Principled Synthetic Data Enables the First Scaling Laws for LLMs in Recommendation
Content
研究背景
-
(Scaling Law) 描述了随着数据量与模型规模增大,损失函数呈幂律下降的关系,能够有效指导模型设计、训练最优配比等。然而在推荐领域,这一现象并不突出。
-
(数据合成) 很多领域的数据往往不易直接获取,因此数据合成是一个重要途径,通常称这类研究为 data-centric 的研究。推荐系统看似有着大量的交互数据,但整体交互信息依旧非常稀疏(相较于 User × Item 的规模);另一方面,推荐场景下的用户行为具有较强的主观性,因此存在大量噪声。或许正是因为数据的质量和多样性不足,导致 Scaling Law 在推荐场景并不突出。
-
(术语说明)
- CPT: Continual Pre-Training, 指在某个预训练模型基础上继续训练;
- UIH: User Interaction History;
- CF: Collaborative Filtering.
核心思想
- 之前的一些研究指出,数据的多样性很大程度上决定了 Scaling Law 现象能否被观察到,而真实推荐数据反而缺乏这类性质。因此本研究的核心是通过合成多样化的推荐数据来激发 Scaling Law 现象。
Semantic ID Tokens
-
为了统一性和泛化性, 作者首先按照生成式推荐常用的方式将 Item (文本嵌入) 编码为 Semantic IDs: 作者比较了
Pre-trained Sparse Autoencoder,RQ-VAE,RQ-KMeans,发现Pre-trained Sparse Autoencoder虽然不是 domain-specific 的,但效果却最佳。因此,对于某个 item,它在 LLM 中是以如下形式存在的:<RECTOKEN> REC6594 REC5411 REC1547 REC941 REC7587 REC7639 REC3383 REC6576 </RECTOKEN>
Item-Text Alignment Data
-
第一类合成数据是 Semantic IDs $\rightarrow$ Text 的预测数据:
This item <RECTOKEN> REC6594 REC5411 REC1547 REC941 REC7587 REC7639 REC3383 REC6576 </RECTOKEN> is described as [redacted] lotus yoga seed bead bracelet, by Handmade in Women › Jewelry › Necklaces.即希望通过这些数据将语义信息进一步绑定到 semantic IDs 中.
Collaborative Filtering (CF) Data
-
为了让 LLM 能够理解某个推荐场景下各个商品的统计性质, 通过构造如下数据来显式注入:
When a user interacts with item <RECTOKEN> REC3078 REC3311 REC7479 REC2862 REC5552 REC4015 REC6914 REC4637 </RECTOKEN>, there is a 4.9% probability they will also interact with item <RECTOKEN> REC3078 REC3311 REC7479 REC4015 REC5211 REC2862 REC1723 REC6914 </RECTOKEN> (confidence: 0.049, lift: 652.45)
Synthetic User Interaction Histories (UIH)
-
用户的行为数据是相当关键的推荐数据, 为了模拟这部分数据, 本文在共现图的基础上, 仿照 Node2Vec 的二阶随机游走来采样用户序列, 具体地, 对于当前节点 $v$, 它游走到节点 $x$ 的(未归一化)概率为:
$$ \pi_{v \rightarrow x} = \left \{ \begin{array}{ll} \frac{1}{p} \cdot w_{v, x} & x = t, \\ 1 \cdot w_{v, x} & w_{x, t} \not = 0, \\ \frac{1}{q} \cdot w_{v, x} & \text{otherwise}. \end{array} \right . $$这里 $w_{v,x}$ 表示 $(v, x)$ 边上的权重, $t$ 表示游走过程中 $v$ 之前的一个节点, $p, q$ 是人为设置的超参数, 用于控制 exploration 和 exploitation. 由此, 我们会得到如下的序列数据:
A user interacted with the following sequence of items: <RECTOKEN> REC870 REC5932 REC6271 REC1852 REC1624 REC409 REC6034 REC3608 </RECTOKEN>, <RECTOKEN> REC870 REC5524 REC180 REC4637 REC5552 REC6862 REC6033 REC4948 </RECTOKEN>, <RECTOKEN> REC7402 REC1581 REC5202 REC5289 REC2325 REC5067 REC6960 REC73 </RECTOKEN>, <RECTOKEN> REC1815 REC4896 REC2334 REC7479 REC4502 REC4861 REC1295 REC6855 </RECTOKEN>, <RECTOKEN> REC7479 REC1815 REC2334 REC3927 REC7667 REC2958 REC6513 REC4896 </RECTOKEN>, <RECTOKEN> REC1815 REC4224 REC5068 REC2334 REC4861 REC6855 REC7766 REC2410 </RECTOKEN>, <RECTOKEN> REC1815 REC2633 REC2433 REC2372 REC650 REC4064 REC2334 REC1295 </RECTOKEN>, <RECTOKEN> REC1815 REC5412 REC6298 REC3831 REC6513 REC138 REC5680 REC4210 </RECTOKEN>
关键洞察
实验设置
-
Base Model:
Qwen3(0.6B, 1.7B, 4B, 8B) -
Dataset:
- General:
cosmopedia-v2,fineweb-edu-dedupandpython-edu; - Recommendation:
merrec.
- General:
-
CPT Hyperparameters:
batch_size: 512,context_window: 512,learning_rate (linear warmup and cosine decay schedule): 1e-4,163B tokens. -
Evaluation Metric:
- General domain: 在通用数据上的结果;
- Item-text: item-text pairs 预测;
- CF both seen: CF data, 其中两个 items 均出现在训练数据中, 但没有作为 pair 出现, 观察是否能预测对概率;
- CF one unseen: 其中一个 item 没出现过;
- CF both unseen: 二者均未出现过;
- UIH OOD: 测试集上的 UIH 数据;
- UIH full graph: 训练和测试集上的完整 UIH 数据.
-
Scaling Laws:
-
本文主要考虑固定模型下, loss 关于 data size $D$ 的 scaling laws:
$$ \ell(D) = L_{\infty} + A D^{-\alpha} $$$\alpha$ 越大, 说明数据量增加所带来的增益越多.
-
此外, 稍微考虑结合 model size $N$ 和 data size $D$ 的联合 scaling laws:
$$ \ell = E + A N^{-\alpha} + B D^{-\beta}. $$
-
明显的 Scaling Laws
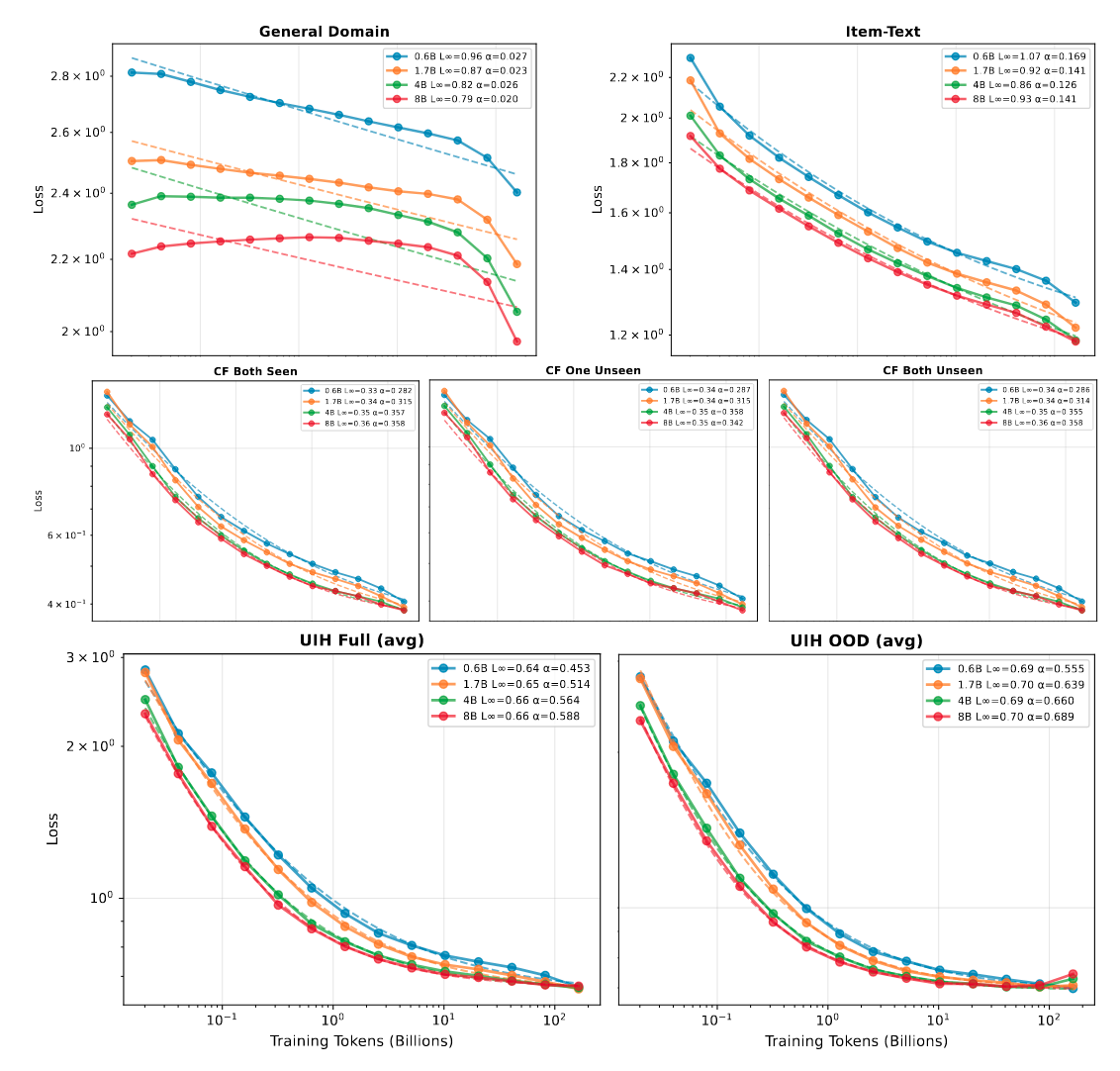
- 对于上述不同的测试环境, 均表现出了对于合成数据明显的 Scaling Laws:
不同场景下模型和数据的影响力

-
可以看到,对于 General/Item-Text 这类传统语言场景,模型规模带来的增益 $\gg$ 数据量带来的增益;而对于 CF 和 UIH 任务,数据量的重要性则明显增加。换言之,推荐任务更依赖大量高质量且多样化的推荐数据。
-
(Predictability) $E$ 表示最理想的 loss,因此反映了该场景的可预测性(越低说明任务越确定、越简单)。从中可以看出,CF 场景明显更为确定;UIH 由于引入了序列变化,可预测性有所下降。值得注意的是,主观性较强的用户行为序列,其可预测性并未显著低于传统语言任务。
不同合成数据的非对称影响
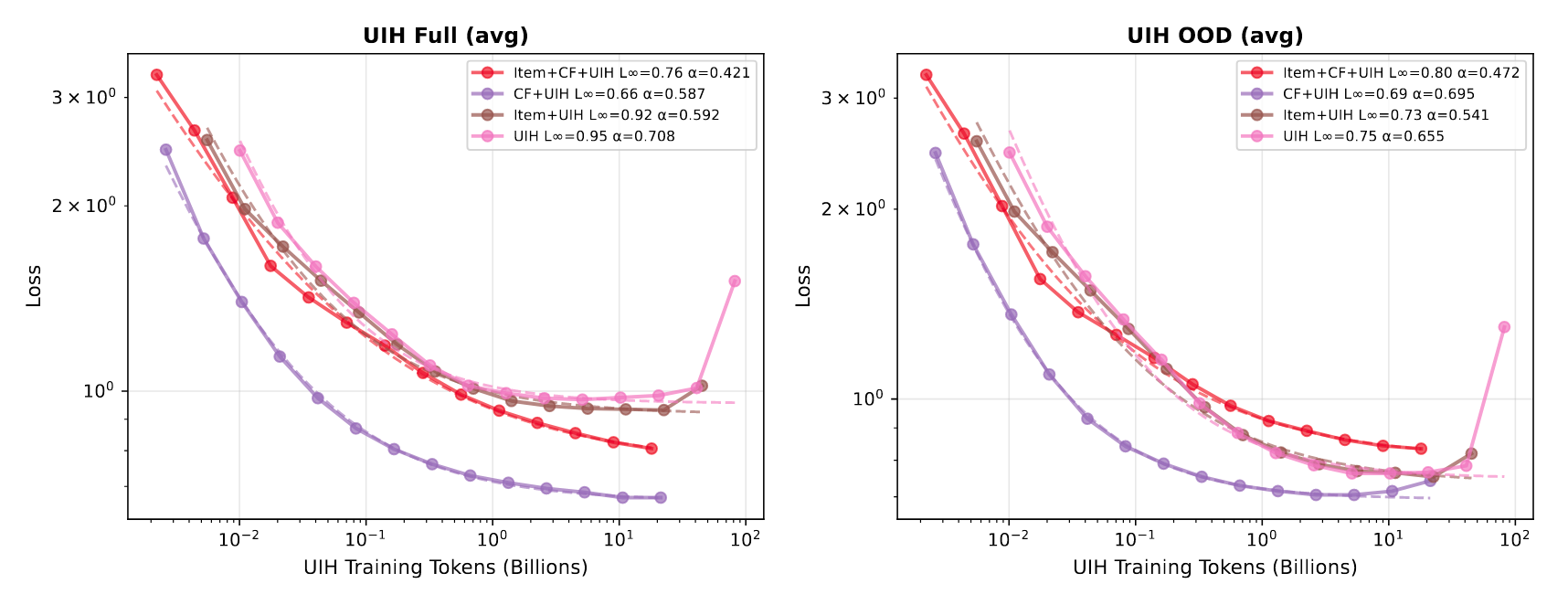
- 虽然整体上 General + 各类合成数据混合的效果最好,但不同数据之间的增益影响是不对称的:引入 CF 数据对 UIH 有明显增益,反之引入 UIH 数据对 CF 任务的影响却不大。
Domain-specific 数据不可或缺
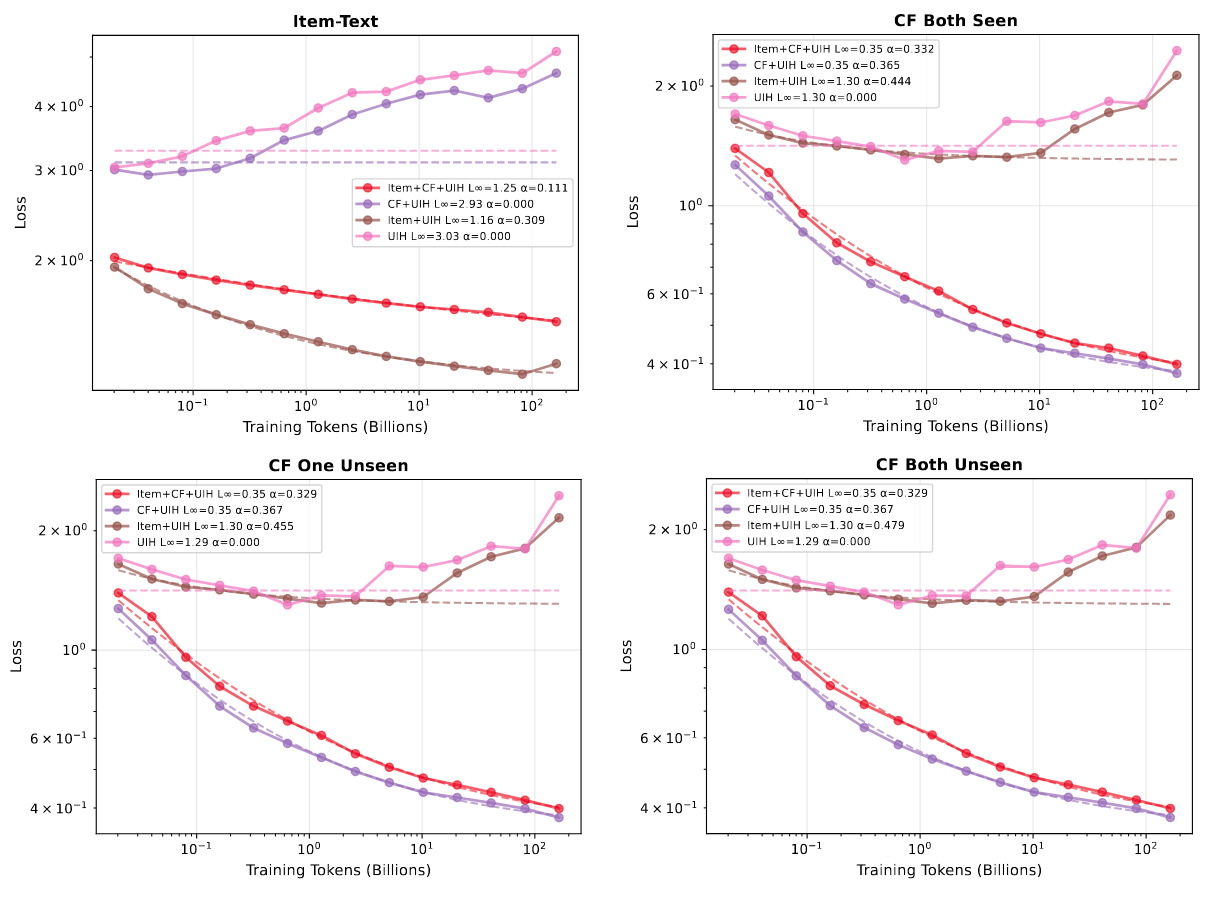
- 虽然不同场景的合成数据具有一定的跨任务迁移能力,但要在特定任务上取得好的表现,仍需使用该类数据参与训练。
继往开来
相当有意思, 扎实的工作.