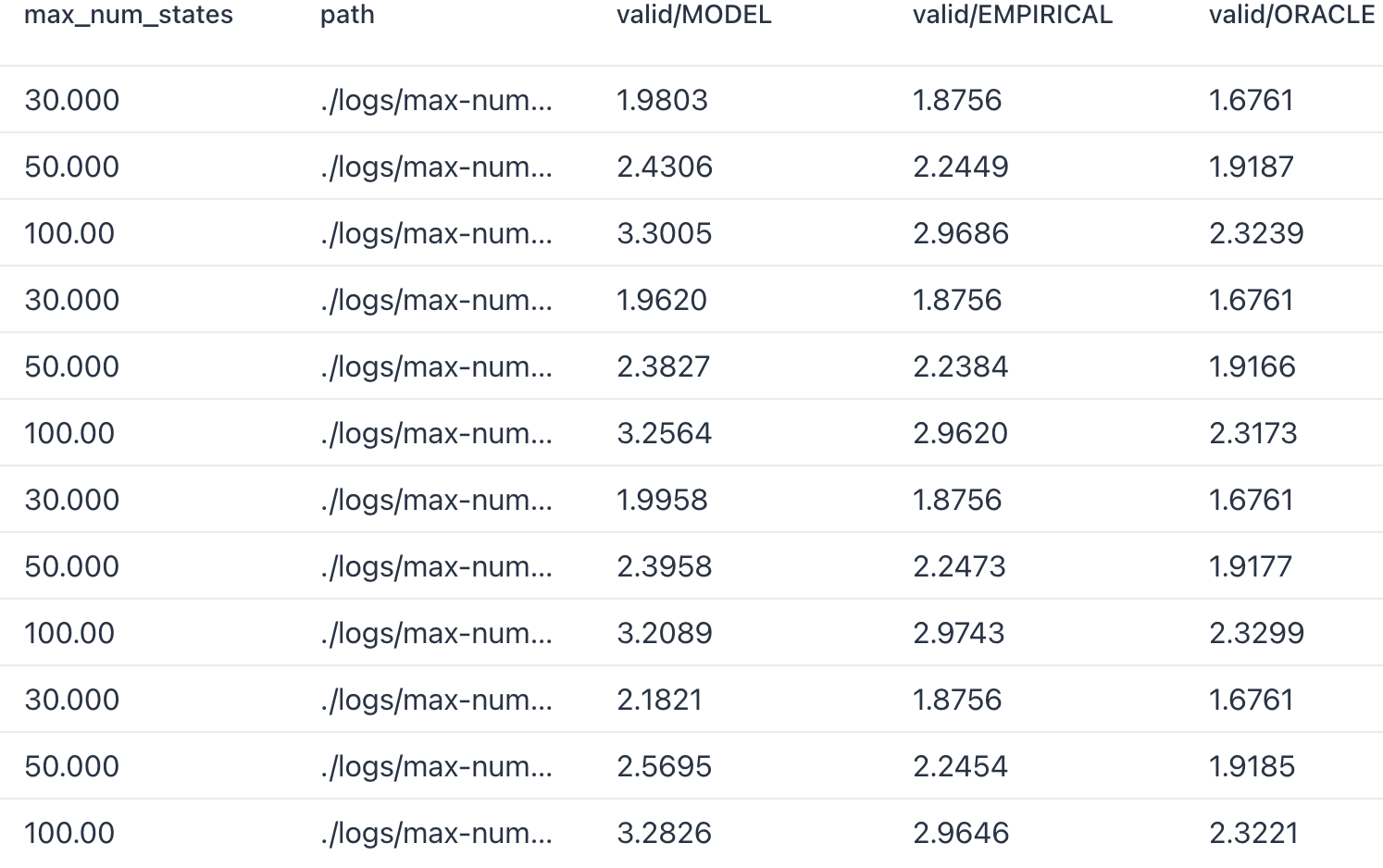
- 如上图所示, 每三个一组, 分别是
Max_NUM_States=20,30,50,100, 可以发现, 训练的时候加入更多的 States 的场景, 其实并没有增加其在对应 Case 上的提升.
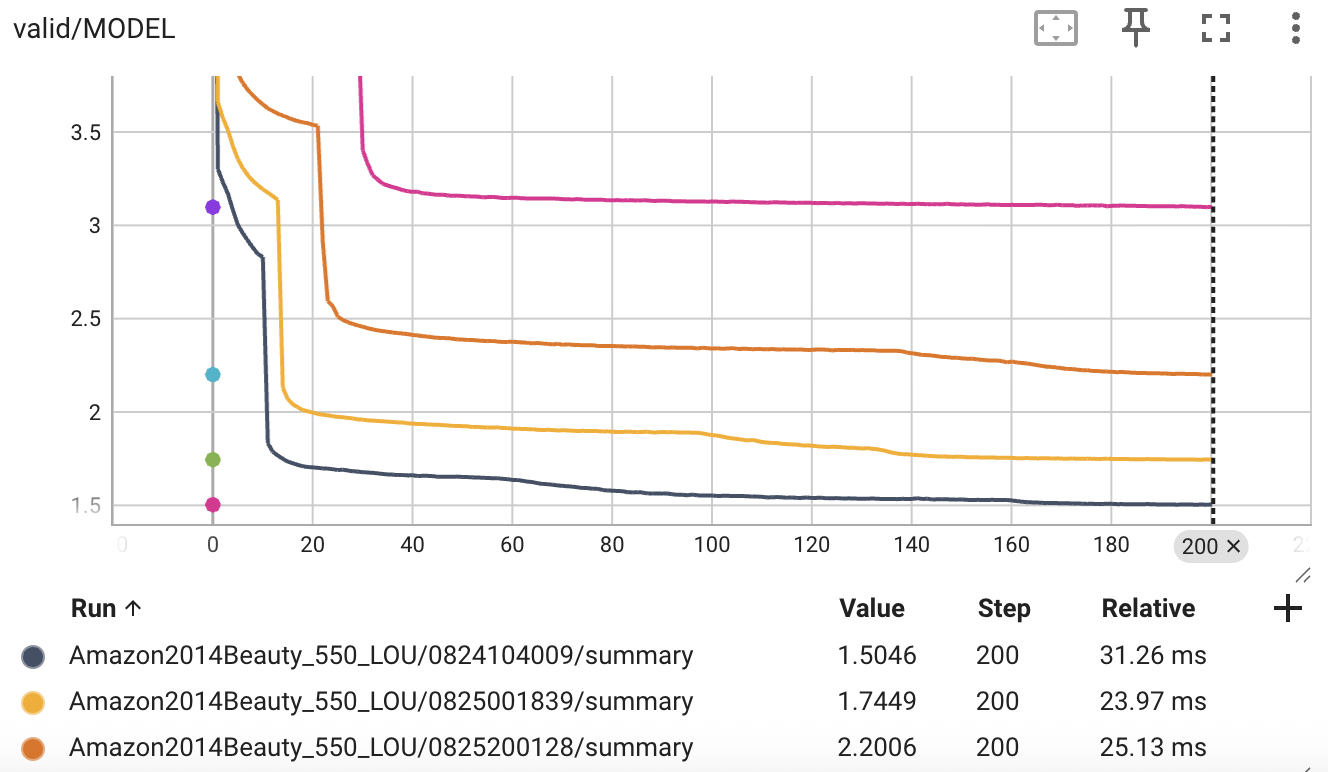
- 如上图所示, 曲线从上到下对应
max_num_states逐步降低, 容易发现, 下面几个基本上有那么两三次的突然下降, 对于max_num_states=100的情况, 直到训练结束也没有, 这可能是效果较差的原因.
minlen
- 训练采用固定的序列长度 $1000$, 测试的时候, 从 $\text{minlen} \sim 1000$ 中随机采样.
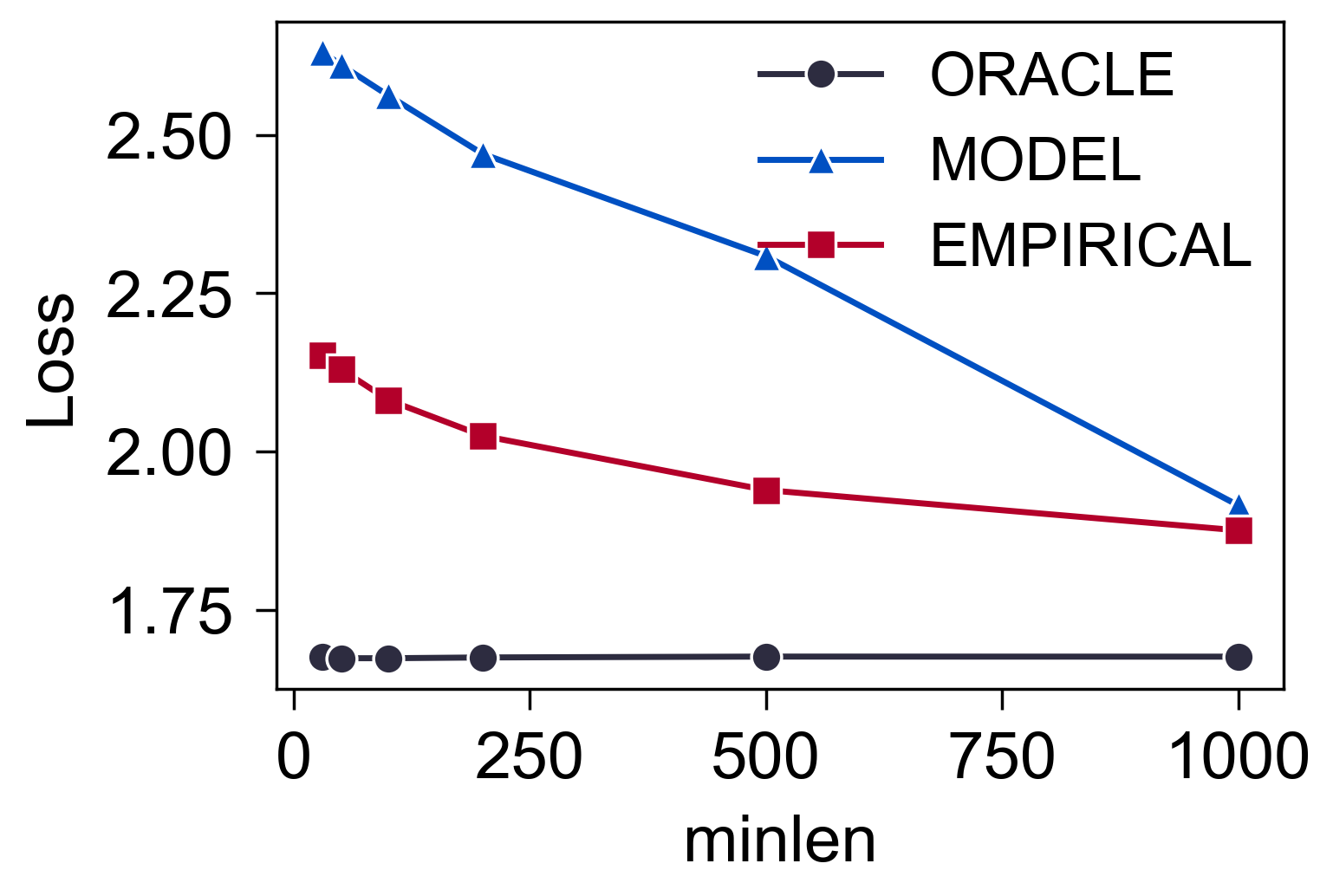
- 显然, 当 minlen 降低的时候, 估计的效果是越来越差的, 而且差距还是比较明显的. 不清楚这个根源是不是由于训练的时候固定采样序列长度为 1000 了 (但是, 其实 Next-Token 的预测方式其实也涉及到了短序列的信息). 这一块需要进一步调研, 否则想要用在短序列中还是有些难度.
alpha
- 训练的时候固定 $\alpha=0.1$, 测试不同 $\alpha$ 下的情况.
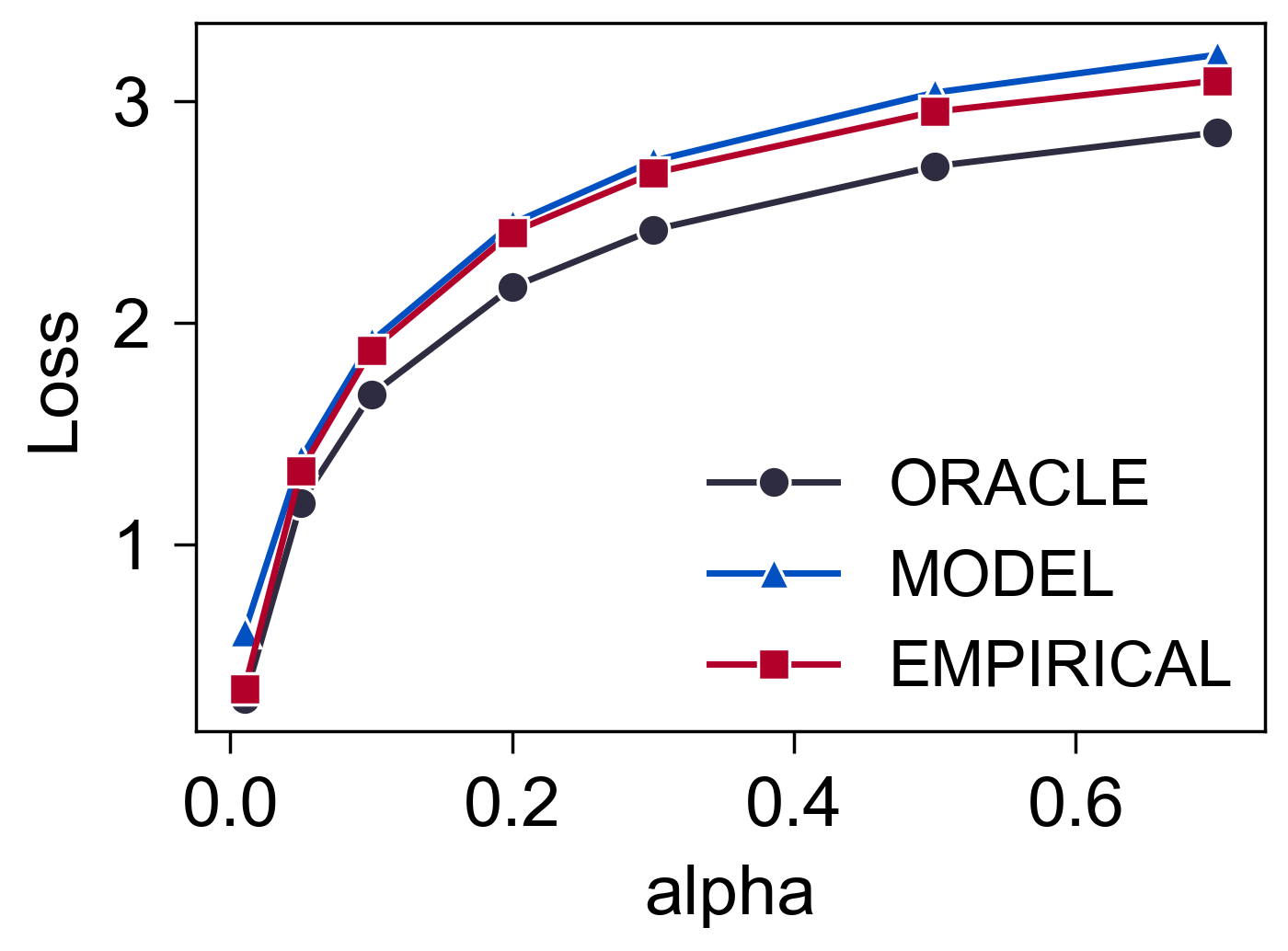
- 结果挺好, 很稳定.
代码
# main.py
from typing import Dict, Tuple, Union
import torch
import freerec
from transformers import LlamaModel, LlamaConfig
from einops import rearrange
from sampler import TrainRandomWalkSource, ValidRandomWalkSource, CUTS
freerec.declare(version='1.0.1')
cfg = freerec.parser.Parser()
cfg.add_argument("--alpha", type=float, default=0.1)
cfg.add_argument("--min-num-states", type=int, default=30)
cfg.add_argument("--max-num-states", type=int, default=30)
cfg.add_argument("--minlen", type=int, default=1000)
cfg.add_argument("--maxlen", type=int, default=1000)
cfg.set_defaults(
description="Markov",
root="../../data",
dataset='Amazon2014Beauty_550_LOU',
epochs=1000,
batch_size=500,
optimizer='AdamW',
lr=3e-4,
weight_decay=0.01,
which4best="Model",
seed=1,
)
cfg.compile()
cfg.llama_config = LlamaConfig(
vocab_size=0,
hidden_size=256,
intermediate_size=256,
num_hidden_layers=4,
num_attention_heads=2,
max_position_embeddings=cfg.maxlen,
tie_word_embeddings=True,
attention_dropout=0.
)
class MarkovICL(freerec.models.SeqRecArch):
def __init__(
self, dataset: freerec.data.datasets.RecDataSet,
) -> None:
super().__init__(dataset)
self.model = LlamaModel(cfg.llama_config)
self.criterion = freerec.criterions.CrossEntropy4Logits(reduction='mean')
self.reset_parameters()
def reset_parameters(self): ...
def sure_trainpipe(self):
return TrainRandomWalkSource(
self.dataset.train(),
datasize=10000,
alpha=cfg.alpha,
min_num_states=cfg.min_num_states,
max_num_states=cfg.max_num_states,
minlen=cfg.minlen,
maxlen=cfg.maxlen,
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.IPos)
).lpad_(
cfg.maxlen, modified_fields=(self.ISeq, self.IPos),
padding_value=self.PADDING_VALUE
).batch_(cfg.batch_size).tensor_()
def sure_validpipe(self):
return ValidRandomWalkSource(
self.dataset.valid(),
datasize=10000,
alpha=cfg.alpha,
min_num_states=cfg.min_num_states,
max_num_states=cfg.max_num_states,
minlen=cfg.minlen,
maxlen=cfg.maxlen,
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.IPos)
).lpad_(
cfg.maxlen, modified_fields=(self.ISeq, self.IPos),
padding_value=self.PADDING_VALUE
).batch_(cfg.batch_size).tensor_()
def sure_testpipe(self):
return ValidRandomWalkSource(
self.dataset.test(),
datasize=10000,
alpha=cfg.alpha,
min_num_states=cfg.min_num_states,
max_num_states=cfg.max_num_states,
minlen=cfg.minlen,
maxlen=cfg.maxlen,
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.IPos)
).lpad_(
cfg.maxlen, modified_fields=(self.ISeq, self.IPos),
padding_value=self.PADDING_VALUE
).batch_(cfg.batch_size).tensor_()
# @staticmethod
# def _ortho_vocab(B, V, D, device):
# _d = D // 2
# # Batched random orthogonal embeddings
# emb_dict = torch.randn(B, max(V, _d), _d, dtype=torch.float32, device=device)
# emb_dict, _ = torch.linalg.qr(emb_dict)
# emb_dict = emb_dict[:, :V, :_d] # V vectors of size D
# # Now pad with zeros : B x V x D -> B x V x 2D
# emb_dict = torch.cat([emb_dict, torch.zeros(B, V, _d, device=device)], dim=-1)
# return emb_dict
@staticmethod
def _ortho_vocab(B, V, D, device):
_d = D
# _d = D // 2
# Batched random orthogonal embeddings
emb_dict = torch.randn(B, max(V, _d), _d, dtype=torch.float32, device=device)
emb_dict, _ = torch.linalg.qr(emb_dict)
emb_dict = emb_dict[:, :V, :_d] # V vectors of size D
# emb_dict = torch.cat(
# (emb_dict, torch.zeros_like(emb_dict)), dim=-1
# )
return emb_dict
def encode(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
chains = data[self.ISeq]
B, S = chains.shape
voc = self._ortho_vocab(
B=B, V=chains.max() + 1,
D=self.model.config.hidden_size,
device=self.device
)
row_index = torch.arange(chains.shape[0], device=self.device)
row_index = row_index.view(-1, 1)
emb = voc[row_index, chains]
out = self.model(inputs_embeds=emb, output_attentions=False)
return out.last_hidden_state, voc
def fit(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
hiddens, voc = self.encode(data)
indices = data[self.ISeq] != self.PADDING_VALUE
logits = torch.einsum("BMD,BND->BMN", hiddens, voc) # (B, M, N)
logits = logits[indices]
labels = data[self.IPos][indices] # (*,)
rec_loss = self.criterion(logits, labels)
return rec_loss
def recommend_from_full(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
hiddens, voc = self.encode(data)
hiddens = hiddens[:, -CUTS:, :]
target = data[self.IPos][:, -CUTS:] # (B, M)
logits = torch.einsum("BMD,BND->BMN", hiddens, voc) # (B, M, N)
logits = rearrange(logits, "B M N -> B N M")
return self.criterion(logits, target), data['empirical'].mean().item(), data['oracle'].mean().item()
class CoachForMarkov(freerec.launcher.Coach):
def train_per_epoch(self, epoch: int):
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.monitor(
loss.item(),
n=data[self.Size], reduction="mean",
mode='train', pool=['LOSS']
)
def set_other(self):
self.register_metric(
"MODEL", lambda x: x, best_caster=min
)
self.register_metric(
"EMPIRICAL", lambda x: x, best_caster=min
)
self.register_metric(
"ORACLE", lambda x: x, best_caster=min
)
def evaluate(self, epoch: int, step: int = -1, mode: str = 'valid'):
for data in self.dataloader:
bsz = data[self.Size]
data = self.dict_to_device(data)
model_loss, empirical_loss, oracle_loss = self.model(data, ranking='full')
self.monitor(
model_loss,
n=bsz, reduction="mean", mode=mode,
pool=['Model']
)
self.monitor(
empirical_loss,
n=bsz, reduction="mean", mode=mode,
pool=['EMPIRICAL']
)
self.monitor(
oracle_loss,
n=bsz, reduction="mean", mode=mode,
pool=['ORACLE']
)
def main():
dataset: freerec.data.datasets.RecDataSet
try:
dataset = getattr(freerec.data.datasets, cfg.dataset)(root=cfg.root)
except AttributeError:
dataset = freerec.data.datasets.RecDataSet(cfg.root, cfg.dataset, tasktag=cfg.tasktag)
model = MarkovICL(dataset)
# datapipe
trainpipe = model.sure_trainpipe()
validpipe = model.sure_validpipe()
testpipe = model.sure_testpipe()
coach = CoachForMarkov(
dataset=dataset,
trainpipe=trainpipe,
validpipe=validpipe,
testpipe=testpipe,
model=model,
cfg=cfg
)
coach.fit()
if __name__ == "__main__":
main()
# sampler.py
from typing import Iterable, Dict, Any, List
import numpy as np
import random
from freerec.data.tags import ITEM, ID, SEQUENCE, POSITIVE
from freerec.data.datasets.base import RecDataSet
from freerec.data.postprocessing.base import Source
from freerec.data.postprocessing.source import OrderedSource
CUTS = 20
class TrainRandomWalkSource(Source):
def __init__(
self, dataset: RecDataSet, datasize: int,
alpha: float = 0.1,
min_num_states: int = 30, max_num_states: int = 30,
minlen: int = 1000, maxlen: int = 1000
) -> None:
super().__init__(dataset, tuple(), datasize, shuffle=False)
self._rng = random.Random()
self.alpha = alpha
self.min_num_states = max(min_num_states, CUTS)
self.max_num_states = max_num_states
self.minlen = minlen
self.maxlen = maxlen
self.Item = self.fields[ITEM, ID]
self.ISeq = self.Item.fork(SEQUENCE)
self.IPos = self.Item.fork(POSITIVE)
def sample_transition_matrix(self, num_states: int) -> np.ndarray:
return np.random.dirichlet([self.alpha] * num_states, size=num_states)
def sample_num_states(self):
return self._rng.randint(self.min_num_states, self.max_num_states)
def sample_chain_length(self):
return self._rng.randint(self.minlen, self.maxlen)
def estimate_transition_probability(self, chain: List[int], num_states: int):
counts = np.zeros((num_states,))
chain, x = chain[:-1], chain[-1]
positions = np.where(chain == x)[0][:-1]
positions += 1
vals = chain[positions]
np.add.at(counts, vals, 1)
return (counts + self.alpha) / (counts.sum() + self.alpha * num_states)
def cross_entropy_from_probs(self, probs: np.array, target: np.ndarray):
# probs: (CUTS, NUM_STATES)
probs[probs == 0] = 1.e-8
target = target.copy()[:, None]
probs = np.take_along_axis(probs, target, axis=1)
return np.mean(-np.log(probs)).item()
def sample_chain(self) -> List[int]:
k = self.sample_num_states()
P = self.sample_transition_matrix(num_states=k)
n = self.sample_chain_length()
cprobs = P.cumsum(axis=1)
rands = np.random.rand(n)
chain = np.zeros(n, dtype=int)
for i in range(1, n):
chain[i] = np.searchsorted(cprobs[chain[i - 1]], rands[i])
seq, target = chain[:-1], chain[1:]
s = len(seq) - CUTS
estimation = np.stack([
self.estimate_transition_probability(
seq[:s+i], k
)
for i in range(1, CUTS + 1)
], axis=0)
oracle = np.stack([
P[seq[s+i]]
for i in range(CUTS)
], axis=0)
empirical_loss = self.cross_entropy_from_probs(estimation, target[-CUTS:])
oracle_loss = self.cross_entropy_from_probs(oracle, target[-CUTS:])
return seq.tolist(), target.tolist(), empirical_loss, oracle_loss
def __iter__(self):
for _ in self.launcher:
seq, target, empirical, oracle = self.sample_chain()
yield {
self.ISeq: seq, self.IPos: target,
'empirical': empirical,
'oracle': oracle
}
class ValidRandomWalkSource(OrderedSource):
def __init__(
self, dataset: RecDataSet, datasize: int,
alpha: float = 0.1,
min_num_states: int = 30, max_num_states: int = 30,
minlen: int = 1000, maxlen: int = 1000
) -> None:
source = TrainRandomWalkSource(
dataset, datasize, alpha, min_num_states, max_num_states, minlen, maxlen
)
super().__init__(dataset, list(source))
# test.py
from typing import Dict, Tuple, Union
import torch
import freerec
from transformers import LlamaModel, LlamaConfig
from einops import rearrange
from sampler import TrainRandomWalkSource, ValidRandomWalkSource, CUTS
freerec.declare(version='1.0.1')
cfg = freerec.parser.Parser()
cfg.add_argument("--path", type=str, default="./logs/Markov/Amazon2014Beauty_550_LOU/0817134602")
cfg.add_argument("--alpha", type=float, default=0.1)
cfg.add_argument("--min-num-states", type=int, default=30)
cfg.add_argument("--max-num-states", type=int, default=30)
cfg.add_argument("--minlen", type=int, default=1000)
cfg.add_argument("--maxlen", type=int, default=1000)
cfg.set_defaults(
description="Markov",
root="../../data",
dataset='Amazon2014Beauty_550_LOU',
epochs=1000,
batch_size=500,
optimizer='AdamW',
lr=3e-4,
weight_decay=0.01,
which4best="Model",
seed=1,
)
cfg.compile()
cfg.epochs = 1
cfg.llama_config = LlamaConfig(
vocab_size=0,
hidden_size=256,
intermediate_size=256,
num_hidden_layers=4,
num_attention_heads=2,
max_position_embeddings=cfg.maxlen,
tie_word_embeddings=True,
attention_dropout=0.
)
class MarkovICL(freerec.models.SeqRecArch):
def __init__(
self, dataset: freerec.data.datasets.RecDataSet,
) -> None:
super().__init__(dataset)
self.model = LlamaModel(cfg.llama_config)
self.criterion = freerec.criterions.CrossEntropy4Logits(reduction='mean')
self.reset_parameters()
def reset_parameters(self): ...
def sure_trainpipe(self):
return TrainRandomWalkSource(
self.dataset.train(),
datasize=10000,
alpha=cfg.alpha,
min_num_states=cfg.min_num_states,
max_num_states=cfg.max_num_states,
minlen=cfg.minlen,
maxlen=cfg.maxlen,
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.IPos)
).lpad_(
cfg.maxlen, modified_fields=(self.ISeq, self.IPos),
padding_value=self.PADDING_VALUE
).batch_(cfg.batch_size).tensor_()
def sure_validpipe(self):
return ValidRandomWalkSource(
self.dataset.valid(),
datasize=10000,
alpha=cfg.alpha,
min_num_states=cfg.min_num_states,
max_num_states=cfg.max_num_states,
minlen=cfg.minlen,
maxlen=cfg.maxlen,
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.IPos)
).lpad_(
cfg.maxlen, modified_fields=(self.ISeq, self.IPos),
padding_value=self.PADDING_VALUE
).batch_(cfg.batch_size).tensor_()
def sure_testpipe(self):
return ValidRandomWalkSource(
self.dataset.test(),
datasize=10000,
alpha=cfg.alpha,
min_num_states=cfg.min_num_states,
max_num_states=cfg.max_num_states,
minlen=cfg.minlen,
maxlen=cfg.maxlen,
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.IPos)
).lpad_(
cfg.maxlen, modified_fields=(self.ISeq, self.IPos),
padding_value=self.PADDING_VALUE
).batch_(cfg.batch_size).tensor_()
@staticmethod
def _ortho_vocab(B, V, D, device):
_d = D // 2
# Batched random orthogonal embeddings
emb_dict = torch.randn(B, max(V, _d), _d, dtype=torch.float32, device=device)
emb_dict, _ = torch.linalg.qr(emb_dict)
emb_dict = emb_dict[:, :V, :_d] # V vectors of size D
# Now pad with zeros : B x V x D -> B x V x 2D
emb_dict = torch.cat([emb_dict, torch.zeros(B, V, _d, device=device)], dim=-1)
return emb_dict
def encode(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
chains = data[self.ISeq]
B, S = chains.shape
voc = self._ortho_vocab(
B=B, V=chains.max() + 1,
D=self.model.config.hidden_size,
device=self.device
)
row_index = torch.arange(chains.shape[0], device=self.device)
row_index = row_index.view(-1, 1)
emb = voc[row_index, chains]
out = self.model(inputs_embeds=emb, output_attentions=False)
return out.last_hidden_state, voc
def fit(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
hiddens, voc = self.encode(data)
indices = data[self.ISeq] != self.PADDING_VALUE
logits = torch.einsum("BMD,BND->BMN", hiddens, voc) # (B, M, N)
logits = logits[indices]
labels = data[self.IPos][indices] # (*,)
rec_loss = self.criterion(logits, labels)
return rec_loss
def recommend_from_full(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
hiddens, voc = self.encode(data)
hiddens = hiddens[:, -CUTS:, :]
target = data[self.IPos][:, -CUTS:] # (B, M)
logits = torch.einsum("BMD,BND->BMN", hiddens, voc) # (B, M, N)
logits = rearrange(logits, "B M N -> B N M")
return self.criterion(logits, target), data['empirical'].mean().item(), data['oracle'].mean().item()
class CoachForMarkov(freerec.launcher.Coach):
def train_per_epoch(self, epoch: int):
...
def set_other(self):
self.register_metric(
"MODEL", lambda x: x, best_caster=min
)
self.register_metric(
"EMPIRICAL", lambda x: x, best_caster=min
)
self.register_metric(
"ORACLE", lambda x: x, best_caster=min
)
def evaluate(self, epoch: int, step: int = -1, mode: str = 'valid'):
for data in self.dataloader:
bsz = data[self.Size]
data = self.dict_to_device(data)
model_loss, empirical_loss, oracle_loss = self.model(data, ranking='full')
self.monitor(
model_loss,
n=bsz, reduction="mean", mode=mode,
pool=['Model']
)
self.monitor(
empirical_loss,
n=bsz, reduction="mean", mode=mode,
pool=['EMPIRICAL']
)
self.monitor(
oracle_loss,
n=bsz, reduction="mean", mode=mode,
pool=['ORACLE']
)
def main():
dataset: freerec.data.datasets.RecDataSet
try:
dataset = getattr(freerec.data.datasets, cfg.dataset)(root=cfg.root)
except AttributeError:
dataset = freerec.data.datasets.RecDataSet(cfg.root, cfg.dataset, tasktag=cfg.tasktag)
model = MarkovICL(dataset)
# datapipe
trainpipe = model.sure_trainpipe()
validpipe = model.sure_validpipe()
testpipe = model.sure_testpipe()
coach = CoachForMarkov(
dataset=dataset,
trainpipe=trainpipe,
validpipe=validpipe,
testpipe=testpipe,
model=model,
cfg=cfg
)
coach.load(cfg.path, filename="best.pt")
coach.fit()
if __name__ == "__main__":
main()