Progressive Semantic Residual Quantization for Multimodal-Joint Interest Modeling in Music Recommendation
预备知识
(向量量化) 现阶段, 推荐系统倾向于不直接使用 textual/visual embeddings, 而是将他们转换成 semantic IDs, 再利用.
(Residual Quantization) 残差向量量化, 包括 Residual KMeans, RQ-VAE, 进一步使得同一组 SID 内的各 ID 存在某些联系, 从而得到更准确的表示.
核心思想
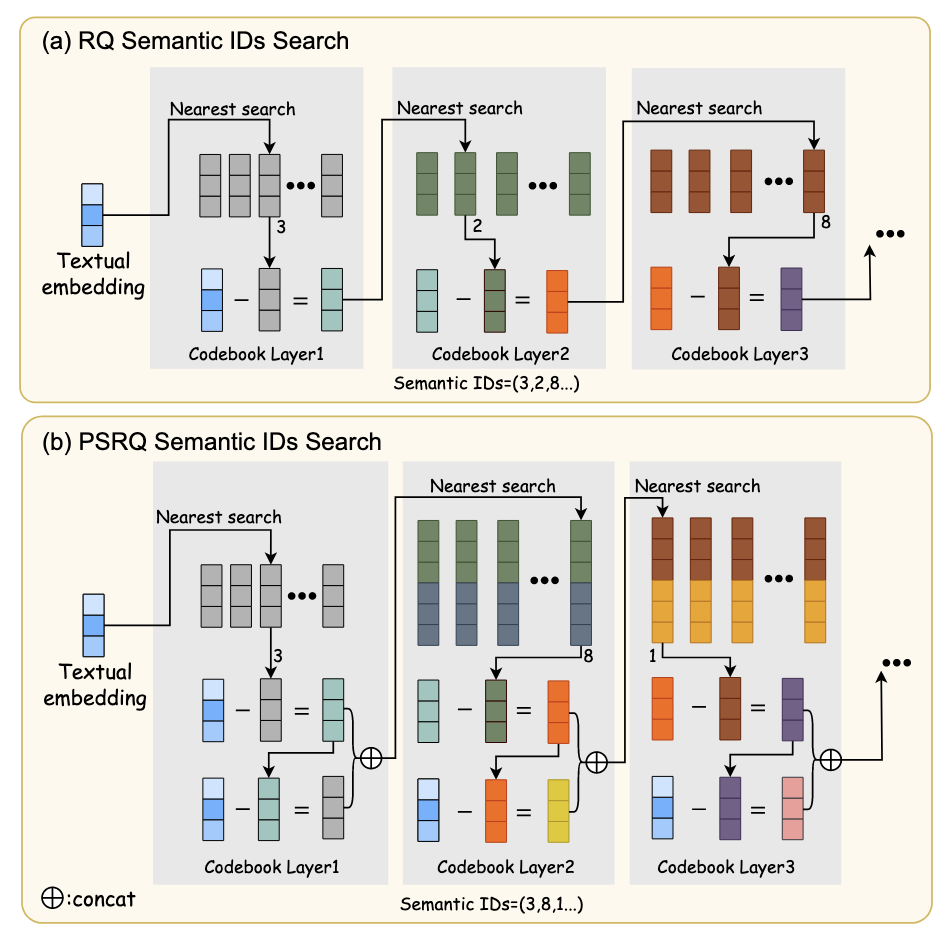
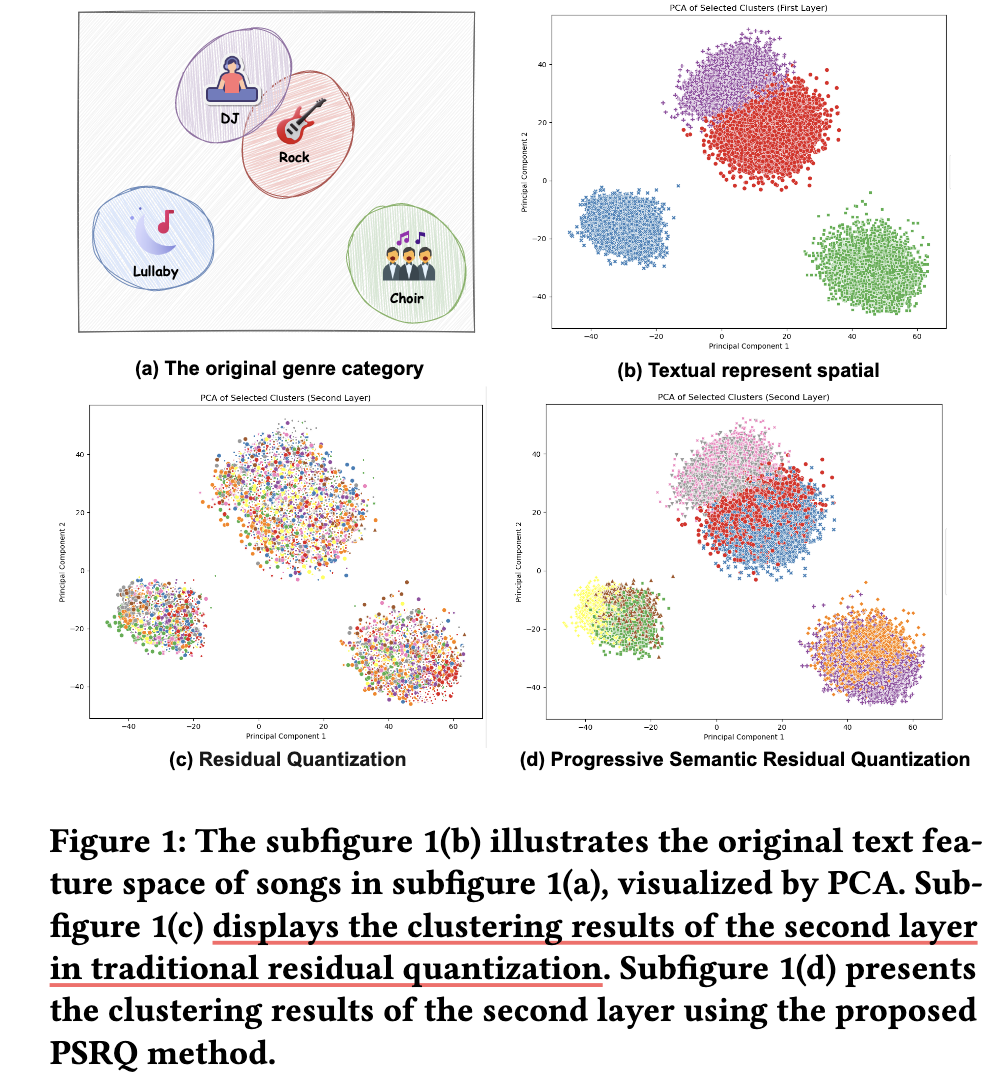
- 如上图所示, 一般的残差量化, 实际上就是每次将剩余的信息进行一个编码的过程, 将整个过程中得到的 IDs 作为最终的 Semantic IDs. 但是作者发现, 这种方式得到的’分类’, 除了第一个之外, 几乎没啥可解释性:
因此, 本文提出的 PSRQ, 会在原有的残差的基础上, 拼接一段原本向量的补. 具体的, 给定模态特征 $X^m \in \mathbb{R}^{n \times d}$:
$$ X_1^m = X^m, \\ C_1 = \text{K-means}(X_1^m, k), \\ X_2^m = X_1^m - \text{NearestRep}(X_1^m, C_1) \\ C_2 = \text{K-means}(X_2^m \oplus (X^m - X_2^m), k), \\ \vdots \\ X_l^m = X_{l-1}^m - \text{NearestRep}(X_{l-1}^m, C_{l-1}) \\ C_l = \text{K-means}(X_l^m \oplus (X^m - X_l^m), k). $$这里 $k$ 表示 K-means 的类别数, $\oplus$ 表示拼接操作.
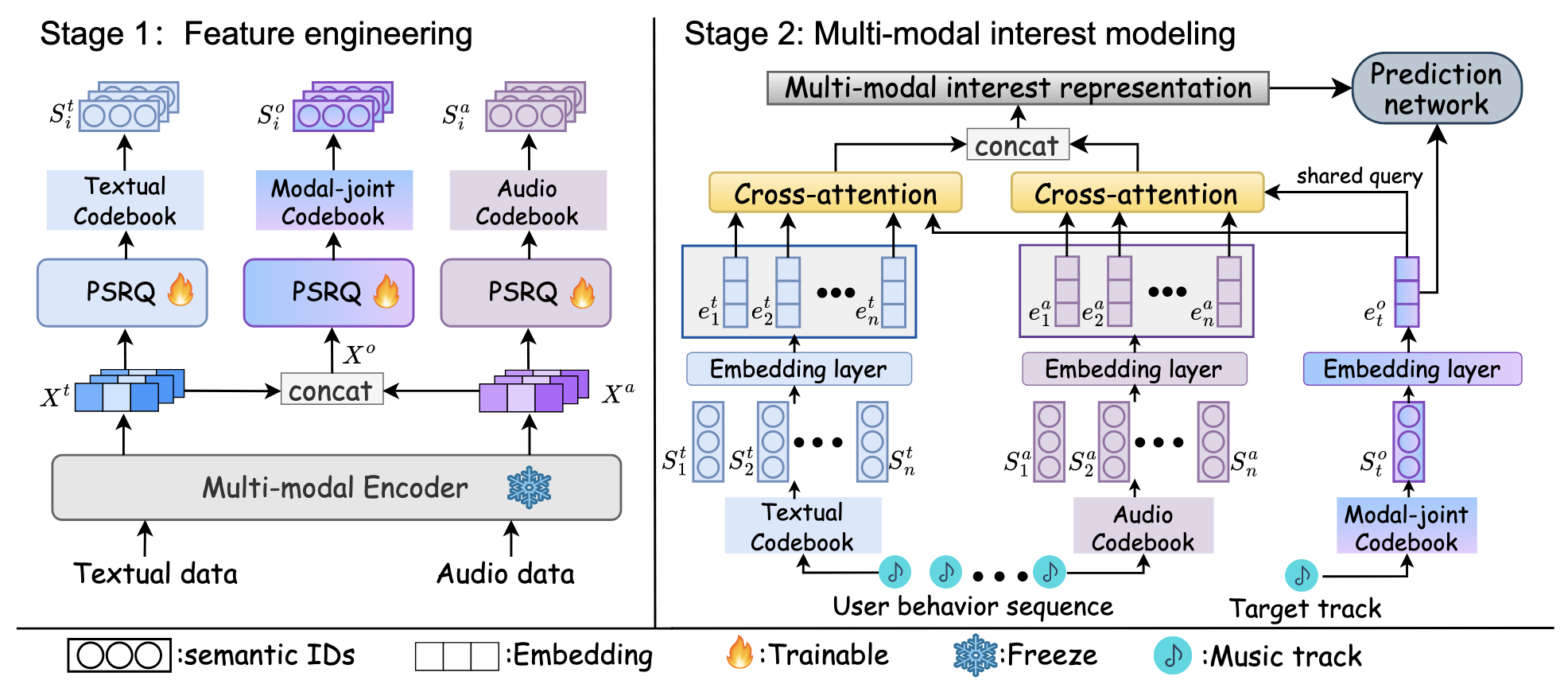
(Multi-Codebook Cross-Attnetion) 特别地, 本文设计一个特殊的模型用于同时利用多模态特征, 减弱模态间 GAP 所带来的影响.