Transformers Can Do Bayesian Inference
Content
研究背景
-
(In-Context Learning) Transformer 已经被证明拥有很强大的 in-context learning 的能力, 即 $\mathbb{P}(y|x, \mathcal{C}; \theta)$, 通过给定 context $\mathcal{C}$ (比如一些例子), Transformer 往往就能够预测对 $y$, 即使 $(x, y)$ 可能已经超出该模型的训练范畴.
-
(Bayesian Inference) 贝叶斯推断的核心逻辑是给定观测 $E$ 下 hypothesis $H$ 的后验分布:
$$ \mathbb{P}(H|E) = \frac{ \mathbb{P}(E|H) \mathbb{P}(H) }{\mathbb{P}(E)}. $$这里 hypothesis 可以理解为决定 $E$ 的生产"模型"/“逻辑”/“超参数”. 比如, 最为常见的参数后验分布: $\pi(\theta|X)$, $\theta$ 是决定 $X$ 分布的一些超参数 (如高斯分布中的均值和方差).
核心思想
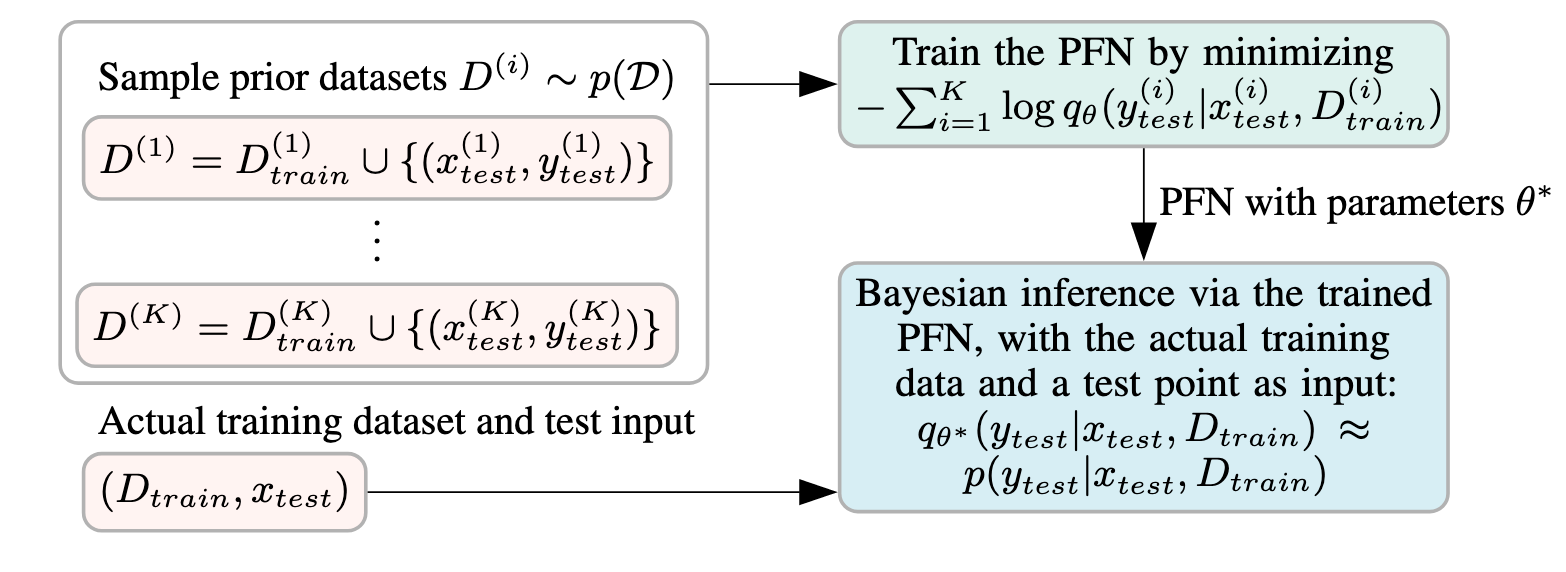
-
机器学习的很长一段时间里, 其实是在做这么一个事情: 给定训练数据 $\mathcal{D}_{train}$, 利用某个模型拟合该数据, 然后应用到测试样例中去 $(x_{test}, y_{test})$. 换言之, 一个任务场景需要一个单独的模型.
-
既然 Transformer 已经被证明了拥有很强的 In-Context Learning 的能力, 那它能不能作为一个自适应的拟合器呢? 即, 把 $\mathcal{D}_{train}$ 作为 context, 然后利用如下的方式进行预测:
$$ \mathbb{P}(y_{test}|x_{test}, \mathcal{D}_{train}; \theta). $$需要注意的是, $\theta$ 并不需要在训练集 $\mathcal{D}_{train}$ 上进行训练.

-
(Prior-Data Fitted Networks (PFNs)) PFNs 的思想其实很简单: 在一些先验数据 $\{\mathcal{D} \cup (x, y)\}$ 通过如下目标进行预训练:
$$ \ell_{\theta} = \mathbb{E}_{\mathcal{D} \cup (x, y)} \left [ -\log q_{\theta} (y|x, \mathcal{D}) \right]. $$然后推理的时候, 只需要给一些应用场景的样例数据作为 context, 就可以做推理了.
Prior Data
那么如何定义 prior data 呢?
-
(Gaussian Process) 这类代表了一种理想的从已知分布中构造数据的方案, 从而能够应用于一致的下游任务场景中;
-
(Bayesian Neural Networks) BNNs 拟合的是 $\mathbb{P}(w|\mathcal{D})$, 因此倘若要用 BNNs 进行预测, 实际上需要进行如下操作:
$$ \mathbb{P}(y|x, \mathcal{D}) = \int_w \mathbb{P}(y|x, w) \mathbb{P}(w|\mathcal{D}) \approx \frac{1}{n} \sum_{i=1}^n \mathbb{P}(y|x, w_i). $$显然, 只要求我们采样多次 $w_i$, 这个过程其实开销非常大. PFN 其实可以隐式地避免采样的过程, 我们只需要让 PFN 在预训练阶段拟合尽可能多的由 BNNs 所定义的数据分布所采样出的数据(集), 后续的 BNN inference 只需要在 PFN 中一次前向传播即可完成.
-
(Tabular Data) 本文包括后续的工作, 大部分的应用都集中在 Tabular Data 上. 作者发现用 GP/BNN Prior (on tabular datasets) 就可以很好地将预训练的 PFN 应用到一般的 Tabular Data 中去.