Pctx: Tokenizing Personalized Context for Generative Recommendation
预备知识
(Generative Recommendation) 区别于传统的 ID-based 的序列推荐, 每个 ID 由一组 semantic IDs 表达, 因此和语言模型一样是 Next-Token Prediction 范式. 由于不同的 items 共享一个 tokenizer, 大大减小了 embedding table, 在泛化性方面 (冷启动) 方面也更有优势.
(Vector Quantization) 生成式推荐通常利用 RQ-VAE 或者 Residual Kmeans 来将 semantic embeddings 转换成对应的 semantic IDs. 显然, 这种方式所编码的信息是局限的, 忽视了推荐中最为关键的协同信息.
核心思想

- (Pctx) 本文作者认为, 固定的 semantic IDs 限制了 item-item 间的相似度关系: 比如, 同一个手表, 有的人可能在意它的价格, 有的人可能在意它的外观. 因此作者认为, 应当探索个性化的 semantic IDs.
注: 个人不太认同这个观点, 这个问题实际上对于 dense retrieval 是严重的, 理论上 generative retrieval 是有潜力更好的解决这个问题的. 个性化的问题, 只要用户的交互历史蕴含足够的信息, 那么个性化我不认为有什么问题.
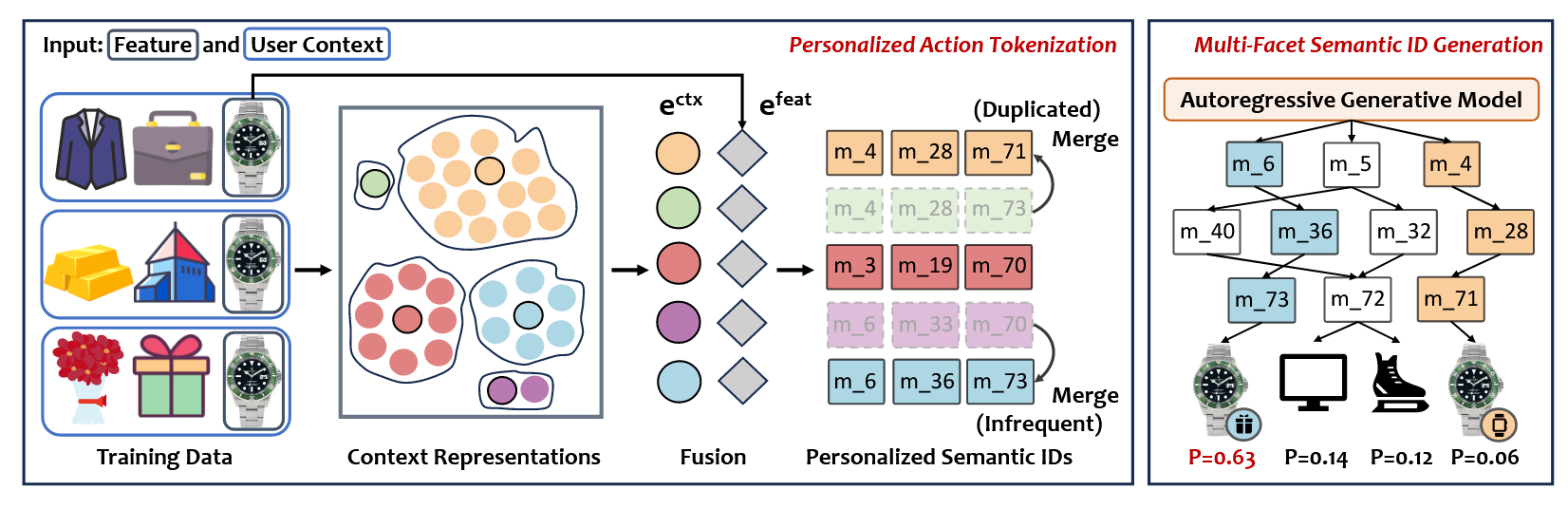
- Pctx 的个性化编码流程如下:
User Context Encoding: 首先, 通过一个传统模型 (作者建议用 DuoRec) 编码 user context:
$$ \bm{e}_{v_i}^{ctx} = f([v_1, v_2, \ldots, v_i]), $$这里 $[v_1, v_2, \ldots, v_i]$ 表示用户的交互历史.
Multi-Facet Condensation: 对于每一个 $v_i$ (most recently interacted item), 可能有多个 context (假设有 $M$ 个). 作者通过 KMeans++ 将这些 context embedding 聚类为 $C_{v_i}$ 个聚类中心 $\{\bm{e}_{v_i, k}^{ctx}\}_{k=1}^{C_{v_i}}$ (要求 $C_{v_i} \propto M$).
Semantic ID Construction: 将 Context 和 Feature 进行融合:
$$ \bm{e}_{v_i, k} = \text{concat}( \alpha \cdot \bm{e}_{v_i, k}^{ctx}, (1 - \alpha) \cdot \bm{e}_{v_i}^{feat} ). $$通过 RQ-VAE 生成 semantic IDs.
注: 感觉得不偿失.