RecBase: Generative Foundation Model Pretraining for Zero-Shot Recommendation
预备知识
(Generative Foundation Recommender) 有不少的研究在追逐推荐系统的基模, 以期待超强的 Zero-Shot 能力 & 卓越的 Cross-Domain 能力. 生成式推荐无疑是导向这个目标的重要手段之一.
(Semantic ID) 通过 Item 的语义表征首先编码得到 Semantic ID (SID) 已经是目前的生成式推荐的主流方案. 通常是利用 RQ-VAE 或者 Residual KMeans 实现.
就我个人的尝试而言, 训练此类 Foundation Model 的难点在于糟糕的数据质量以及不可忽视的 Domain Gap. 似乎 RecBase 的一些举措并不足以解决这两个问题.
核心思想
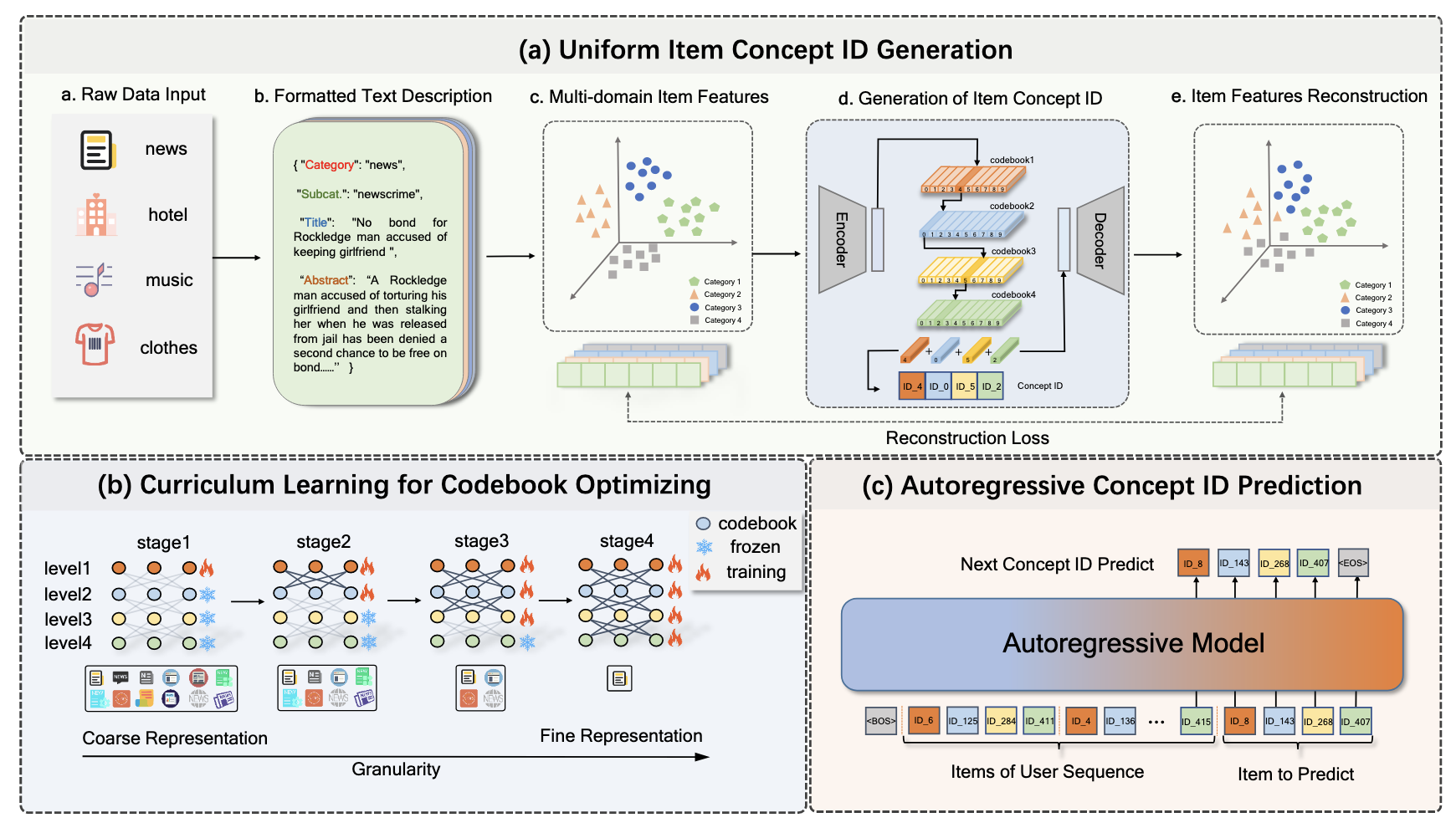
(Formatted Text Description) RecBase 仅利用数据集中提供的文本信息, 通过统一的模板进行编排, 然后通过 NV-Embedding model 提取特征.
(Curriculum Learning Enhanced RQ-VAE (CL-VAE)) 作者发现, 采用简单的 RQ-VAE 进行 SID 编码, codebook 的利用率很低, 因此提出用课程学习的方式进行解决. 即, 先训练靠前的 codebook (其余的 freeze) 然后再训练后面的.

特别的, RecBase 居然真的采用 VAE 的架构, 而且会采取一个 entropy loss 来鼓励 codebook 中向量的均匀性.
(Autoregressive Modeling) 在得到每个 Item 的 SID 后, RecBase 按照常规的自回归方式训练 (架构 follow Qwen2).
- Base (0.3B):
hidden_size=1024;intermediate_size=1024;num_heads: 16;num_layers: 24; - Large (1.5B):
hidden_size=1536;intermediate_size=8960;num_heads: 12;num_layers: 28.
- Base (0.3B):
(Inference) 有趣的是, RecBase 用在了 CTR 任务上, 这块没有看太明白, 应该是将候选的 Item 的联合概率作为 score.