PAR$^2$-RAG: Planned Active Retrieval and Reasoning for Multi-Hop Question Answering
Content
研究背景
- (RAG) 检索增强生成是目前 QA 中应用比较广泛的技术, 其核心思想是借助 LLM 来迭代地提出需求, 从而尽可能检索出充分的 context 用于回答问题.
核心思想
-
作者认为, 不论是静态的一次性生成 queries 还是迭代式地 Query-Retrieval-Think-Query 的循环在处理多跳问题时都存在问题, 前者着重于广度, 显然没有适应多条的环境, 而后者则过于注重深度, 然而极有可能由于起点的局限性导致误差的传播越来越多.
-
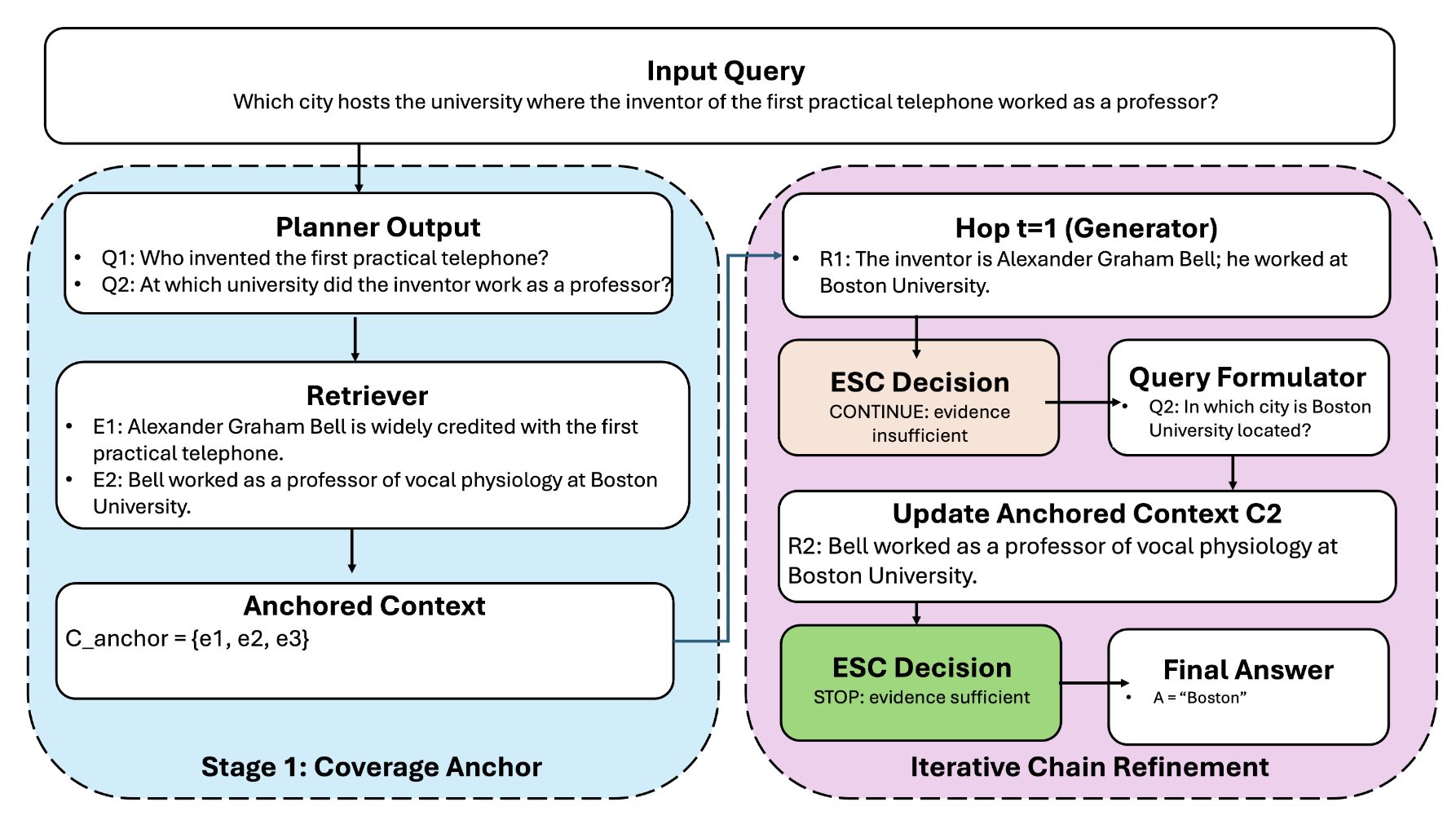
(PAR$^2$-RAG) 希望结合二者:
-
(Stage 1) 首先, 给定一个 query $q$, 一个 planner agent $\mathcal{P}$ 将 $q$ 细化为多个 sub-queries $\{q_i\}_{i=1}^m$ (要求 diverse); 然后 retriever-reranker agent $\mathcal{R}$ 根据这些 sub-queries 从文档库 $\mathcal{D} = \{d_1, d_2, \ldots \}$ 中检索相关文档, 具体地, 对于每个 $q_i$ 都检索出 top-$k$ 相关的文档, 综合这些信息得到 $C_{anchor}$.
-
(Stage 2) 在 Stage 1 中, PAR$^2$-RAG 初步检索出了具有一定广度的信息, 然而对于多条问题往往需要进一步细化 (第 $t$ 步时):
- 一个 generator agent $\mathcal{G}$ 在 context $C_t$ ($C_1 = C_{anchor}$) 和 query $q$ 下生成 response $r_t$;
- 派出 evidence sufficiency controller agent $\mathcal{E}$ 来判断当前的 context $C_t$ 以及 response 是否对于 query $q$ 是充分的. 如果已经充分, 则返回
STOP, 并终止, 否则生成新的 sub-query $q_{t+1}^*$; - retriever $\mathcal{R}$ 会根据新的 sub-query $q_{t+1}^*$ 检索出 top-$k$ 的 context, 并入到 $C_t$ 中得到新的 context $C_{t+1}$.
-