OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment
预备知识
- 请了解 QARM.
- $\mathcal{H}_u = \{v_1^h, v_2^h, \ldots, v_n^h\}$, user historical behavior sequence, 在快手的场景下, $v$ 表示一个视频.
- $\mathcal{S} = \{v_1, v_2, \ldots, v_m\}$, 推荐的一串视频流.
- session watch time (swt), view probability (vtr), follow probability (wtr), like probability (ltr).
核心思想
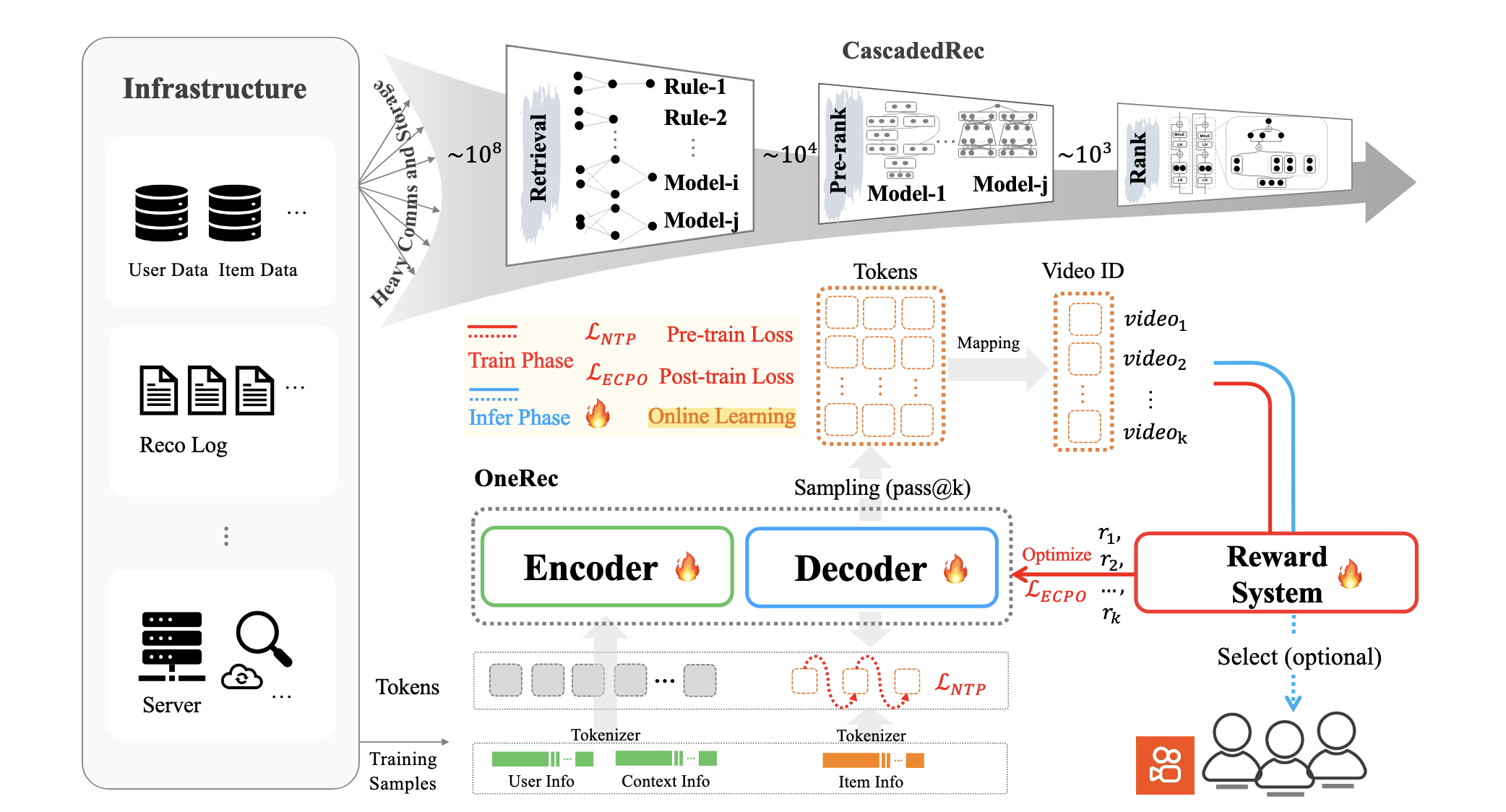
OneRec 的团队认为, 在大数据大模型大算力的当下, 推荐系统的发展可能仅仅就蹭到了大数据, 而大模型和大算力的进展一直不太让人满意. 他们认为最最主要的因素就是推荐系统"引以为傲"的 “粗排-精排” 体系. 这一套系统严重依赖特征工程和算法设计, 从而导致 算力的利用率低下 (既然整套系统都是零零碎碎的).
随着生成式推荐的发展, 各大公司都展开一系列研究, OneRec 给出了适合视频推荐的一套方案.
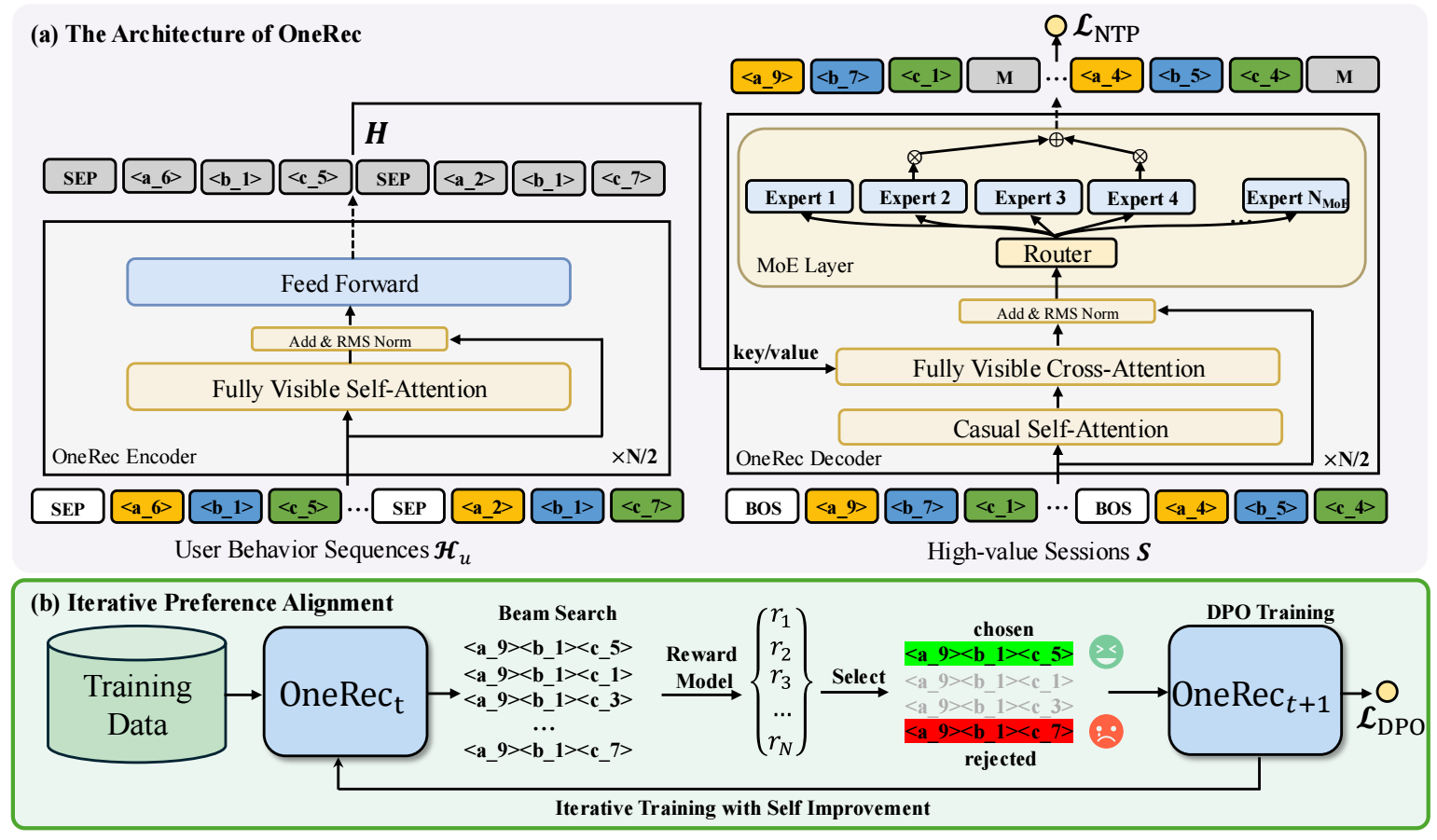
OneRec 的基本流程如下:
User: 将用户的静态/动态特征初步融合后, 通过 Encoder 得到其编码表示.
Item:
通过 Decoder 生成视频流, query 是视频流, key/value 是通过 Encoder 得到的 user 编码 (因此 OneRec 从架构上来说是类似 T5 的).
完成上述的预训练之后, 再利用 DPO 和一些特殊设计的 reward model 进行对齐训练, 这部分主要是为了使得预测结果和线上的一些指标 (swt, vtr, wtr, ltr) 进行对齐.
在预测的时候, 通过 beam search 筛选出视频流.
User Features: Multi-Scale Feature Engineering
OneRec 通过一个 Encoder 来提取 user 的编码, 作为后续 Decoder 的 Key/Value. 特别地, OneRec 对 Encoder 的输入, 即用户的特征做了特别的设计.
User static pathway: 将用户的静态特征, 包括 user identifier, age, gender 等信息进行编码:
$$ [\mathbf{e}_{uid}; \mathbf{e}_{age}; \mathbf{e}_{gender}; \cdots] \xrightarrow{ \text{Dense(LeakyReLU(Dense()))} } \mathbf{h}_u \in \mathbb{R}^{1 \times d_{model}}. $$Short-term pathway: 挑选用户最近交互的 ($L_s=20$) 个视频的 <video identifier, author identifier, tag, timestamp, playtime, duration, labels> 等信息进行融合:
$$ [\mathbf{e}_{vid}^s; \mathbf{e}_{aid}^s; \mathbf{e}_{tag}^s; \mathbf{e}_{ts}^s; \mathbf{e}_{playtime}^s; \mathbf{e}_{dur}^s; \mathbf{e}_{label}^s] \xrightarrow{ \text{Dense(LeakyReLU(Dense()))} } \mathbf{h}_s \in \mathbb{R}^{L_s \times d_{model}}. $$Positive-feedback pathway: 将用户给与最多正反馈的 ($L_p=200$) 个视频的 <video identifier, author identifier, tag, timestamp, playtime, duration, labels> 等信息进行融合:
$$ [\mathbf{e}_{vid}^p; \mathbf{e}_{aid}^p; \mathbf{e}_{tag}^p; \mathbf{e}_{ts}^p; \mathbf{e}_{playtime}^p; \mathbf{e}_{dur}^p; \mathbf{e}_{label}^p] \xrightarrow{ \text{Dense(LeakyReLU(Dense()))} } \mathbf{h}_p \in \mathbb{R}^{L_p \times d_{model}}. $$Lifelong pathway: 为了从用户最多能到 100,000 个视频的交互中抽取出长期的兴趣偏好, OneRec 采用两阶段分层压缩:
对每个用户, 分别通过 K-means 对其交互序列聚类;
聚类完毕后, 聚类中心设定为该类中距离类别中心最近的 video;
该类别中心的离散特征 (如 vid, aid, label) 直接继承自 video 的离散特征, 其它连续特征取给类内的平均;
对用户的 $L_l = 2000$ 个历史交互进行信息融合:
$$ [\mathbf{e}_{vid}^l; \mathbf{e}_{aid}^l; \mathbf{e}_{tag}^l; \mathbf{e}_{ts}^l; \mathbf{e}_{playtime}^l; \mathbf{e}_{dur}^l; \mathbf{e}_{label}^l] \xrightarrow{ \text{Dense(LeakyReLU(Dense()))} } \mathbf{v}_l \in \mathbb{R}^{L_l \times d_{model}}. $$注意, 这里视频的特征都用其对应的类别中心的特征替换;
通过 QFormer 得到最终的 $\mathbf{h}_l \in \mathbb{R}^{N_q \times d_{model}}$, 这里 $N_q$ 一般取 128.
Item Features: Collaborative-Aware Multimodal Representation
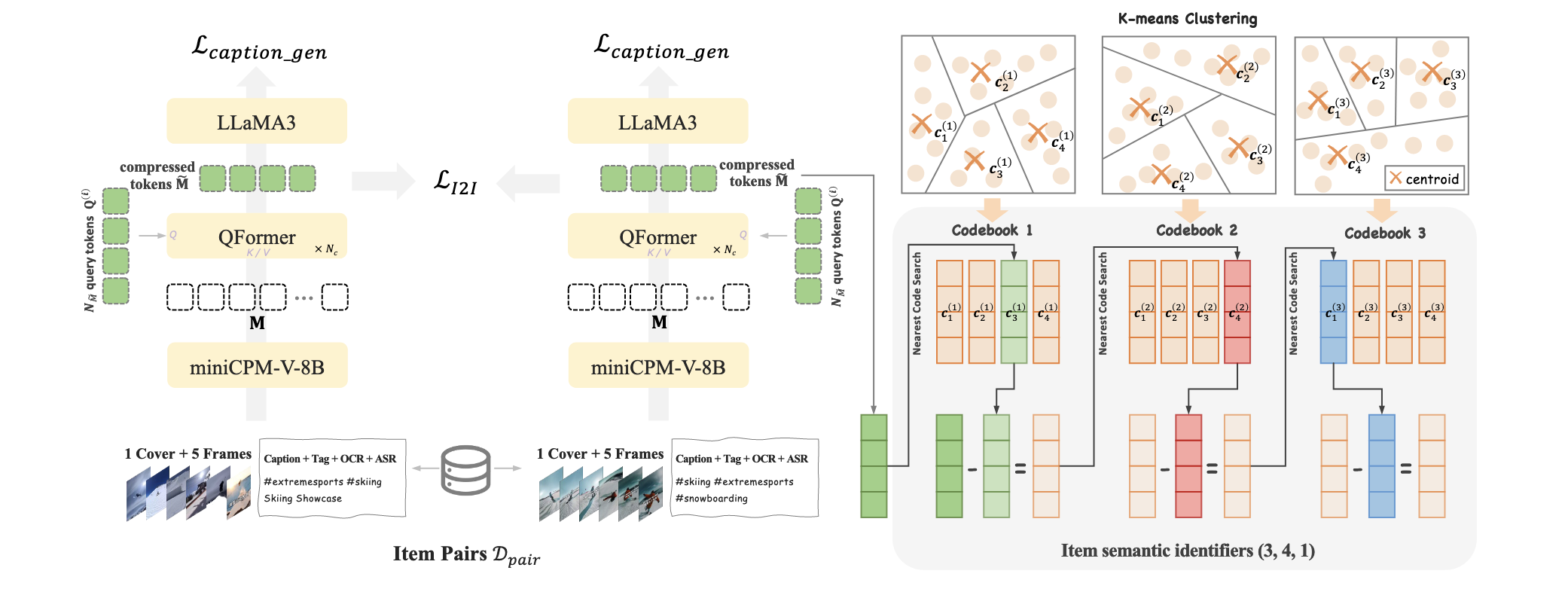
- Decoder 部分主要依赖的是 item 的离散编码, 而 item 离散编码则主要是根据一些特征通过 Residual-KMeans 得到的. 自然, Residual-KMeans 所依赖的 item features 起到了基石的作用. 这要求我们不能像 Tiger 这类最初的方法, 仅仅通过一些 freezed Encoder 模型来提取特征. 因此 OneRec 会添加如下的约束:
- 通过 miniCPM-V-8B 将多模态信息整合为 $\mathbf{M} \in \mathbb{R}^{N_M \times d_t}$ 大小的 token vectors (per item).
- 通过 QFormer 进一步融合得到 $\mathbf{\tilde{M}} \in \mathbb{R}^{N_{\tilde{M}} \times d_t}$, 通常 $N_{\tilde{M}} = 4$ (而 $N_M = 1280$).
- 通过 item-item 间的相似度构建高质量的 item-pair dataset $\mathcal{D}_{pair}$, 然后通过 item-item 间的对比学习来促使 item features 融合进这部分信息.
- 此外, 额外引入 Caption loss, 即通过 LLaMA3 来预测 Caption, 保证 features 不会丢失内容信息.
Balanced K-means Clustering
- 与 QARM 的 codebook 的确定方式的不同之处在于, 本文还强调每个类别的均分性.
Next-Token Prediction
OneRec 的训练目标和一般的有不同之处, 首先, 需要在用户的交互记录中选择 high-quality sessions (文中并未提及是要同时满足还是满足任一即可, 我感觉后者会比较合理):
- 该 session 内用户所观看的视频数 $\ge 5$;
- 该 session 内用户累积观看时长 $\ge$ 某个阈值;
- 该用户对该 session 内的视频发生了如点赞, 收藏, 分享等行为.
于是, Decoder 的输入为:
$$ \mathcal{\bar{S}} = \{ \bm{s}_{\text{[BOS]}}, \mathbf{s}_1^1, \mathbf{s}_1^2, \cdots, \mathbf{s}_1^L, \bm{s}_{\text{[BOS]}}, \mathbf{s}_2^1, \mathbf{s}_2^2, \cdots, \mathbf{s}_2^L, \cdots, \bm{s}_{\text{[BOS]}}, \mathbf{s}_m^1, \mathbf{s}_m^2, \cdots, \mathbf{s}_m^L \}, $$其中 $\mathbf{s}_{\text{[BOS]}}$ 为不同视频的分隔符.
于是, OneRec 的主要损失为:
$$ \mathcal{L}_{\text{NTP}} = - \sum_{i=1}^m \sum_{j=1}^L \log P(\mathbf{s}_i^{j+1}| [ \bm{s}_{\text{[BOS]}}, \mathbf{s}_1^1, \mathbf{s}_1^2, \cdots, \mathbf{s}_1^L, \cdots, \bm{s}_{\text{[BOS]}}, \mathbf{s}_i^1, \cdots, \mathbf{s}_i^j ]; \Theta). $$
Iterative Preference Alignment with RM
特别地, 本文还采用 Direct Preference Optimization (DPO) 来进行偏好对齐. 由于推荐场景数据反馈的稀疏性, OneRec 借助一个 reward model (RM) 首先拟合反馈, 然后再用于提升 OneRec.
对于 RM, 我们首先得到 user 的 target-aware 的表示 $\bm{h}_f \in \mathbb{R}^{m \times d}$ 序列, 然后分别计算不同的指标:
$$ \hat{r}^{swt} = \text{Tower}^{swt}(\text{Sum}(\mathbf{h}_f)), \\ \hat{r}^{vtr} = \text{Tower}^{vtr}(\text{Sum}(\mathbf{h}_f)), \\ \hat{r}^{wtr} = \text{Tower}^{wtr}(\text{Sum}(\mathbf{h}_f)), \\ \hat{r}^{ltr} = \text{Tower}^{ltr}(\text{Sum}(\mathbf{h}_f)), $$其中 $\text{Tower}(\cdot) = \text{Sigmoid}(\text{MLP}(\cdot))$. 然后通过 BCE 进行训练:
$$ \mathcal{L}_{\text{RM}} = -\sum_{xtr \in \{swt, vtr, wtr, ltr\}} \big( y^{xtr} \log (\hat{r}^{xtr}) + (1 - y^{xtr}) \log (1 - \hat{r}^{xtr}) \big). $$接下来通过 RM 来迭代地提升 OneRec:

一些有趣的实验
Parameter Scaling
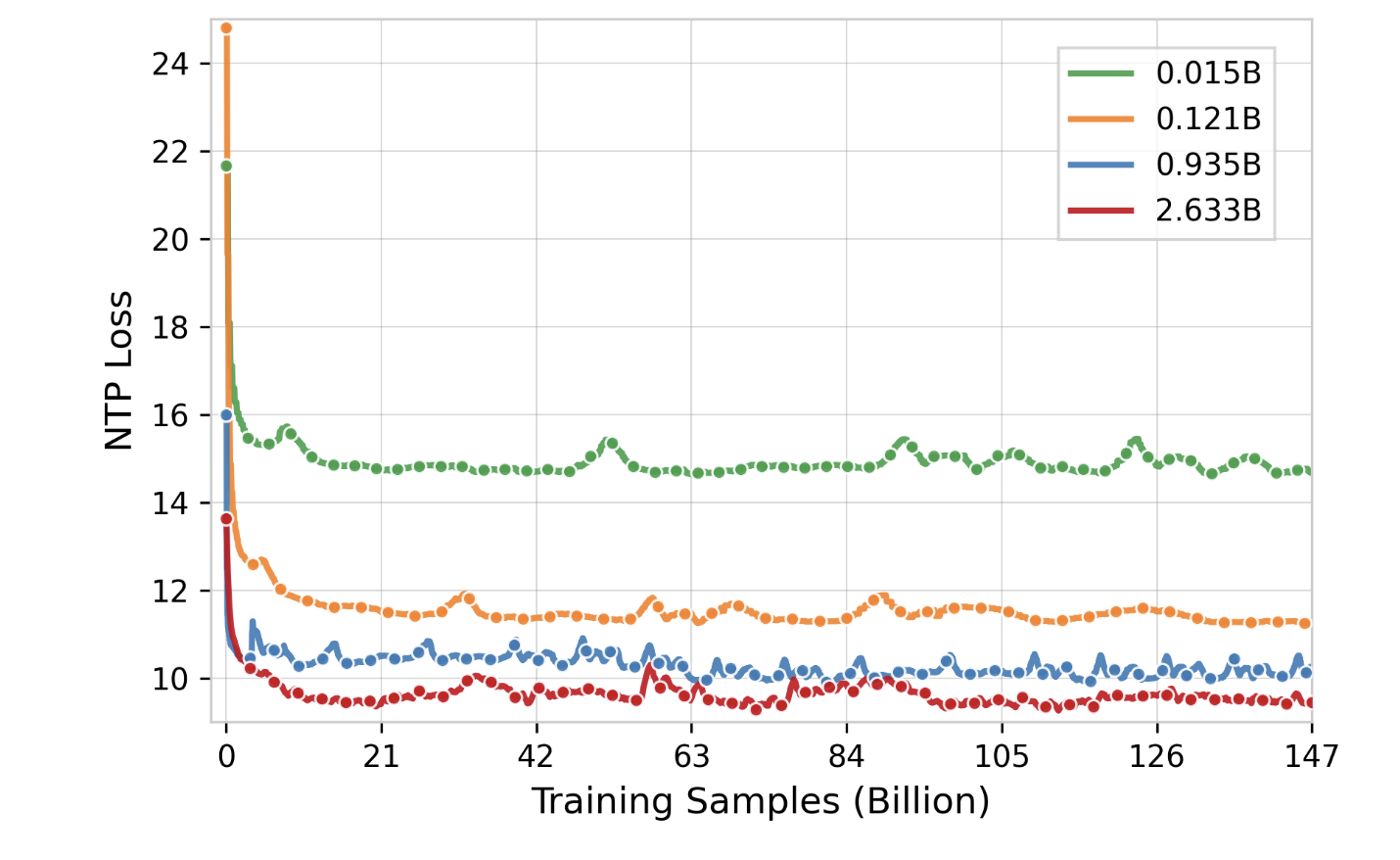
- 诚然, 随着 OneRec 参数量的增加, NTP Loss (即预训练阶段的 loss) 会有一个显著的下降, 但是这个下降并不依赖数据集的持续扩张. 实际上, 10B 的样本是一个临界点, 在这个临界点之前, 不同大小的 OneRec 都能够随着训练的进行快速收敛, 之后大家都进入了一个缓慢的收敛阶段.
Infer Scaling
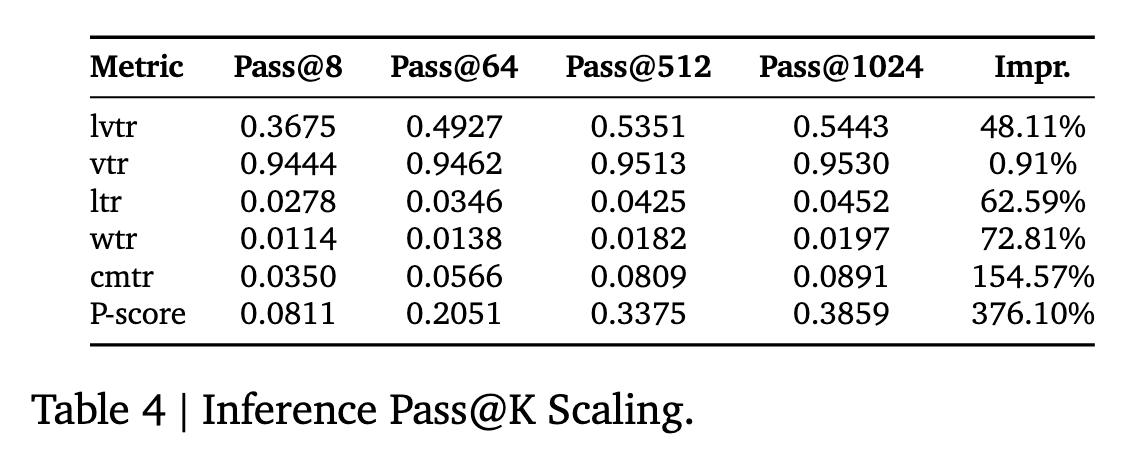
- 在推理阶段生成更多的候选 items 会极大有利于效果的提升 (尤其是是 Pass@$K=8\rightarrow 512$).
注: 如果我没理解错, $K$ 应该是指 beam search 的采样次数.
Sampling Efficiency
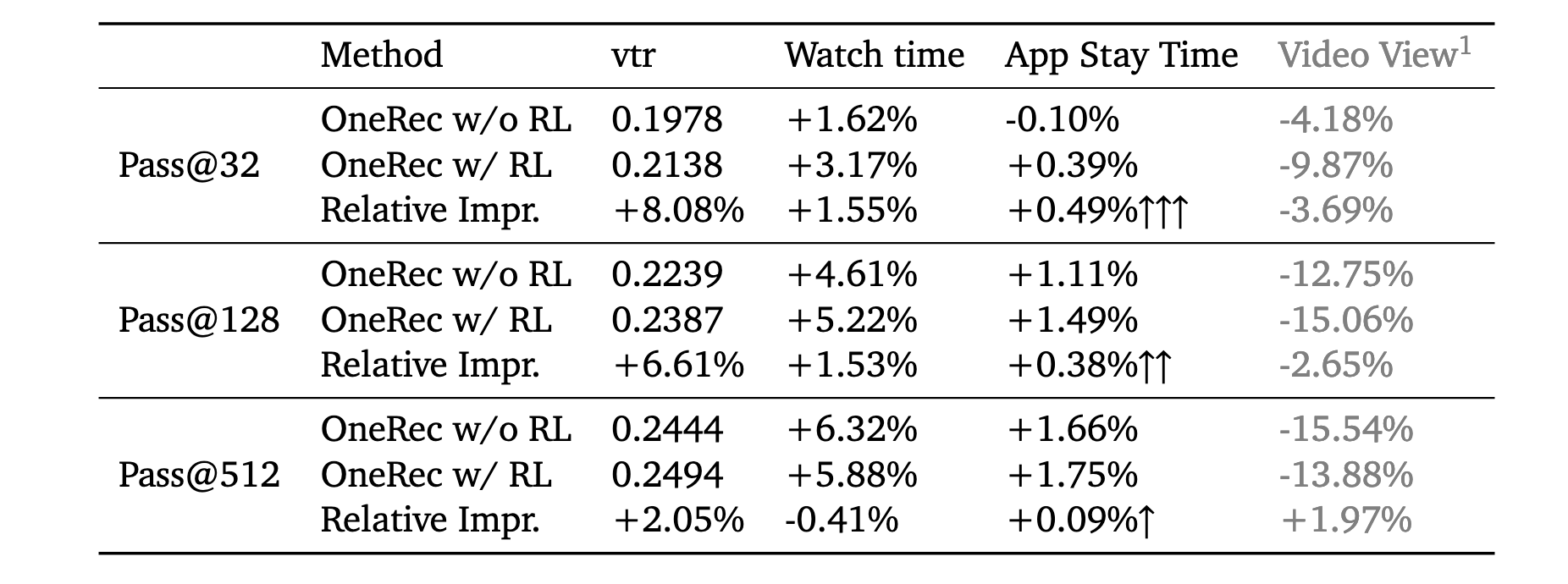
- 有很多文章生成, RL 的对齐过程其实并没有让模型学到什么新的知识, 只是让模型具备更强的输出高概率答案的能力. 上表似乎验证了这一点, 采样次数越少, RL 所带来的增益越大.