Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning
Content
研究背景
- (LLM 幻觉) LLM 的幻觉问题是困扰大家的一个核心问题, 很多方法尝试利用 Graph (或者准确地说, 知识图谱), 来缓解这一问题, 然而, 这引发了如何让 LLM 在复杂的图上进行正确推理的问题.
核心思想
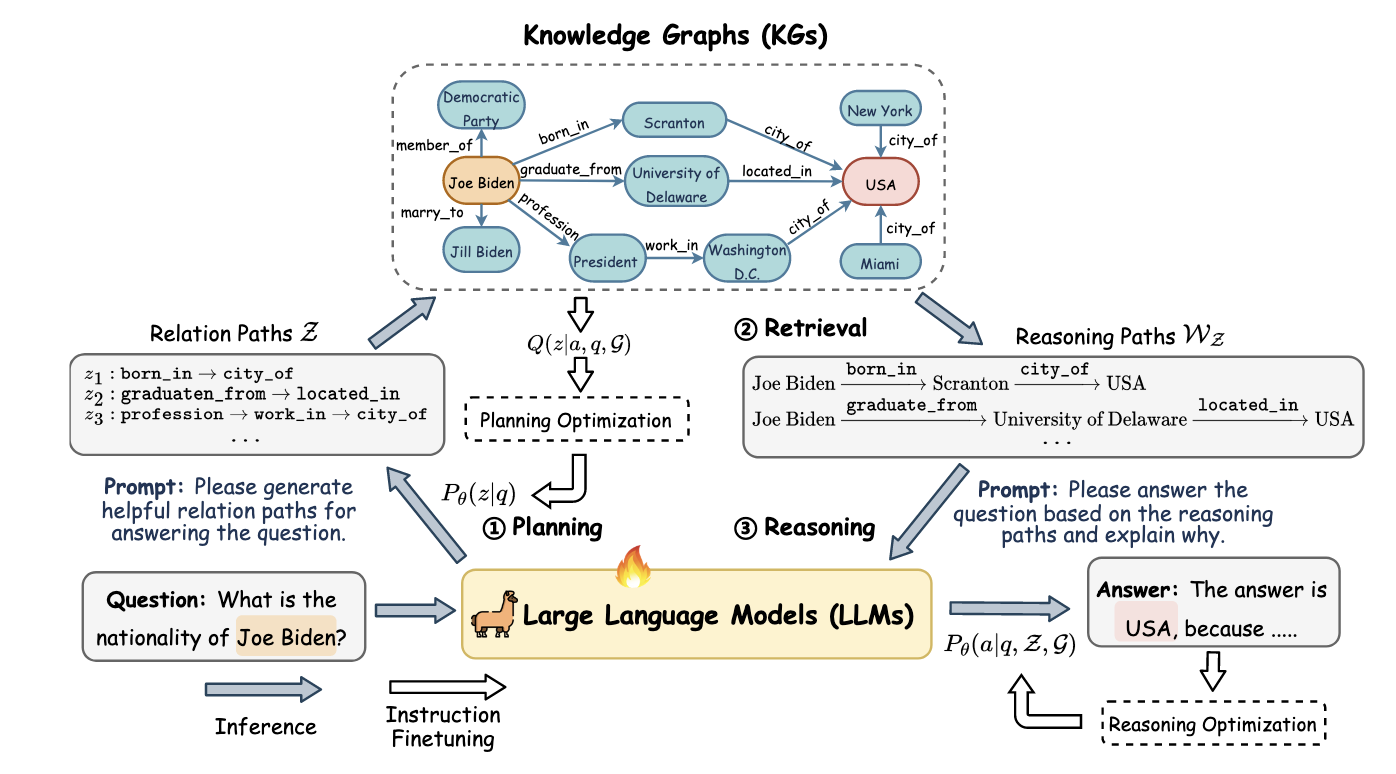
- (Reasoning-on-Graph) RoG 的思想其实非常简单:
-
给定 query $q$, 一般的 LLM 进行回答的过程就是:
$$ a \sim \mathbb{P}(a|q; \Theta), $$其中 $\Theta$ 是 LLM 的参数;
-
一般来说, 知识图谱可以提供一些由 $q \rightarrow a$ 的推理路径:
$$ e_q \overset{r_1}{\rightarrow} e_1 \overset{r_2}{\rightarrow} e_2 \cdots \overset{r_l}{\rightarrow} e_a. $$不妨记推理路径为 $z = (r_1, r_2, \ldots, r_l)$, 则结合知识图谱的推理过程为:
$$ a \sim \mathbb{P}(a|q, \mathcal{G}; \Theta) = \sum_{z} \mathbb{P}(a|q, z, \mathcal{G}; \Theta) \mathbb{P}(z|\mathcal{G}; \Theta). $$ -
即, $\mathbb{P}(z|\mathcal{G}; \Theta)$ 决定了推理路径, 而 $\mathbb{P}(a|q, z, \mathcal{G}; \Theta)$ 则是在给定推理路径的条件下生成答案.
-
作者希望 RoG 能够由 LLM 决定 $z$, 为了让 LLM 有这个能力, 会从原本的知识图谱中采样真实有效的推理路径, 并以此为目标训练 LLM, 此为 planning 优化. 此外, 根据推理路径优化回答生成, 此为 retrieval-reasoning 优化:
$$ \mathcal{L} = \log \underbrace{ \mathbb{P}(a|q, z^*, \mathcal{G}; \Theta) }_{\text{retrieval-reasoning}} + \underbrace{ \frac{1}{|\mathcal{Z}^*|} \sum_{z \in \mathcal{Z}^*} \log \mathbb{P}(z|q; \Theta) }_{\text{planning}}. $$
-
注: 其实, RoG 本质上就是认为构造了一些轨迹, 用 next-token prediction 训练而已.