MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
预备知识
- 传统的语言模型依赖 Subword Tokenizer (e.g., SentencePiece) 将词转换为 Token.
核心思想
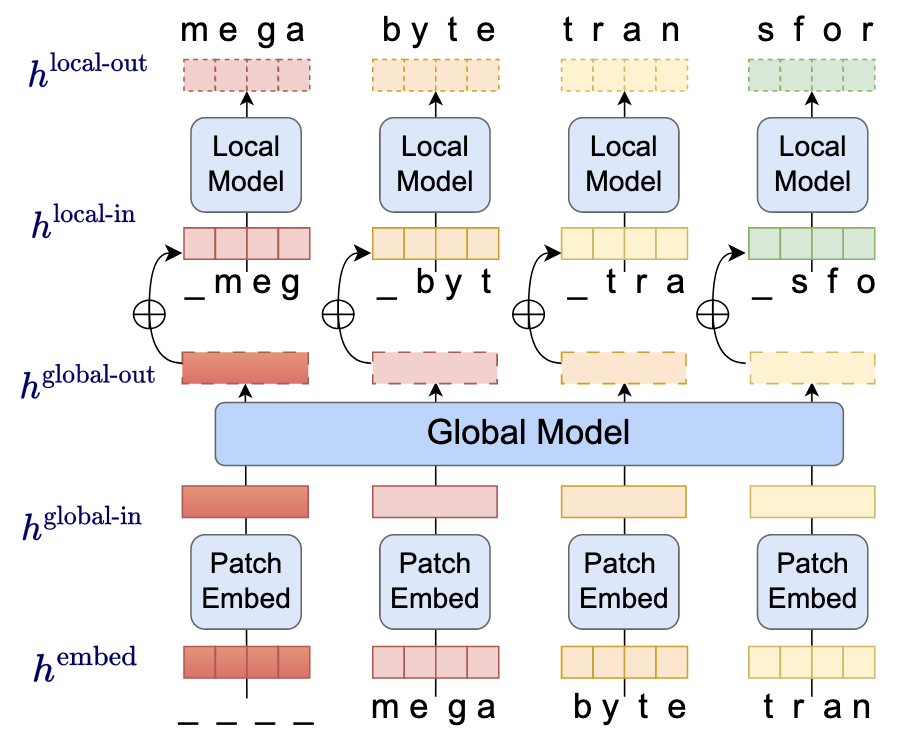
传统的语言模型依赖 Subword Tokenizer (e.g., SentencePiece) 将词转换为 Token. 显然, 受限于 Tokenizer 的设计, Transformer 可能没法处理一些不常见的’符号系统’. 此外, 作者还认为, 现有的模型依然被诟病于 $\mathcal{O}(n^2)$ 的 attention 复杂度 ($n$ 为序列长度).
本文提出的 MegaByte 是对传统 Transformer 的一个颠覆性的改进:
抛弃 Subword tokenizer, 直接每个符号作为一个 Token, 从而能够更好地兼容不同符号系统 (e.g., 可以完全采用 UTF-8 编码)
采取多尺度的 Attention 机制: Token 序列每 $P$ 个窗口大小进行切块. 首先进行 Patch 间的 global (attention) 交互, 得到的表示和 patch 内的 token 一起进行局部的 (attention) 交互, 因而实现 超并行的 解码. 此外, 通过设计合理的 $P$ 能够保证 global/local 的序列长度都能得到控制.

除此之外, 作者还讨论了滑动窗口的设计, local 部分推理是否需要覆盖一些跨 token 的设计等.
正如作者所说, MegaByte 不考虑 Local, 整体的设计很像 ViT, 因此 MegaByte 能够很容易的应用到非自然语言的任务中去. 不过这一点或许也会制约它在传统 NLP 任务上的效果.