User Behavior Simulation with Large Language Model based Agents
Content
研究背景
-
(User Simulation) 想要获得足够的用户行为数据是困难的, 这里既有隐私的问题, 又有噪声的问题. 用户模拟/仿真则提供了另外一条思路, 有望实现可控的多样的用户数据.
-
(Multi-Agent System) MAS 相较于一般的 CoT/RAG, 主要在于它可以主动调用工具, 也可以将一些必要的信息转换为 memory 方便后续的检索. 换言之, MAS 很重要的一点就是 memory 以及 action 的设计.
核心思想
Profiling Module: 角色初始化
-
在现实生活中, 每个 User 的性格、年龄、性别等属性决定了行为逻辑, 因此这部分希望通过设定这些属性来初始化角色. 作者认为, User 可以大致划分为如下几类:
- Watcher: 这类 User 倾向于主动为交互过的商品打分;
- Explorer: 这类 User 会主动尝试那些他们听闻过的商品;
- Critic: 这类 User 往往对商品质量有很高的要求, 常常对商品和背后的推荐算法提出问题;
- Chatter: 这类用户广泛参与交流, 交互行为受到朋友的深刻影响;
- Poster: 这类用户享受在社交平台上分享, 因此容易对网络上的一些其他用户产生影响.
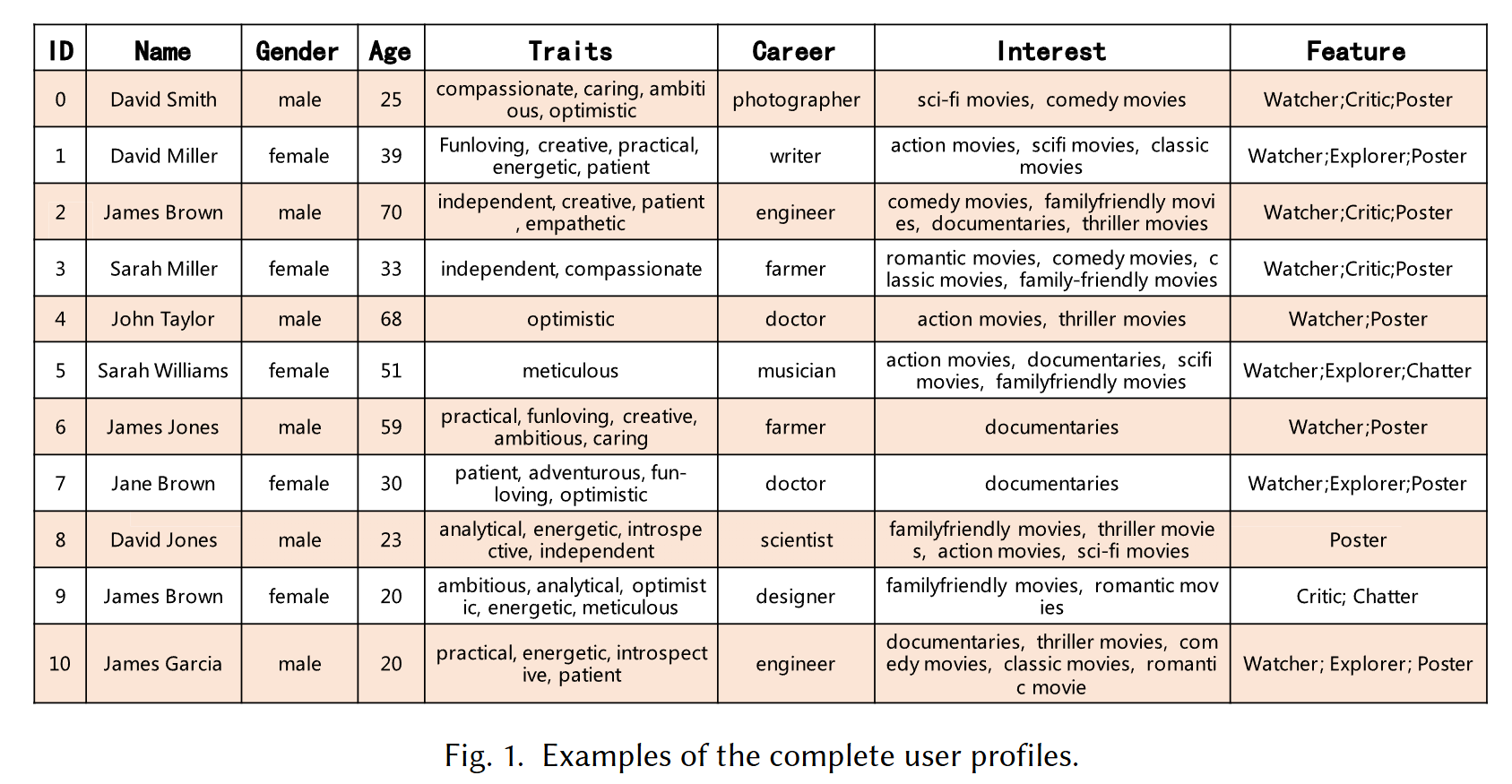
- 具体的角色初始化可以通过: 1) 手动设定; 2) AI 生成; 3) 一些和真实数据拟合的方法.
Memory Module
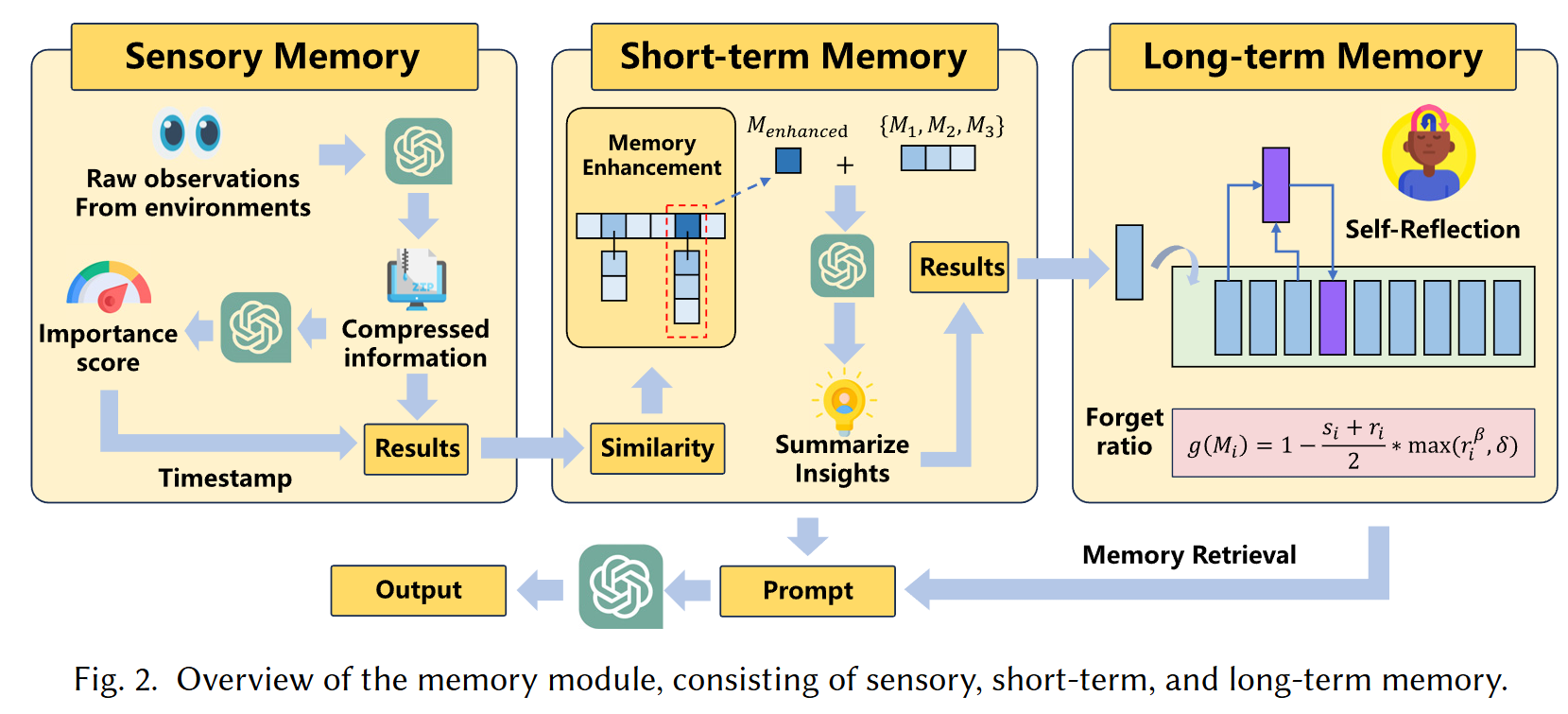
-
动态的记忆模块能够帮助模型快速检索到关键背景信息, 从而做出更好的决策. 作者根据认知科学, 认为记忆模块应当为三个层层递进的模块:
-
Sensory Memory: Agent 的观测结果通过如 LLM 压缩后得到三元组 $(c, s, t)$ Sensor Memory $M$. 这里 $c$ 为压缩后tcontent, $s$ 表示 1-10 的得分 (越高越重要, 通常和 Item 相关的 content 因给予更高的得分), $t$ 表示 timestamp;
-
Short-term Memory: 短期记忆 $\text{MEM} = \{M_1, M_2, \ldots, M_n\} \subset \mathcal{C} \times \mathcal{S} \times \mathcal{T}$, 其中每个 $M$ 都是一个 sensory memory. Short-term Memory 就是记录 sensory memory 被反复强化的程度, 并判是否应该转换为 long-term memory. 假设有一个新的 sensory memory $M_{n+1}$ 且它和 $M_i$ 的相似度最高, 则标记 $M_i$ 记忆被强化了. 如果相似度都不太高, 就直接加入到 MEM 中. 当一段记忆被强化超过 $K$ 次后, 将其转换为 long-term memory;
-
Long-term memory: 长期记忆会保存一个较长的周期, 但是依旧需要考虑遗忘机制, 遗忘概率为:
$$ g(M_i) = 1 - \frac{s_i + r_i}{2} \cdot \max(\gamma_i^{\beta}, \delta), $$这里 $s_i, r_i \in (0, 1)$ 为 normalized recency and importance scores, 越大表示 $M_i$ 越新越重要. $\max(r_i^{\beta}, \delta)$ 的存在能够保证久远的记忆依旧能够被回忆, $\delta$ 越小记忆越好.
-
-
(Memory 操作) 大概有如下几种操作:
- Memory Writing: 上述过程已经讲述了各种 Memory 的存储操作;
- Memory Reading: 为了检索和特定 query 相关的记忆, Agent 会从 long-term memory 中检索 Top-$N$ 最相似记录同时返回所有的 short-term memory;
- Memory Reflection: 给予一些 long-term memory, 我们可以合并得到 high-level 的直觉, 这个操作可以降低记忆的存储开销.
Action Module
-
用户模拟依赖 MAS 进行一些 browsing, chatting 等操作, RecAgent 提供如下的行为:
- Searching Behaviors: User Agent 可以主动搜索一些感兴趣的商品;
- Browsing Behaviors: User Agent 也可以被动接受推荐结果;
- Clicking Behaviors: User Agent 可以选择哪些他们最感兴趣的商品: 点击, 购买;
- Next-page Behaviors: User Agent 如果对当前的推荐列表都不满意可以请求更多的推荐结果.
-
为了产生的 actions 足够合理, RecAgent 融入:
- Profile Information: Agent 需要以初始化的角色性格为蓝本;
- Memory Information: Agent 的决策需要依赖过去的 memory;
- Instruction: 也可以添加额外的指令让 User Agent 做出特定的行为;
- Context: 对于当前时间, 环境的一些基本描述.
交互模拟
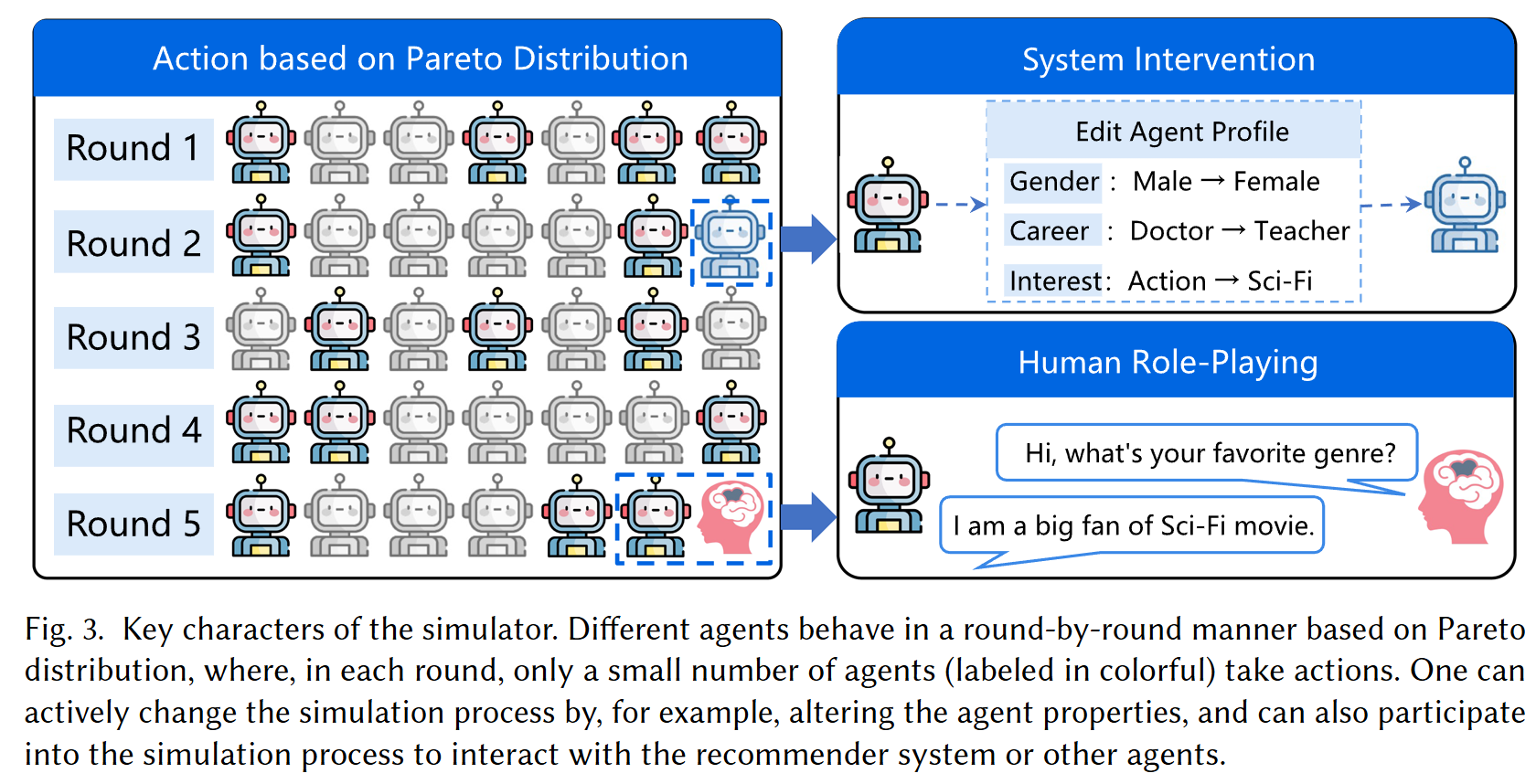
-
有了 Agent 的基本定义, 我们可以模拟真实环境下的 User 行为. RecAgent 支持多种操作.
-
(Round-based Execution) Agents 可以一轮一轮地参与交互, 做出决策和反馈. 特别地, 为了符合真实世界场景 (少部分用户产生绝大多数交互), RecAgent 设定用户活跃度服从一个 Pareto 分布 (长尾): 用户活跃度 $x$ 服从
$$ p(x) = \frac{\alpha x_{\min}^{\alpha}}{x^{\alpha + 1}}. $$ -
(Recommendation Algorithm) RecAgent 中的推荐算法是解耦的, 可以部署任意的推荐算法, 因而可以直接用于评估不同的推荐算法.
-
(Role Playing) 真实的用户也可以参与进多轮交互中, 与推荐算法或者其他 Agents 交互.
-
(System Intervention) 在交互过程中, 我们可以直接进行干预 (比如, 改变 Agent 的一些属性), 这个能够帮助我们研究一些因果问题.
信息茧房实验
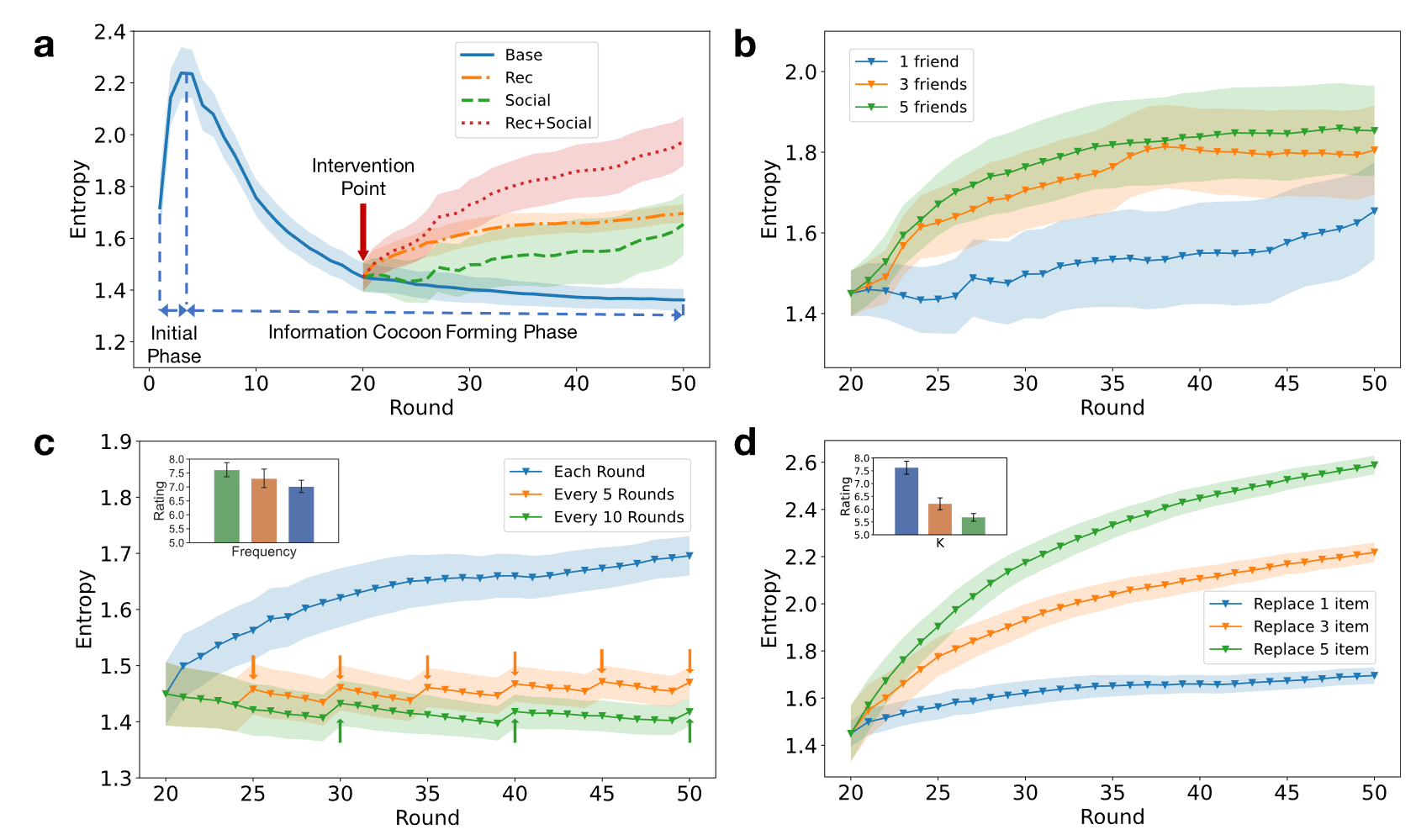
- 我们可以直接利用 RecAgent 来模拟信息茧房的产生. 作者将矩阵分解作为基本的推荐算法, 然后观察 Agent 的搜索和系统推荐的多样性的变化情况:
-
图 (a) 蓝色线条展示了随着 round 的增加, 搜索和推荐结果多样性逐渐下降的结果, 表明信息茧房愈发严重;
-
有两种方式可以缓解这种情况, 一是增加推荐的随机性 (Rec), 另一种是给这个 User 添加更多的社交关系, 使得他能够跳出信息茧房, 图 (a) 的另外几条线展示这两种方法以及混合方法的功效.
-
图 (b), (d) 展示了增加朋友数量和推荐随机性产生变化的幅度;
-
图 (c) 进一步展示的人为干预频率对缓解信息茧房的重要性.
注: RecAgent 已经展示了 MAS 在研究社会问题的潜力, 当然, RecAgent 的主要问题是有些假设感觉还是太想当然了, 缺乏一些理论支撑.