On the Markovian Nature of the Next-Item Recommendation Task
黑暗源头
序列推荐是推荐领域一个相当重要的 Topic, 大家都认为通过序列可以有效抓住用户所谓的动态兴趣. 譬如, 最为人所知的 SASRec 是经典的 Next-Item Recommendation:
$$ \begin{align} \hat{v}_{t+1} = \text{argmax}_{v} \: P(v| v_1, v_2, \ldots, v_t). \end{align} $$其中 $v \in \mathcal{V}$ 表示 Item, $\{v_1, v_2, \ldots, v_t\}$ 表示用户的历史交互序列. 换言之, 在这个 setting 下, 用户仅以交互序列代表.
一般来说, SASRec 的输入序列有一个
maxlen的最大序列长度, 理论上来说, 这个值应该是越大越好 (利用到的信息增加了). 然而我最近在多 launchers 的实验中发现, 历史交互序列的 last item $v_t$ 似乎在整个推荐中起到了至关重要的作用. 特此, 我希望探究一下其中的真伪, 探究序列性对于推荐系统究竟意味着什么?
完整序列 $\overset{\text{maxlen} \downarrow}{\longrightarrow}$ Last Item
- 我首先想探究
maxlen的影响, 但是一般的 SASRec 的实现采用的是并行的预测, 即此时maxlen不仅决定了 inference 时候所用到的信息, 也决定了训练数据大小. 为了控制变量, 我会将用户序列进行一个切分, 具体的数据集的构造代码如下:
def sure_trainpipe(self, maxlen: int, batch_size: int):
return self.dataset.train().shuffled_roll_seqs_source(
minlen=cfg.minlen, maxlen=50, # maxlen: 50 for Beauty; 100 for ML-1M
keep_at_least_itself=True
).lprune_(
maxlen=maxlen + 1, modified_fields=(self.ISeq,)
).seq_train_yielding_pos_(
start_idx_for_target=-1, end_idx_for_input=-1
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq,)
).lpad_(
maxlen, modified_fields=(self.ISeq,),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
比如对于 $[v_1, v_2, v_3, v_4, v_5]$,
$$ \begin{align} [v_1] \rightarrow v_2, \\ [v_1, v_2] \rightarrow v_3, \\ [v_2, v_3] \rightarrow v_4, \\ [v_3, v_4] \rightarrow v_5. \end{align} $$maxlen=2的情况下, 会切分为
修改 maxlen 的实验结果
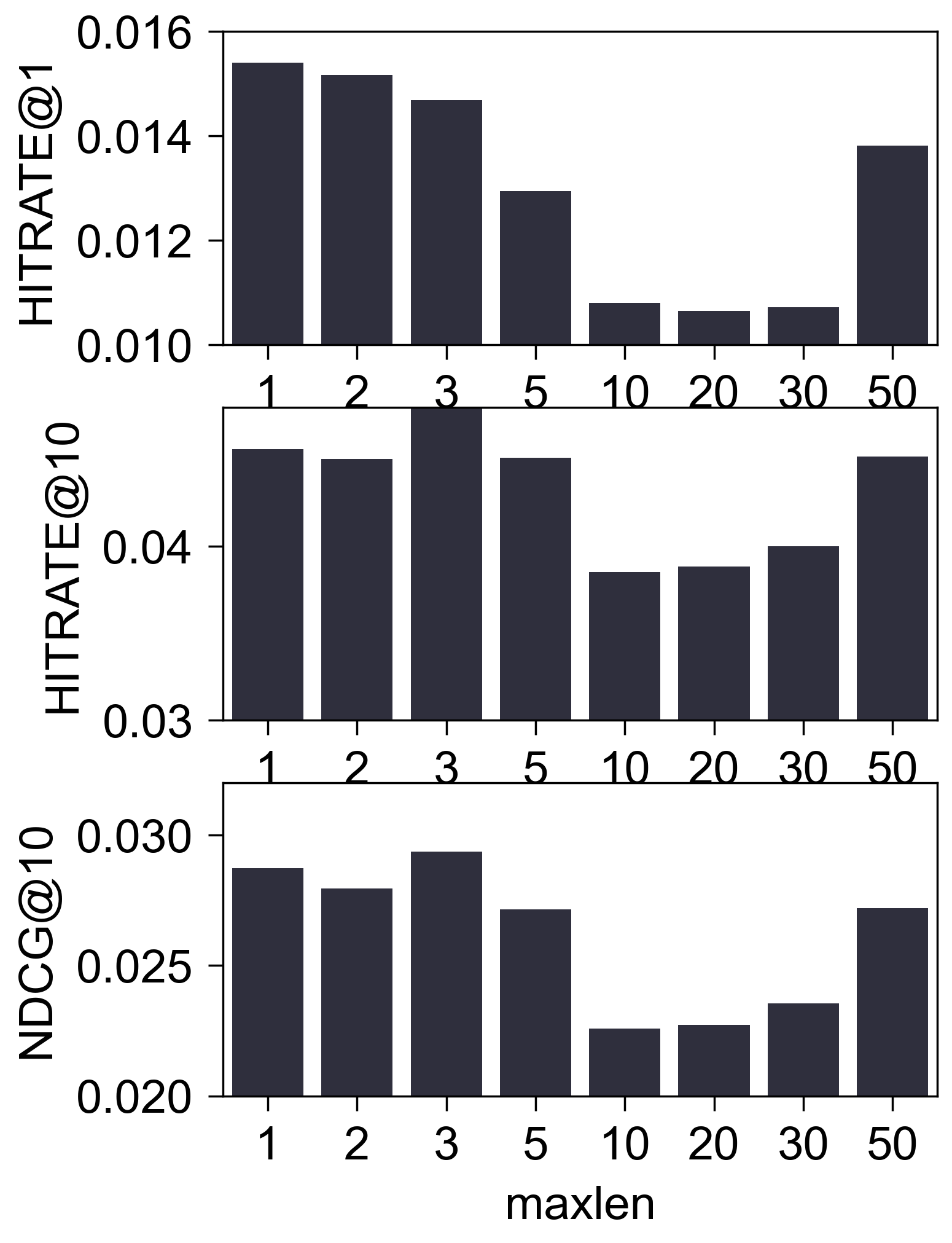
Amazon2014Beauty_550_LOU
- (唯一用户数量) 当
maxlen比较小的时候, 显然会有很多 user 的交互序列是一样的, 下图是不同maxlen下唯一用户的占比:
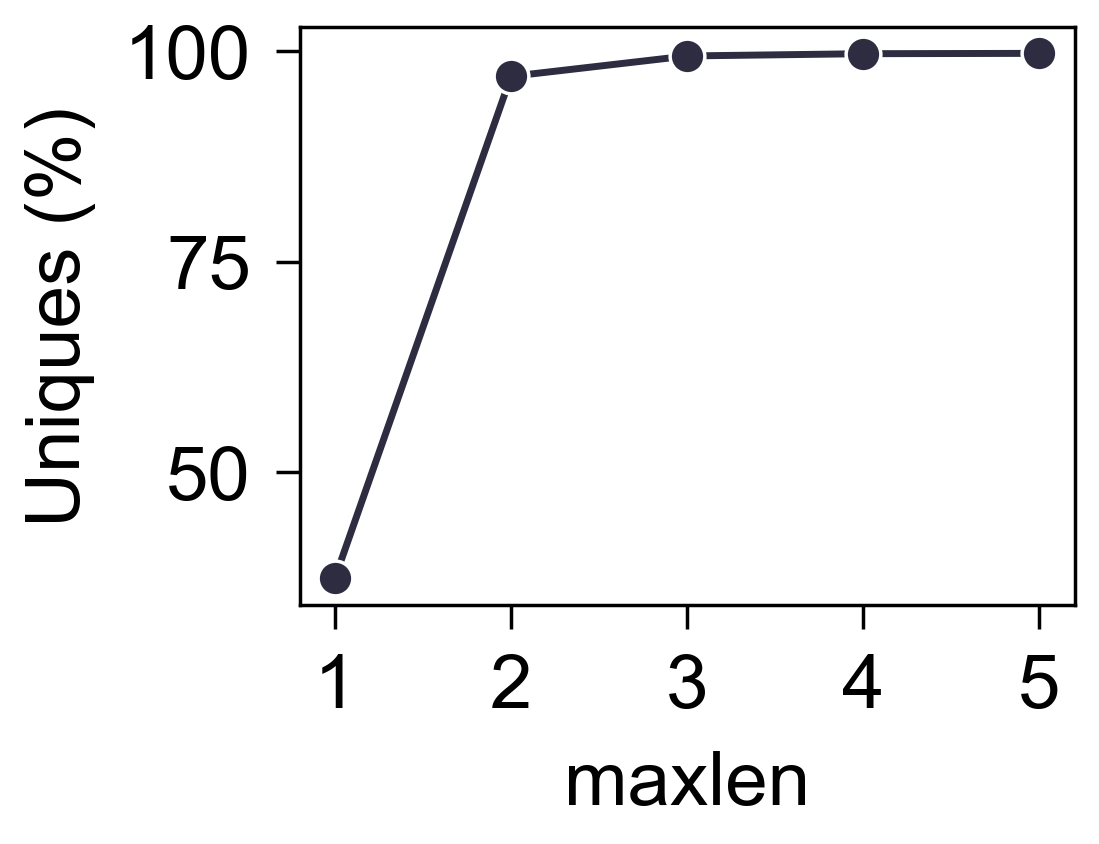
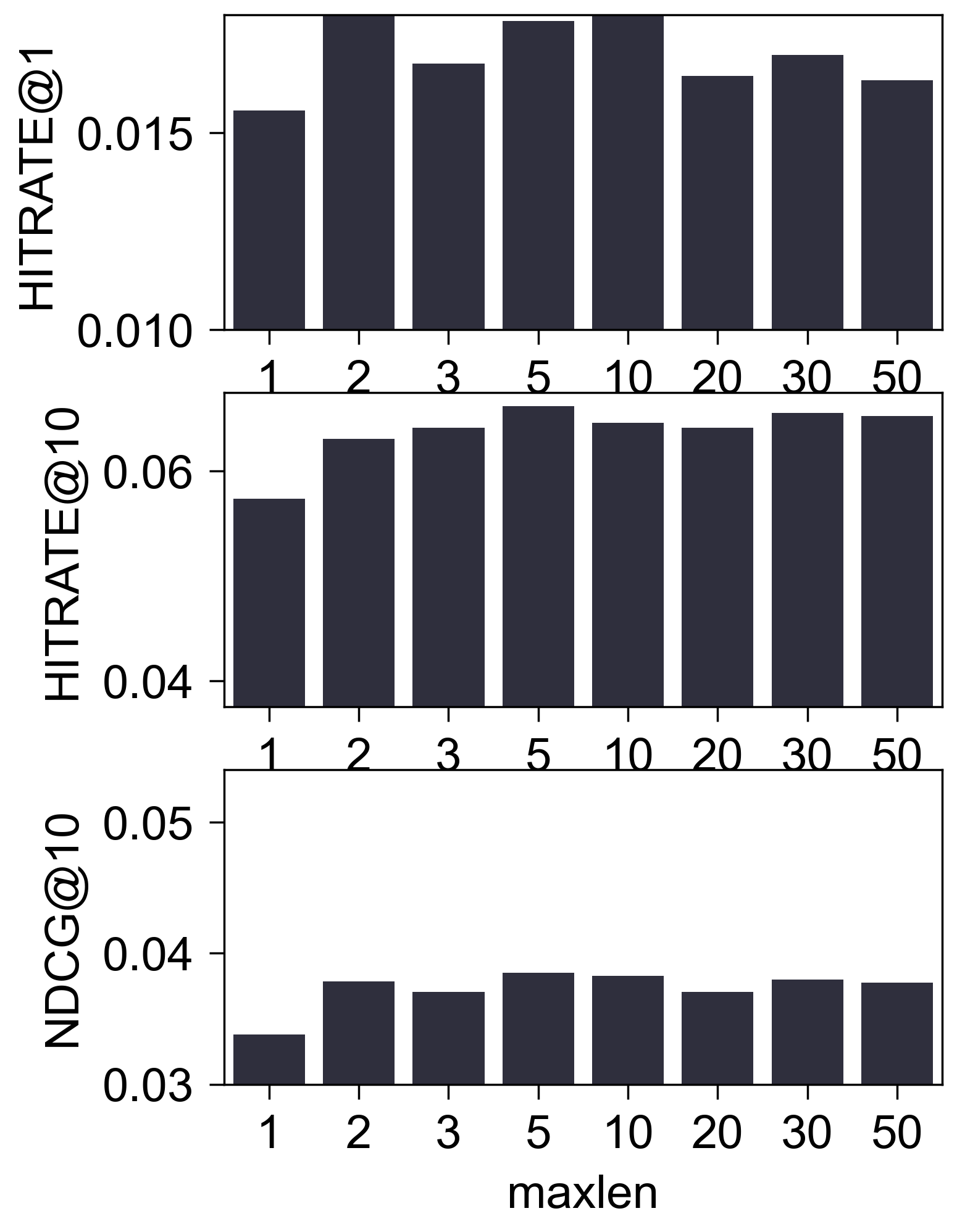
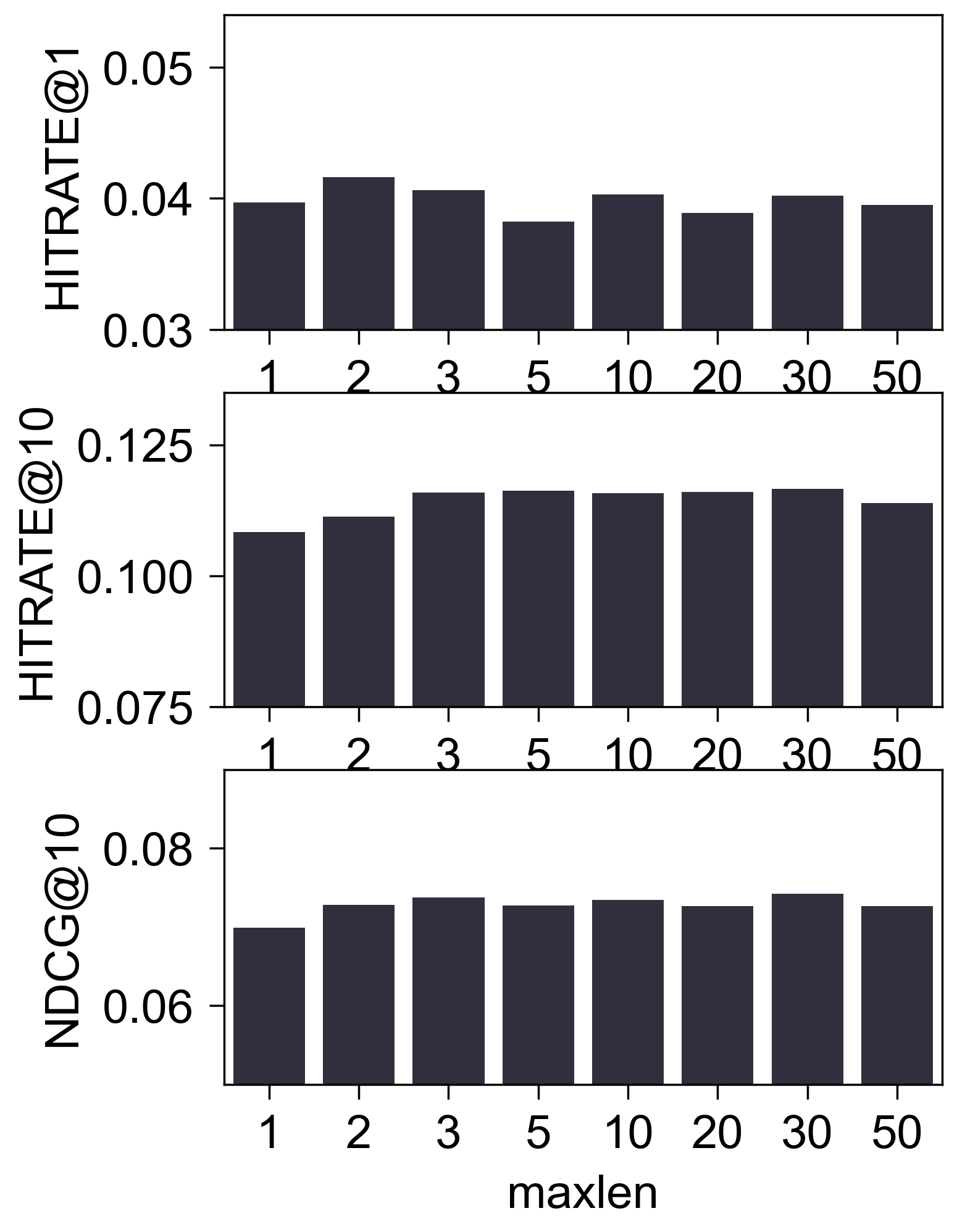
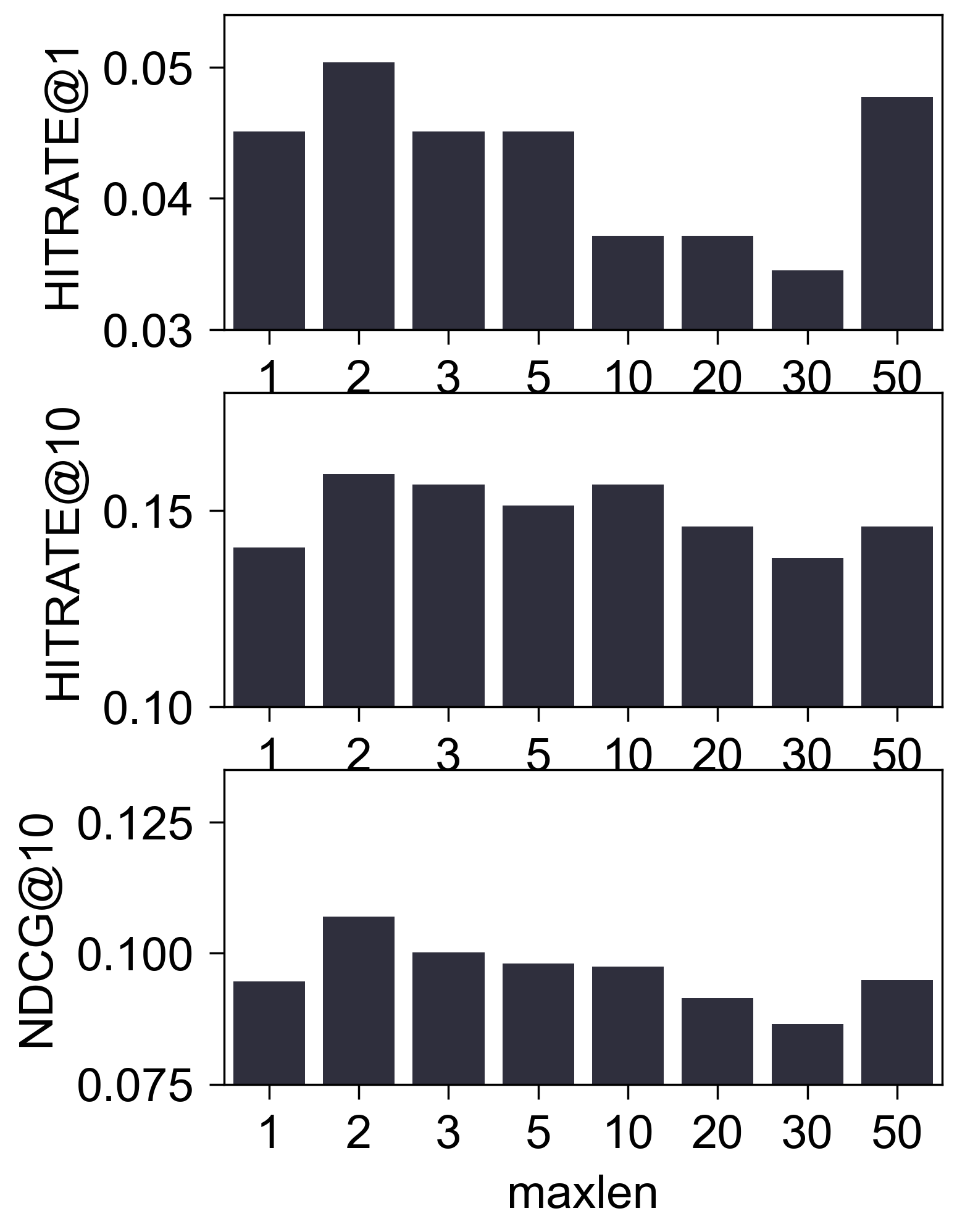
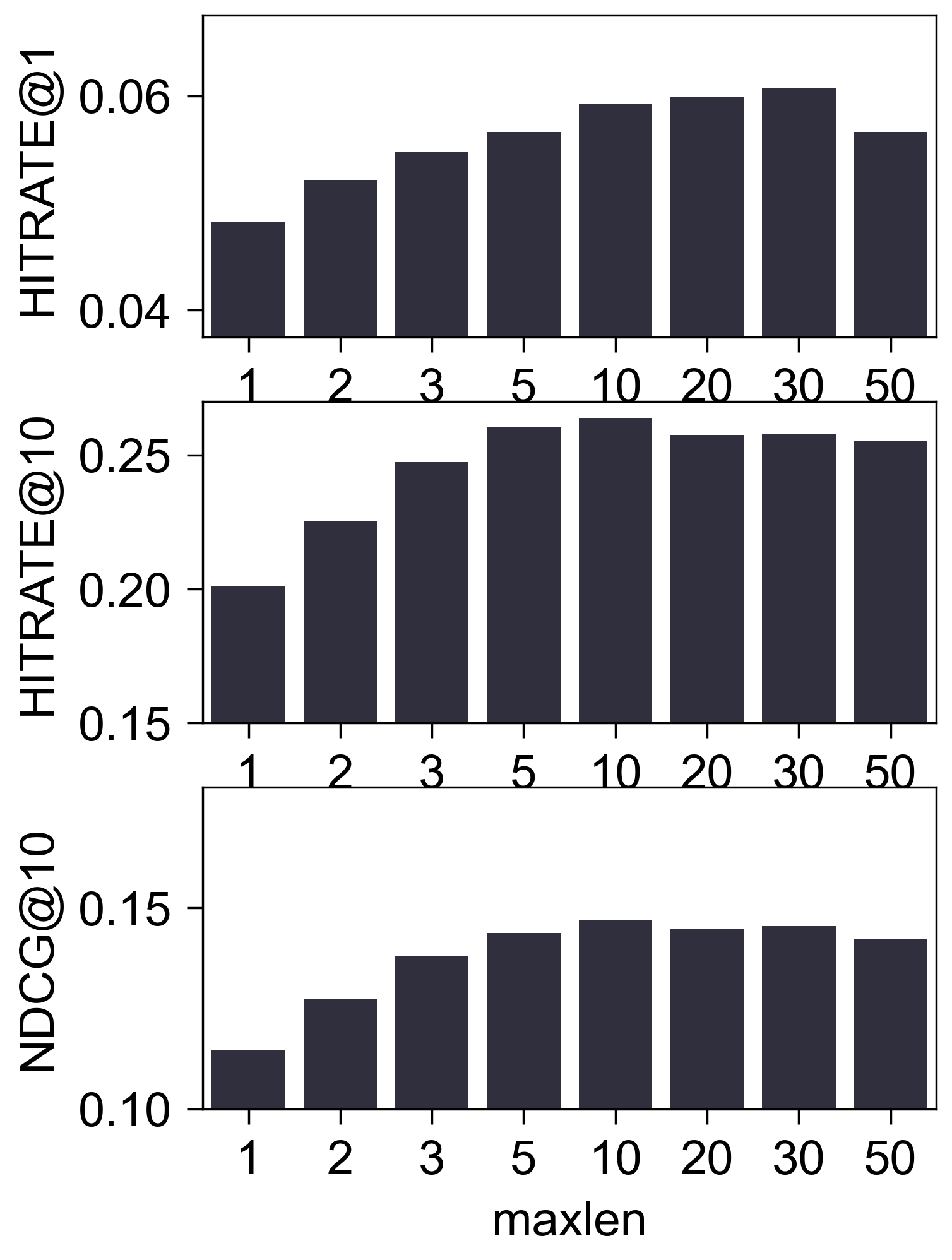
- (性能比较) 下图是调整
maxlen后的性能比较:
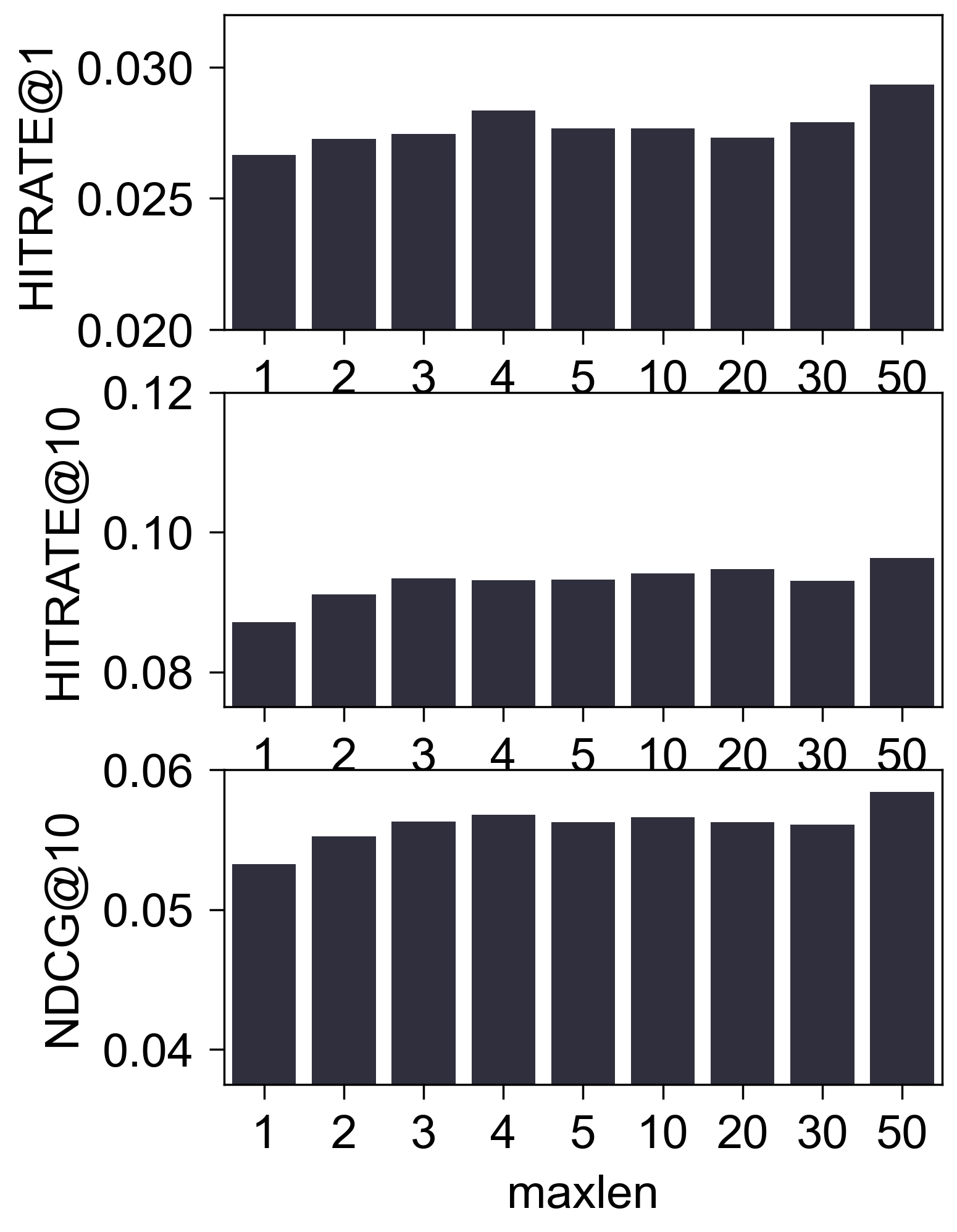
(初步结论) 至少在 Amazon2014Beauty_550_LOU 这个经典的数据集上, 我们很难认为 SASRec 抓住了所谓的序列信息. 这一点其实在 SASRec 原本中可以窥见一二, 其中所展示的 Attention Map, 几乎都 sink 在倒一 Items.
(进一步分析)
$$ \begin{align} \text{(Attention)} \quad & \bm{h}_l = \text{LN}\left( \text{Dropout}\left( W_1\bm{e}_l \right) + \bm{e}_l \right), \\ \text{(FFN)} \quad & \bm{e}_{l + 1} = \text{LN}\left( \text{Dropout}\left( W_3 \sigma(W_2\bm{h}_l) \right) + \bm{h}_l \right). \\ \end{align} $$maxlen=1是一种非常恐怖的极限状态, 此时 SASRec 的每个 block 相当于:其中 $\sigma(\cdot)$ 代表某个激活函数. 这 Attention 的存在显得那么多余.
SASRec + Zero Block
根据上述的猜想, 我首先想着把 Attention 去掉看看, 毕竟这基本上就是就是一个普通的线性层, 发现效果也没掉特别的. 于是一个更加大胆的想法出现了, 会不会压根就不需要复杂的 Attention/FFN?
于是乎, 一个最简单的 ‘SASRec’ 模型就得到了:
$$ \begin{align} s_{ui} = \bm{e}_{v_t}^T \bm{e}_{v_i}, \quad v_i \in \mathcal{V}. \end{align} $$
| Blocks | HR@1 | HR@10 | NDCG@10 |
|---|---|---|---|
| Blocks=4 | 0.0279 | 0.0807 | 0.0508 |
| Blocks=3 | 0.0269 | 0.0846 | 0.0522 |
| Blocks=2 | 0.0267 | 0.0871 | 0.0532 |
| Blocks=1 | 0.0275 | 0.0855 | 0.0530 |
| (8) | 0.0272 | 0.0850 | 0.0526 |
STAMP
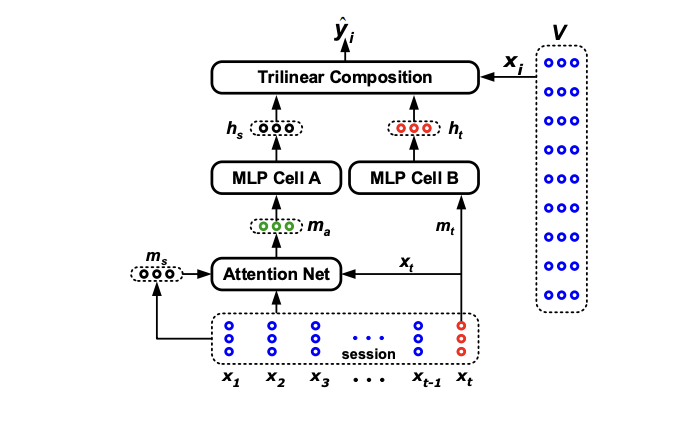
STAMP${}^{[1]}$ 是一个非常强调 last Item 的方法: 不仅单独拿出 last Item 用于预测, 在综合长期兴趣的过程中, 也融合 last Item.
然而, 即使在如此条件下, STAMP 的其他操作依旧在 Beauty 上依旧是冗余的:
| Blocks | HR@1 | HR@10 | NDCG@10 |
|---|---|---|---|
| STAMP | 0.0168 | 0.0564 | 0.0343 |
| only $\bm{h}_t$ | 0.0270 | 0.0710 | 0.0466 |
| only $\bm{m}_t$ | 0.0246 | 0.0814 | 0.0496 |
- 接下来的问题是, 这个问题是 Beauty 上的个例, 还是 Amazon 数据集上的个例, 还是大部分 Next-Item Recommendation 的共性?
Amazon2014Beauty_554_LOU
Amazon2014Beauty_1000_LOU
Amazon2014Tools_554_LOU
Amazon2014Toys_554_LOU
RetailrocketTransaction_500_LOU
Yelp2018_10100_LOU
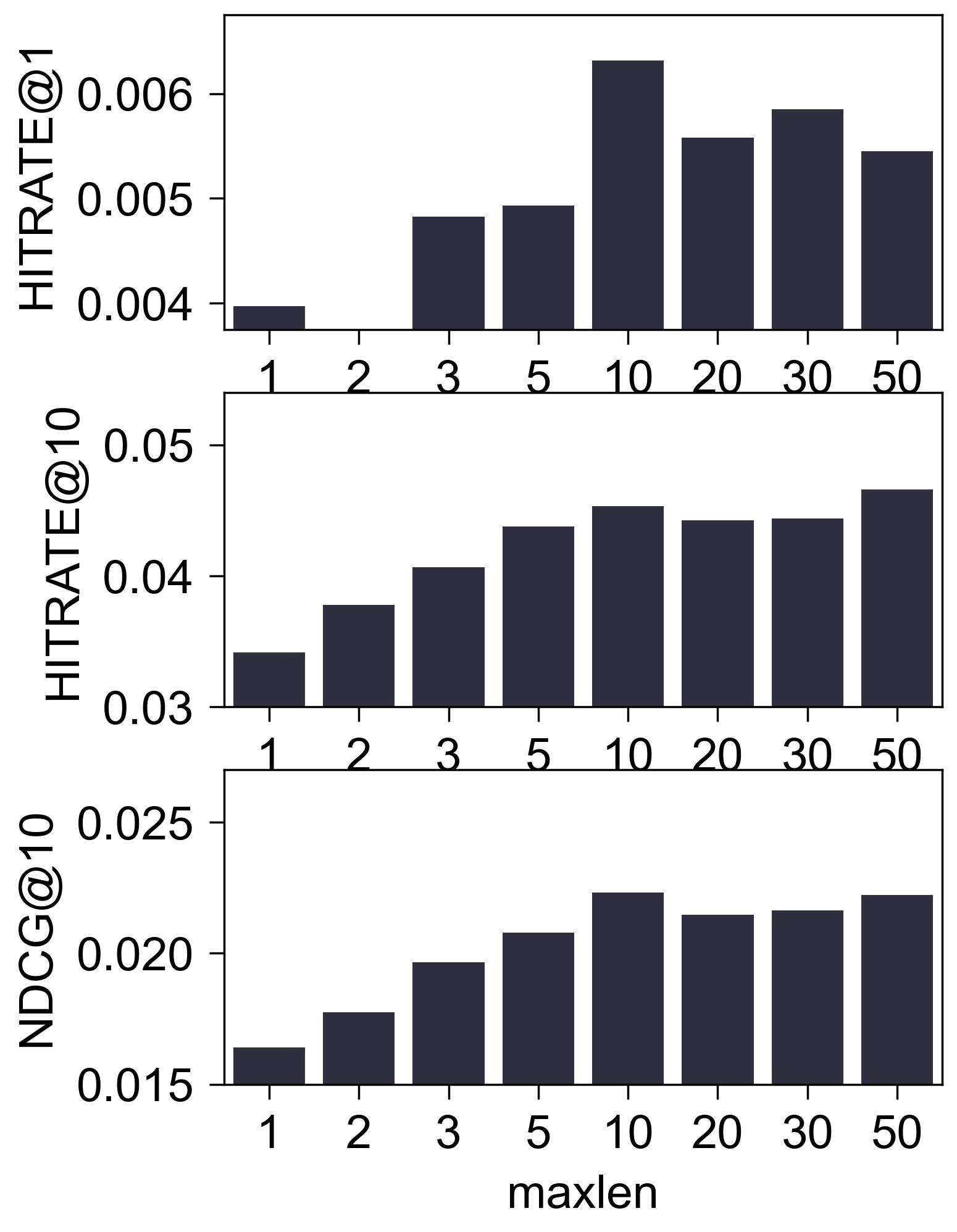
Steam_550_LOU
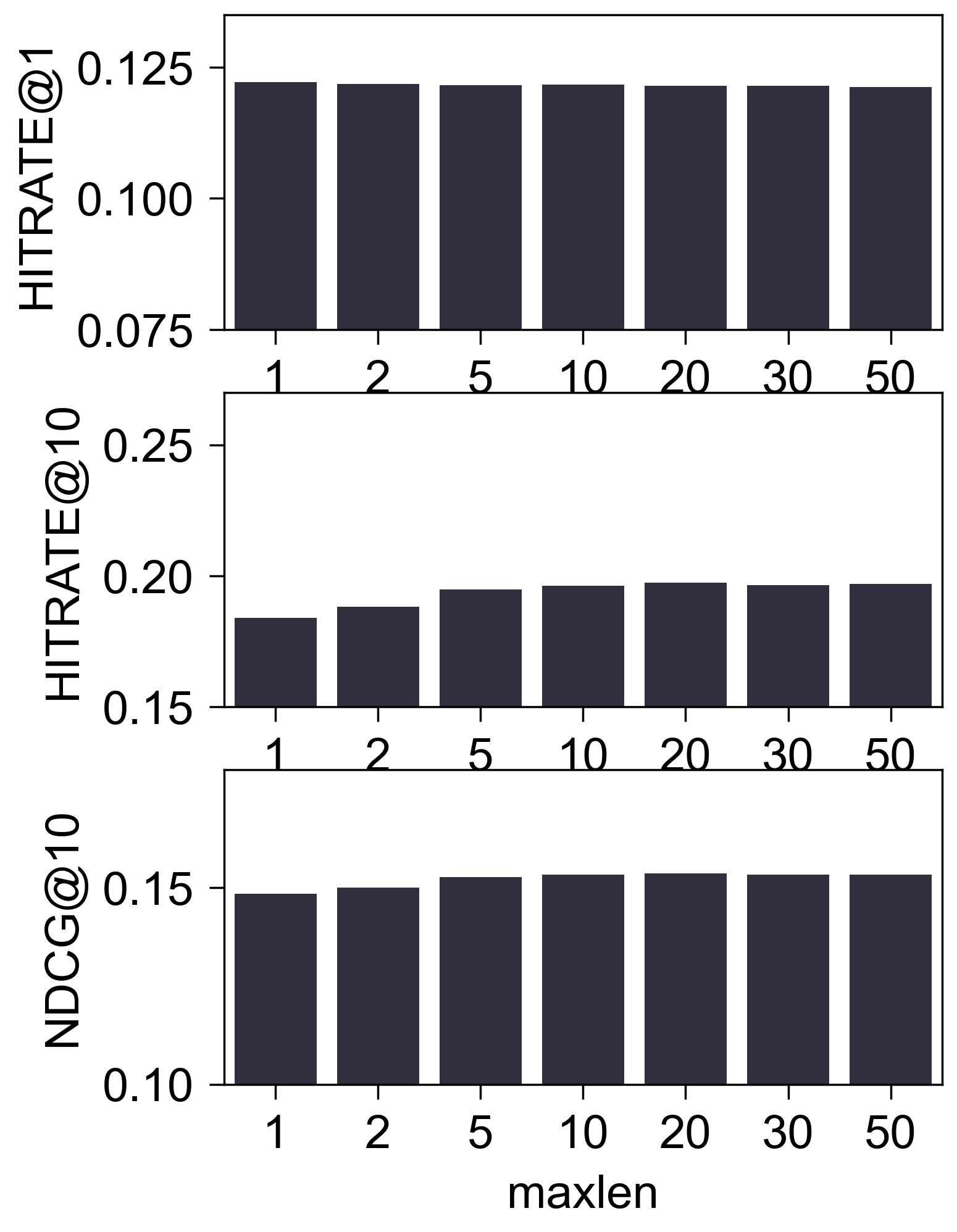
Tmall2016Buy_550_LOU
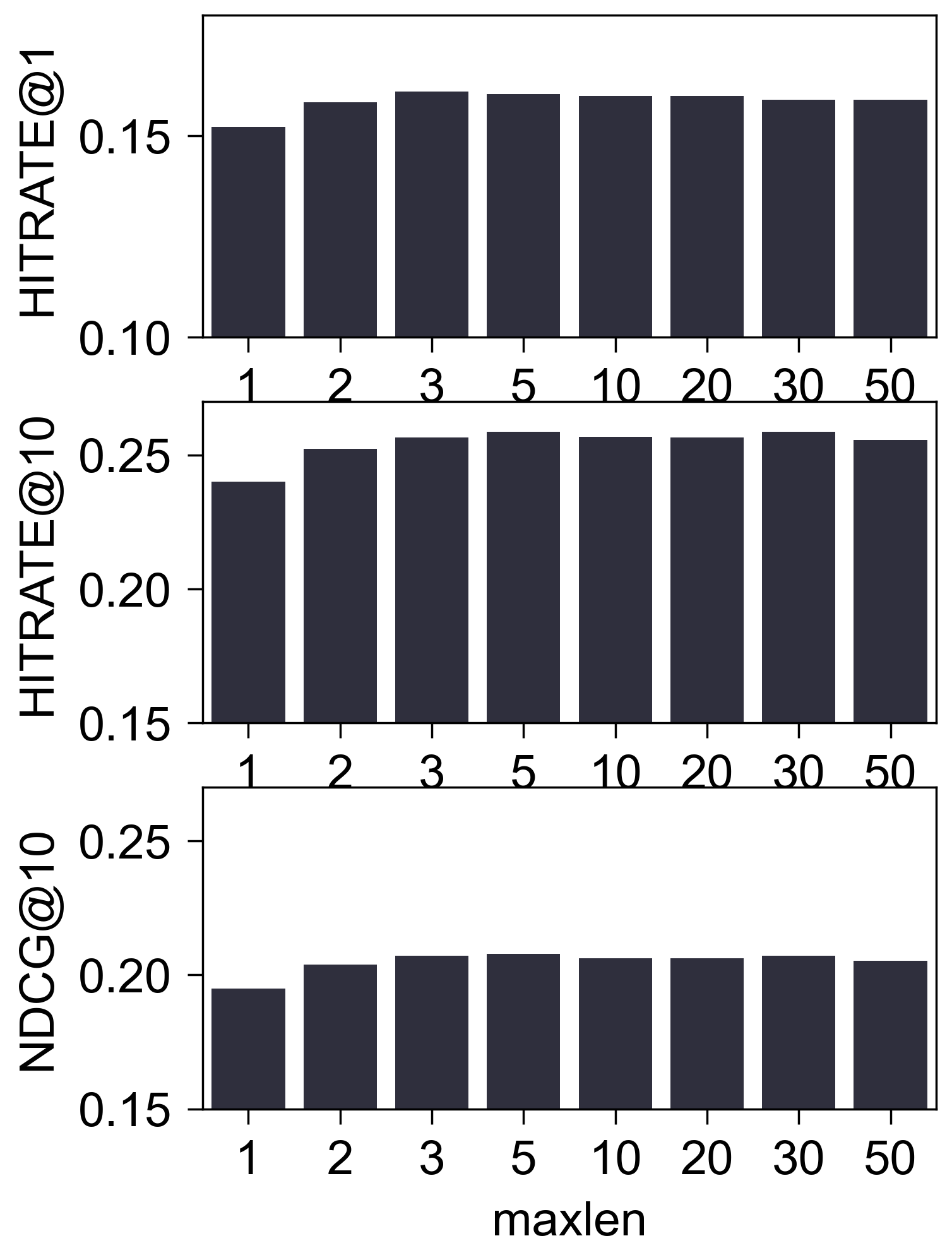
MovieLens1M_550_LOU
Shuffle($v_1, v_2, \ldots, v_{t-1}$)
从上面的实验看出, 有些时候, 仅仅保留 Last Item 还是会造成一些精度的下降的. 那么这部分精度的下降是来源于序列信息的丢失吗?
为此, 进一步的实验方案是验证
$$ \begin{align} P(v| v_1, v_2, \ldots, v_t) \overset{?}{\approx} P(v| \text{Shuffle}(v_1, v_2, \ldots), v_t). \end{align} $$理论上来说, 如果说序列推荐是强序列的, 那么 Shuffle 后应该会观测到明显的效果的下降. 注意, 我们具体的实验方案是用原序列正常训练 SASRec, 仅仅在测试的时候加入一组 Shuffle 非 Last Item 部分的比较.
| Orignal | - | - | - | - | Shuffled | - | - | - | - | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | HR@1 | HR@5 | HR@10 | NDCG@5 | NDCG@10 | HR@1 | HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
| Amazon2014Beauty_550_LOU | 0.0296 | 0.0699 | 0.0990 | 0.0502 | 0.0595 | 0.0298 | 0.0700 | 0.0992 | 0.0503 | 0.0596 | |
| Amazon2014Beauty_554_LOU | 0.0367 | 0.0935 | 0.1282 | 0.0656 | 0.0768 | 0.0369 | 0.0932 | 0.1280 | 0.0655 | 0.0767 | |
| MovieLens1M_550_LOU | 0.0540 | 0.1609 | 0.2411 | 0.1088 | 0.1345 | 0.0437 | 0.1444 | 0.2099 | 0.0957 | 0.1169 | |
| RetailrocketTransaction_500_LOU | 0.0424 | 0.1114 | 0.1353 | 0.0797 | 0.0869 | 0.0398 | 0.1114 | 0.1379 | 0.0787 | 0.0867 | |
| Steam_550_LOU | 0.1216 | 0.1680 | 0.2049 | 0.1452 | 0.1570 | 0.1212 | 0.1675 | 0.2041 | 0.1447 | 0.1564 | |
| Tmall2016Buy_550_LOU | |||||||||||
| Amazon2014Tools_550_LOU | 0.0166 | 0.0426 | 0.0588 | 0.0300 | 0.0352 | 0.0167 | 0.0431 | 0.0588 | 0.0302 | 0.0353 | |
| Amazon2014Tools_554_LOU | 0.0174 | 0.0445 | 0.0664 | 0.0313 | 0.0384 | 0.0173 | 0.0450 | 0.0666 | 0.0315 | 0.0385 | |
| Amazon2014Toys_550_LOU | 0.0334 | 0.0735 | 0.1010 | 0.0540 | 0.0629 | 0.0334 | 0.0737 | 0.1010 | 0.0541 | 0.0628 | |
| Amazon2014Toys_554_LOU | 0.0392 | 0.0857 | 0.1164 | 0.0631 | 0.0729 | 0.0386 | 0.0858 | 0.1165 | 0.0630 | 0.0728 | |
| Yelp2018_10100_LOU | 0.0072 | 0.0294 | 0.0510 | 0.0182 | 0.0252 | 0.0071 | 0.0293 | 0.0516 | 0.0181 | 0.0253 |
- (现象)
- 绝大部分数据集 (实际上是除了 MovieLens1M 之外) Shuffle 前后效果几乎都没有变化, 要知道, 我们是没有在 Shuffle 后的数据集上训练的, 模型有如此的泛化性只能说明大部分序列推荐数据集不存在强序列性.
- 在之前的实验中, Yelp2018_10100_LOU 明显是对
maxlen敏感的, 然而这个差距可能仅仅来自于maxlen的降低导致了非序列信息的缺失. 这部分信息可能只是反映了用户的一些 (非动态) 的兴趣.
MovieLens 的序列性
- 令人比较困惑的点在于, MovieLens1M 这个从数据收集上就没有序列性的数据集为什么反而体现出了序列性, 于是我打印了一下序列中电影类别:

- 虽然这只是其中一条, 但是显然 MovieLens 是有所谓的序列性的. 但是, 我个人猜想, 可能是因为 MovieLens 的推荐算法, 本身就是倾向于一类一类地推, 因此才有了这所谓的序列性.
结论
对于序列推荐而言, Last Item 起着决定性作用.
如果仅仅保留 Last Item, Attention/FFN 的存在便没有特别的意义. 换言之, Transformer 对于序列推荐而言, 最为重要的是它能够通过 Attention 定位 Last Item.
仅依赖 Last Item 会丢失掉一部分起作用的信息, 但是 Shuffle 部分的实验证明了这部分信息与序列性并没有强烈的关系.
代码
- 均采用如下的配置:
root: ../../data
tasktag: NEXTITEM
maxlen: 50
num_heads: 1
num_blocks: 2
embedding_dim: 64
dropout_rate: 0.6
epochs: 100
batch_size: 512
optimizer: adam
lr: 5.e-4
weight_decay: 1.e-8
loss: CE
monitors: [LOSS, HitRate@1, HitRate@5, HitRate@10, NDCG@5, NDCG@10]
which4best: NDCG@10
完整序列 $\overset{\text{maxlen} \downarrow}{\longrightarrow}$ Last Item
from typing import Dict, Tuple, Union
import torch
import torch.nn as nn
import freerec
freerec.declare(version='1.0.1')
cfg = freerec.parser.Parser()
cfg.add_argument("--minlen", type=int, default=2)
cfg.add_argument("--maxlen", type=int, default=50)
cfg.add_argument("--num-heads", type=int, default=1)
cfg.add_argument("--num-blocks", type=int, default=2)
cfg.add_argument("--embedding-dim", type=int, default=64)
cfg.add_argument("--dropout-rate", type=float, default=0.2)
cfg.set_defaults(
description="SASRec",
root="../../data",
dataset='Amazon2014Beauty_550_LOU',
epochs=200,
batch_size=256,
optimizer='adam',
lr=1e-3,
weight_decay=0.,
seed=1,
)
cfg.compile()
class PointWiseFeedForward(nn.Module):
def __init__(self, hidden_size: int, dropout_rate: int):
super(PointWiseFeedForward, self).__init__()
self.conv1 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.relu = nn.ReLU()
self.conv2 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout2 = nn.Dropout(p=dropout_rate)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
# inputs: (B, S, D)
outputs = self.dropout2(self.conv2(self.relu(
self.dropout1(self.conv1(inputs.transpose(-1, -2)))
))) # -> (B, D, S)
outputs = outputs.transpose(-1, -2) # -> (B, S, D)
outputs += inputs
return outputs
class SASRec(freerec.models.SeqRecArch):
def __init__(
self, dataset: freerec.data.datasets.RecDataSet,
maxlen: int = 50, embedding_dim: int = 64,
dropout_rate: float = 0.2, num_blocks: int = 1, num_heads: int = 2,
) -> None:
super().__init__(dataset)
self.embedding_dim = embedding_dim
self.num_blocks = num_blocks
self.Item.add_module(
'embeddings', nn.Embedding(
num_embeddings=self.Item.count + self.NUM_PADS,
embedding_dim=embedding_dim,
padding_idx=self.PADDING_VALUE
)
)
self.Position = nn.Embedding(maxlen, embedding_dim)
self.embdDropout = nn.Dropout(p=dropout_rate)
self.register_buffer(
"positions",
torch.tensor(range(0, maxlen), dtype=torch.long).unsqueeze(0)
)
self.attnLNs = nn.ModuleList() # to be Q for self-attention
self.attnLayers = nn.ModuleList()
self.fwdLNs = nn.ModuleList()
self.fwdLayers = nn.ModuleList()
self.lastLN = nn.LayerNorm(embedding_dim, eps=1e-8)
for _ in range(num_blocks):
self.attnLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.attnLayers.append(
nn.MultiheadAttention(
embed_dim=embedding_dim,
num_heads=num_heads,
dropout=dropout_rate,
batch_first=True # !!!
)
)
self.fwdLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.fwdLayers.append(PointWiseFeedForward(
embedding_dim, dropout_rate
))
# False True True ...
# False False True ...
# False False False ...
# ....
# True indices that the corresponding position is not allowed to attend !
self.register_buffer(
'attnMask',
torch.ones((maxlen, maxlen), dtype=torch.bool).triu(diagonal=1)
)
self.criterion = freerec.criterions.CrossEntropy4Logits(reduction='mean')
self.reset_parameters()
def reset_parameters(self):
"""Initializes the module parameters."""
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0.)
elif isinstance(m, nn.Embedding):
nn.init.xavier_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d)):
nn.init.constant_(m.weight, 1.)
nn.init.constant_(m.bias, 0.)
def sure_trainpipe(self, maxlen: int, batch_size: int):
return self.dataset.train().shuffled_roll_seqs_source(
minlen=cfg.minlen, maxlen=50, # XXX: !!!
keep_at_least_itself=True
).lprune_(
maxlen=maxlen + 1, modified_fields=(self.ISeq,)
).seq_train_yielding_pos_(
start_idx_for_target=-1, end_idx_for_input=-1
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq,)
).lpad_(
maxlen, modified_fields=(self.ISeq,),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
def mark_position(self, seqs: torch.Tensor):
positions = self.Position(self.positions) # (1, maxlen, D)
return seqs + positions
def after_one_block(self, seqs: torch.Tensor, padding_mask: torch.Tensor, l: int):
# inputs: (B, S, D)
Q = self.attnLNs[l](seqs)
seqs = self.attnLayers[l](
Q, seqs, seqs,
attn_mask=self.attnMask,
need_weights=False
)[0] + seqs
seqs = self.fwdLNs[l](seqs)
seqs = self.fwdLayers[l](seqs)
return seqs.masked_fill(padding_mask, 0.)
def encode(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
seqs = data[self.ISeq]
padding_mask = (seqs == self.PADDING_VALUE).unsqueeze(-1)
seqs = self.Item.embeddings(seqs) # (B, S) -> (B, S, D)
seqs *= self.embedding_dim ** 0.5
seqs = self.embdDropout(self.mark_position(seqs))
seqs = seqs.masked_fill(padding_mask, 0.)
for l in range(self.num_blocks):
seqs = self.after_one_block(seqs, padding_mask, l)
userEmbds = self.lastLN(seqs) # (B, S, D)
return userEmbds[:, -1, :], self.Item.embeddings.weight[self.NUM_PADS:]
def fit(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
userEmbds, itemEmbds = self.encode(data)
logits = torch.einsum("MD,ND->MN", userEmbds, itemEmbds) # (M, N)
labels = data[self.IPos].flatten() # (M,)
rec_loss = self.criterion(logits, labels)
return rec_loss
def recommend_from_full(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
return torch.einsum("BD,ND->BN", userEmbds, itemEmbds)
def recommend_from_pool(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
itemEmbds = itemEmbds[data[self.IUnseen]] # (B, K, D)
return torch.einsum("BD,BKD->BK", userEmbds, itemEmbds)
class CoachForSASRec(freerec.launcher.Coach):
def train_per_epoch(self, epoch: int):
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.monitor(
loss.item(),
n=len(data[self.User]), reduction="mean",
mode='train', pool=['LOSS']
)
def main():
dataset: freerec.data.datasets.RecDataSet
try:
dataset = getattr(freerec.data.datasets, cfg.dataset)(root=cfg.root)
except AttributeError:
dataset = freerec.data.datasets.RecDataSet(cfg.root, cfg.dataset, tasktag=cfg.tasktag)
model = SASRec(
dataset, maxlen=cfg.maxlen,
embedding_dim=cfg.embedding_dim, dropout_rate=cfg.dropout_rate,
num_blocks=cfg.num_blocks, num_heads=cfg.num_heads,
)
# datapipe
trainpipe = model.sure_trainpipe(cfg.maxlen, cfg.batch_size)
validpipe = model.sure_validpipe(cfg.maxlen, ranking=cfg.ranking)
testpipe = model.sure_testpipe(cfg.maxlen, ranking=cfg.ranking)
coach = CoachForSASRec(
dataset=dataset,
trainpipe=trainpipe,
validpipe=validpipe,
testpipe=testpipe,
model=model,
cfg=cfg
)
coach.fit()
if __name__ == "__main__":
main()
Shuffle($v_1, v_2, \ldots, v_{t-1}$)
# main.py
from typing import Dict, Tuple, Union
import torch
import torch.nn as nn
import freerec
from sampler import *
freerec.declare(version='1.0.1')
cfg = freerec.parser.Parser()
cfg.add_argument("--maxlen", type=int, default=50)
cfg.add_argument("--num-heads", type=int, default=1)
cfg.add_argument("--num-blocks", type=int, default=2)
cfg.add_argument("--embedding-dim", type=int, default=64)
cfg.add_argument("--dropout-rate", type=float, default=0.2)
cfg.add_argument("--loss", type=str, choices=('BPR', 'BCE', 'CE'), default='BCE')
cfg.set_defaults(
description="SASRec",
root="../../data",
dataset='Amazon2014Beauty_550_LOU',
epochs=200,
batch_size=256,
optimizer='adam',
lr=1e-3,
weight_decay=0.,
seed=1,
)
cfg.compile()
class PointWiseFeedForward(nn.Module):
def __init__(self, hidden_size: int, dropout_rate: int):
super(PointWiseFeedForward, self).__init__()
self.conv1 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.relu = nn.ReLU()
self.conv2 = nn.Conv1d(hidden_size, hidden_size, kernel_size=1)
self.dropout2 = nn.Dropout(p=dropout_rate)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
# inputs: (B, S, D)
outputs = self.dropout2(self.conv2(self.relu(
self.dropout1(self.conv1(inputs.transpose(-1, -2)))
))) # -> (B, D, S)
outputs = outputs.transpose(-1, -2) # -> (B, S, D)
outputs += inputs
return outputs
class SASRec(freerec.models.SeqRecArch):
def __init__(
self, dataset: freerec.data.datasets.RecDataSet,
maxlen: int = 50, embedding_dim: int = 64,
dropout_rate: float = 0.2, num_blocks: int = 1, num_heads: int = 2,
) -> None:
super().__init__(dataset)
self.embedding_dim = embedding_dim
self.num_blocks = num_blocks
self.Item.add_module(
'embeddings', nn.Embedding(
num_embeddings=self.Item.count + self.NUM_PADS,
embedding_dim=embedding_dim,
padding_idx=self.PADDING_VALUE
)
)
self.Position = nn.Embedding(maxlen, embedding_dim)
self.embdDropout = nn.Dropout(p=dropout_rate)
self.register_buffer(
"positions",
torch.tensor(range(0, maxlen), dtype=torch.long).unsqueeze(0)
)
self.attnLNs = nn.ModuleList() # to be Q for self-attention
self.attnLayers = nn.ModuleList()
self.fwdLNs = nn.ModuleList()
self.fwdLayers = nn.ModuleList()
self.lastLN = nn.LayerNorm(embedding_dim, eps=1e-8)
for _ in range(num_blocks):
self.attnLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.attnLayers.append(
nn.MultiheadAttention(
embed_dim=embedding_dim,
num_heads=num_heads,
dropout=dropout_rate,
batch_first=True # !!!
)
)
self.fwdLNs.append(nn.LayerNorm(
embedding_dim, eps=1e-8
))
self.fwdLayers.append(PointWiseFeedForward(
embedding_dim, dropout_rate
))
# False True True ...
# False False True ...
# False False False ...
# ....
# True indices that the corresponding position is not allowed to attend !
self.register_buffer(
'attnMask',
torch.ones((maxlen, maxlen), dtype=torch.bool).triu(diagonal=1)
)
if cfg.loss == 'BCE':
self.criterion = freerec.criterions.BCELoss4Logits(reduction='mean')
elif cfg.loss == 'BPR':
self.criterion = freerec.criterions.BPRLoss(reduction='mean')
elif cfg.loss == 'CE':
self.criterion = freerec.criterions.CrossEntropy4Logits(reduction='mean')
self.reset_parameters()
def reset_parameters(self):
"""Initializes the module parameters."""
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0.)
elif isinstance(m, nn.Embedding):
nn.init.xavier_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d)):
nn.init.constant_(m.weight, 1.)
nn.init.constant_(m.bias, 0.)
def sure_trainpipe(self, maxlen: int, batch_size: int):
return self.dataset.train().shuffled_seqs_source(
maxlen=maxlen
).seq_train_yielding_pos_(
start_idx_for_target=1, end_idx_for_input=-1
).seq_train_sampling_neg_(
num_negatives=1
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq,)
).lpad_(
maxlen, modified_fields=(self.ISeq, self.IPos, self.INeg),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
def sure_validpipe(
self, maxlen: int, ranking: str = 'full', batch_size: int = 512,
):
return self.dataset.valid().ordered_user_ids_source(
).valid_shuffled_sampling_(
ranking
).lprune_(
maxlen, modified_fields=(self.ISeq, self.Item)
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.Item)
).lpad_(
maxlen, modified_fields=(self.ISeq, self.Item),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
def sure_testpipe(
self, maxlen: int, ranking: str = 'full', batch_size: int = 512,
):
return self.dataset.test().ordered_user_ids_source(
).test_shuffled_sampling_(ranking).lprune_(
maxlen, modified_fields=(self.ISeq, self.Item)
).add_(
offset=self.NUM_PADS, modified_fields=(self.ISeq, self.Item)
).lpad_(
maxlen, modified_fields=(self.ISeq, self.Item),
padding_value=self.PADDING_VALUE
).batch_(batch_size).tensor_()
def mark_position(self, seqs: torch.Tensor):
positions = self.Position(self.positions) # (1, maxlen, D)
return seqs + positions
def after_one_block(self, seqs: torch.Tensor, padding_mask: torch.Tensor, l: int):
# inputs: (B, S, D)
Q = self.attnLNs[l](seqs)
seqs = self.attnLayers[l](
Q, seqs, seqs,
attn_mask=self.attnMask,
need_weights=False
)[0] + seqs
seqs = self.fwdLNs[l](seqs)
seqs = self.fwdLayers[l](seqs)
return seqs.masked_fill(padding_mask, 0.)
def encode(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
seqs = data[self.ISeq]
padding_mask = (seqs == self.PADDING_VALUE).unsqueeze(-1)
seqs = self.Item.embeddings(seqs) # (B, S) -> (B, S, D)
seqs *= self.embedding_dim ** 0.5
seqs = self.embdDropout(self.mark_position(seqs))
seqs = seqs.masked_fill(padding_mask, 0.)
for l in range(self.num_blocks):
seqs = self.after_one_block(seqs, padding_mask, l)
userEmbds = self.lastLN(seqs) # (B, S, D)
return userEmbds, self.Item.embeddings.weight[self.NUM_PADS:]
def fit(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
userEmbds, itemEmbds = self.encode(data)
indices = data[self.ISeq] != self.PADDING_VALUE
userEmbds = userEmbds[indices] # (M, D)
if cfg.loss in ('BCE', 'BPR'):
posEmbds = itemEmbds[data[self.IPos][indices]] # (M, D)
negEmbds = itemEmbds[data[self.INeg][indices]] # (M, D)
posLogits = torch.einsum("MD,MD->M", userEmbds, posEmbds) # (M,)
negLogits = torch.einsum("MD,MD->M", userEmbds, negEmbds) # (M,)
if cfg.loss == 'BCE':
posLabels = torch.ones_like(posLogits)
negLabels = torch.zeros_like(negLogits)
rec_loss = self.criterion(posLogits, posLabels) + \
self.criterion(negLogits, negLabels)
elif cfg.loss == 'BPR':
rec_loss = self.criterion(posLogits, negLogits)
elif cfg.loss == 'CE':
logits = torch.einsum("MD,ND->MN", userEmbds, itemEmbds) # (M, N)
labels = data[self.IPos][indices] # (M,)
rec_loss = self.criterion(logits, labels)
return rec_loss
def recommend_from_full(
self, data: Dict[freerec.data.fields.Field, torch.Tensor]
) -> torch.Tensor:
userEmbds, itemEmbds = self.encode(data)
userEmbds = userEmbds[:, -1, :] # (B, D)
scores = torch.einsum("BD,ND->BN", userEmbds, itemEmbds)
data[self.ISeq] = data[self.Item]
userEmbds, itemEmbds = self.encode(data)
userEmbds = userEmbds[:, -1, :] # (B, D)
shuffled_scores = torch.einsum("BD,ND->BN", userEmbds, itemEmbds)
return scores, shuffled_scores
class CoachForSASRec(freerec.launcher.Coach):
def train_per_epoch(self, epoch: int):
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.monitor(
loss.item(),
n=len(data[self.User]), reduction="mean",
mode='train', pool=['LOSS']
)
def set_other(self):
for k in ('1', '5', '10'):
self.register_metric(
f"HITRATE-S@{k}", freerec.metrics.hit_rate, best_caster=max
)
for k in ('5', '10'):
self.register_metric(
f"NDCG-S@{k}", freerec.metrics.normalized_dcg, best_caster=max
)
def evaluate(self, epoch: int, step: int = -1, mode: str = 'valid'):
self.get_res_sys_arch().reset_ranking_buffers()
for data in self.dataloader:
bsz = data[self.Size]
data = self.dict_to_device(data)
scores, shuffled_scores = self.model(data, ranking='full')
if self.remove_seen:
seen = self.Item.to_csr(data[self.ISeen]).to(self.device).to_dense().bool()
scores[seen] = -1e23
shuffled_scores[seen] = -1e23
targets = self.Item.to_csr(data[self.IUnseen]).to(self.device).to_dense()
self.monitor(
scores, targets,
n=bsz, reduction="mean", mode=mode,
pool=['HITRATE', 'PRECISION', 'RECALL', 'NDCG', 'MRR']
)
self.monitor(
shuffled_scores, targets,
n=bsz, reduction="mean", mode=mode,
pool=['HITRATE-S', 'NDCG-S']
)
def main():
dataset: freerec.data.datasets.RecDataSet
try:
dataset = getattr(freerec.data.datasets, cfg.dataset)(root=cfg.root)
except AttributeError:
dataset = freerec.data.datasets.RecDataSet(cfg.root, cfg.dataset, tasktag=cfg.tasktag)
model = SASRec(
dataset, maxlen=cfg.maxlen,
embedding_dim=cfg.embedding_dim, dropout_rate=cfg.dropout_rate,
num_blocks=cfg.num_blocks, num_heads=cfg.num_heads,
)
# datapipe
trainpipe = model.sure_trainpipe(cfg.maxlen, cfg.batch_size)
validpipe = model.sure_validpipe(cfg.maxlen, ranking=cfg.ranking)
testpipe = model.sure_testpipe(cfg.maxlen, ranking=cfg.ranking)
coach = CoachForSASRec(
dataset=dataset,
trainpipe=trainpipe,
validpipe=validpipe,
testpipe=testpipe,
model=model,
cfg=cfg
)
coach.fit()
if __name__ == "__main__":
main()
# sampler.py
import torchdata.datapipes as dp
import random
import freerec
from freerec.data.tags import MATCHING, NEXTITEM
from freerec.data.postprocessing import ValidSampler
@dp.functional_datapipe("valid_shuffled_sampling_")
class ValidShuffleSampler(ValidSampler):
def _nextitem_from_pool(self):
for row in self.source:
user = row[self.User]
seen = self.seenItems[user]
for k, positive in enumerate(self.unseenItems[user]):
seq = self.seenItems[user] + self.unseenItems[user][:k]
unseen = (positive,) + self._sample_neg(user, k, positive, seen)
shuffled = list(seq[:-1])
random.shuffle(shuffled)
shuffled = tuple(shuffled + [seq[-1]])
yield {self.User: user, self.ISeq: seq, self.Item: shuffled, self.IUnseen: unseen, self.ISeen: seen}
def _nextitem_from_full(self):
for row in self.source:
user = row[self.User]
seen = self.seenItems[user]
for k, positive in enumerate(self.unseenItems[user]):
seq = self.seenItems[user] + self.unseenItems[user][:k]
unseen = (positive,)
shuffled = list(seq[:-1])
random.shuffle(shuffled)
shuffled = tuple(shuffled + [seq[-1]])
yield {self.User: user, self.ISeq: seq, self.Item: shuffled, self.IUnseen: unseen, self.ISeen: seen}
def __iter__(self):
if self.dataset.TASK is MATCHING:
if self.sampling_neg:
yield from self._matching_from_pool()
else:
yield from self._matching_from_full()
elif self.dataset.TASK is NEXTITEM:
if self.sampling_neg:
yield from self._nextitem_from_pool()
else:
yield from self._nextitem_from_full()
@dp.functional_datapipe("test_shuffled_sampling_")
class TestShuffleSampler(ValidShuffleSampler):
@freerec.utils.timemeter
def prepare(self):
seenItems = [[] for _ in range(self.User.count)]
unseenItems = [[] for _ in range(self.User.count)]
self.listmap(
lambda row: seenItems[row[self.User]].extend(row[self.ISeq]),
self.dataset.train().to_seqs()
)
self.listmap(
lambda row: seenItems[row[self.User]].extend(row[self.ISeq]),
self.dataset.valid().to_seqs()
)
self.listmap(
lambda row: unseenItems[row[self.User]].extend(row[self.ISeq]),
self.dataset.test().to_seqs()
)
self.seenItems = seenItems
self.unseenItems = unseenItems
self.negItems = dict()