Multimodal Pre-training for Sequential Recommendation via Contrastive Learning
预备知识
- $\mathcal{S} = \{i_1, i_2, \ldots, i_n\}$, user behavior sequence;
- $\mathcal{T}_i = \{t_1^i, t_2^i, \ldots, t_{|\mathcal{T}_i|}^i\}$, item $i$ 的文本描述 ($t_j^i$ 可以理解为其中的一个句子);
- $\mathcal{V}_i = \{v_1^i, v_2^i, \ldots, v_{|\mathcal{V}_i|}^i\}$, item $i$ 所对应的图片特征.
核心思想
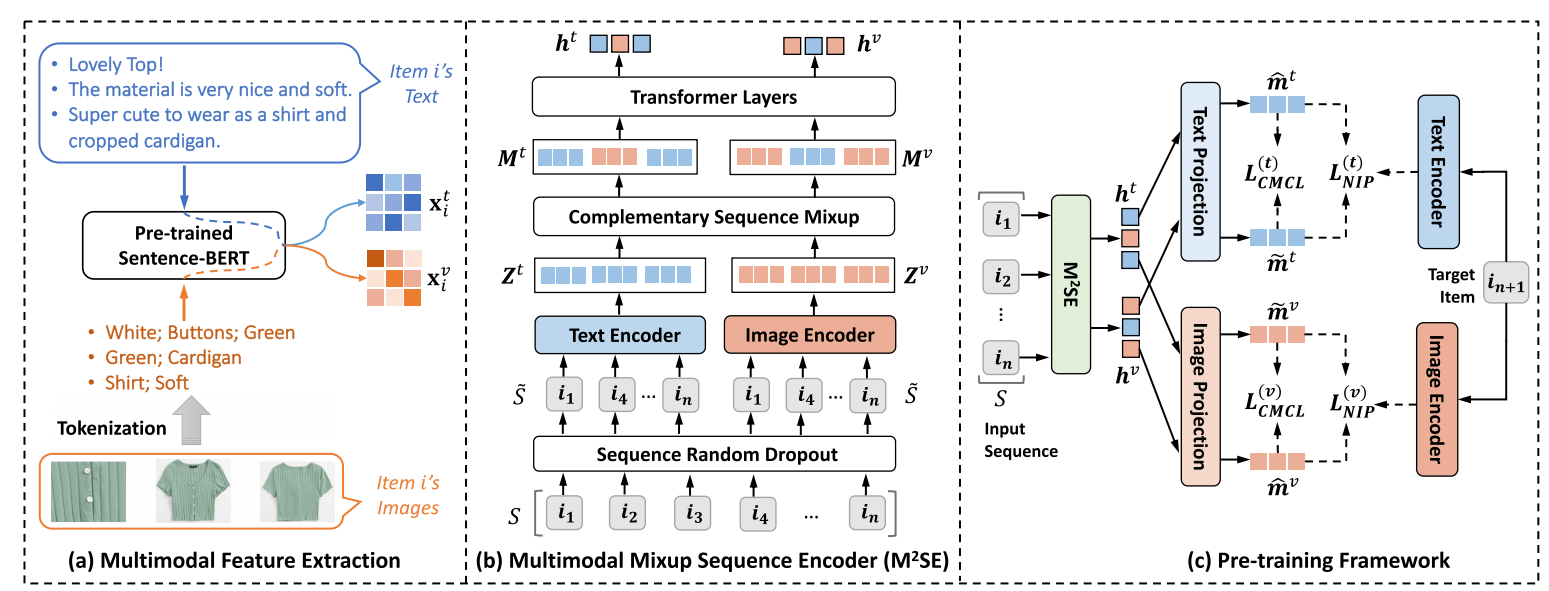
Multimodal Feature Extraction
MP4SR 首先将 item 的文本和图片转换为特征:
- 对于文本, 直接通过 Sentence-BERT 对每个句子进行编码得到:
- 对于图片的转换则较为特殊: 图片 $\overset{\text{CLIP}}{\rightarrow}$ 特征 $\overset{\text{匹配文本Token}}{\rightarrow}$ Top-N 文本 token:
其中 $\mathcal{D}$ 表示整个词表. 所以其实是相当于给图片匹配它所对应的文本描述, 如此一来就省去了图片和文本模态对齐的问题.
Multimodal Mixup Sequence Encoder
- Sequence Random Dropout: 随机的 Dropout, 提取出 $\mathcal{S}$ 的部分子序列 $\tilde{\mathcal{S}}$.
- Text and Image Encoders: 这部分主要是将之前提的特征进行一个融合 (注意每个 item 有多个文本和图片表征). 以文本为例:
然后通过 MoE 进行进一步特征变换, 最终得到整个文本/图片序列表征:
$$ \mathbf{Z}^t = stack[ \mathbf{z}_1^t, \mathbf{z}_2^t, \ldots, \mathbf{z}_{|\mathcal{\tilde{S}}|}^t ], \\ \mathbf{Z}^v = stack[ \mathbf{z}_1^v, \mathbf{z}_2^v, \ldots, \mathbf{z}_{|\mathcal{\tilde{S}}|}^v ]. $$- Complementary Sequence Mixup: 为了进一步抹除两个模态的差异, 以一个 $p \in [0, 0.5]$ 的概率进行 Mixup (两个序列混合), 得到:
- Transformer Layers: 对 $\mathbf{M}^t, \mathbf{M}^v$ 进行特征变化得到最终的表示:
Pre-training Objectives
- 这部分主要涉及两个目标, 其实主要就是对比学习里面正负样本的构建问题:
- Modality-specific Next Item Prediction: 其主要是以 Next-item 的 embeddding 作为正样本, in-batch 内的其它作为负样本;
- Cross-Modality Contrastive Learning: 这部分就是要求文本和图片两部分模态互相对齐, 其余的模态特征为负样本.