Proximal Policy Optimization Algorithms
预备知识
$s \in \mathcal{S}$, state;
$a \in \mathcal{A}$, action;
$p(s'|s, a)$ 在状态 $s$ 和动作 $a$ 下的状态转移概率;
$\pi(a|s)$ 给定状态 $s$ 产生动作 $a$ 的概率;
$R \in \mathbb{R}$, reward;
$\rho_0$, 初始状态 $s_0$ 的分布;
$\gamma \in (0, 1)$ reward 的折扣因子;
State-action value function:
$$ Q_{\pi}(s_t, a_t) = \mathbb{E}_{s_{t+1}, a_{t+1}, \ldots} \left [ \sum_{l=0}^{\infty} \gamma^l R(s_{t+l}) \right ]. $$Value function:
$$ V_{\pi}(s_t) = \mathbb{E}_{a_t, s_{t+1}, \ldots} \left [ \sum_{l=0}^{\infty} \gamma^l R(s_{t+l}) \right]. $$Advantage function:
$$ A_{\pi} (s, a) = Q_{\pi}(s, a) - V_{\pi}(s). $$
核心思想
强化学习的优化目标为
$$ \max_{\pi} \, \eta(\pi) = \mathbb{E}_{s_0, a_0, \ldots} \left[ \sum_{t=0}^{\infty} \gamma^t R(s_t) \right ], \\ s_0 \sim \rho(s_0), a_t \sim \pi(a_t | s_t), s_{t+1} \sim p(s_{t+1}| s_t, a_t). $$该问题可以通过 REINFORCE 利用梯度方法进行求解, 然而这种方式方差过大, 在实际中的稳定性和收敛性不太好. TRPO 在此基础上引入信赖域策略优化并取得了可喜的进展, 其优化目标的主要成分为:
$$ \mathbb{E}_t \left[ \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} A_{\theta_{old}}(s_t, a_t) -\beta\cdot \text{KL}( \pi_{\theta_{old}}(\cdot | s_t) \| \pi_{\theta}(\cdot|s_t) ) \right ]. $$(PPO) 作者在 TRPO 在实际应用中依然可能会导致训练不稳定, 且 $\beta$ 往往需要在训练阶段动态调节. 本文提出 Proximal Policy Optimization (PPO):
$$ \mathbb{E}_t\left[ \min \left( r_t(\theta) A_{\theta_{old}}(s_t, a_t), \text{clip} \Big( r_t(\theta), 1 - \epsilon, 1 + \epsilon \Big)A_{\theta_{old}}(s_t, a_t) \right) \right ], $$这里 $r_t(\theta) = \pi_{\theta}(a_t|s_t) / \pi_{\theta_{old}}(a_t|s_t)$ (注意到, $r_t(\theta_{old}) = 1$), $\epsilon$ 通常取如 $0.2$ 等较小的值.
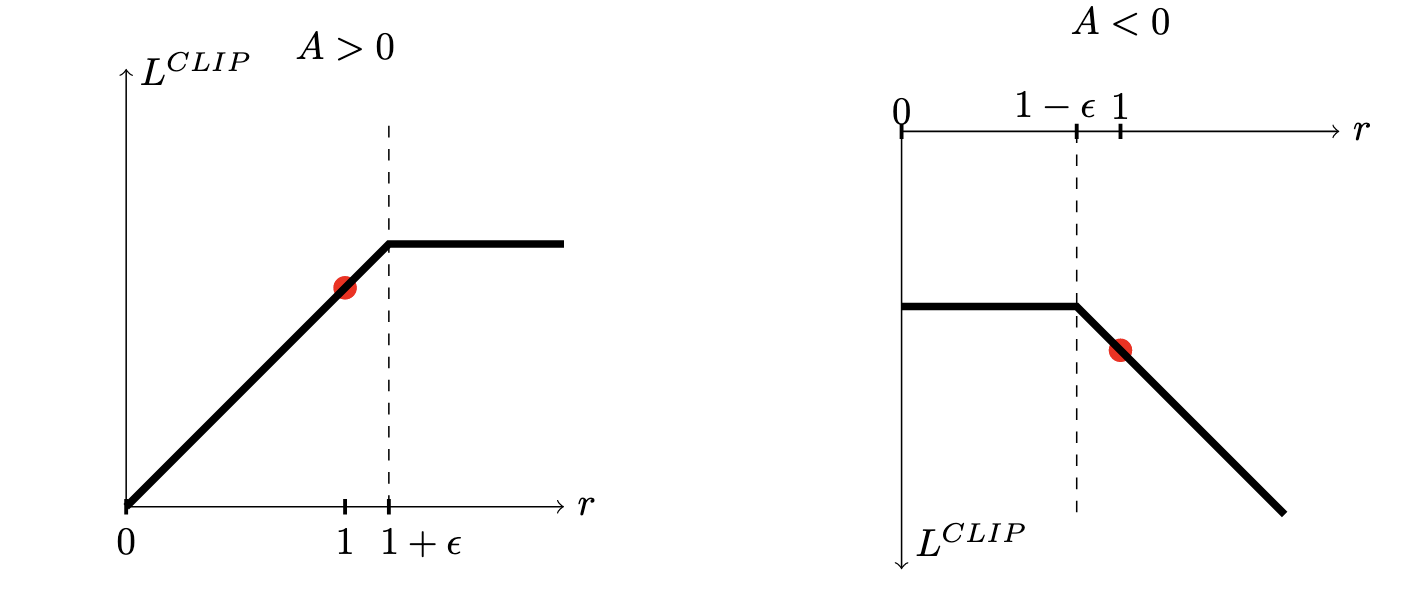
- $(s_t, a_t)$ 在如下情况下不会对模型更新:
$A > 0$ 且 $r_t(\theta) > 1 + \epsilon$: 此时说明通过 $\pi_{\theta_{old}}$ 采样的 action 是优于平均的, 因此新的 $\pi_{\theta}$ 应当在此方向上进行更新, 但是目前情况 $\pi_{\theta}(a_t|s_t) > (1 + \epsilon) \pi_{\theta_{old}}(a_t|s_t)$, 如果继续更新可能过于自信, 因此该情况下不予过度更新.
$A < 0$ 且 $r_t (\theta) < 1 - \epsilon$: 此时说明通过 $\pi_{\theta_{old}}$ 采样的 action 是低于平均水平的, 因此新的 $\pi_{\theta}$ 应当给该路径予以惩罚, 但目前 $\pi_{\theta}(a_t|s_t) < (1 - \epsilon) \pi_{\theta_{old}}(a_t|s_t)$, 保守起见, 不予以过度惩罚.