SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
预备知识
核心思想
SoftVQ-VAE 的初衷是探索 Image Tokens 的压缩极限: 即最少用多少 Tokens 能够恢复出原本的 Image. 以往通常 128/256 便是极限, 再进一步压缩就会产生明显的退化.
本文虽然用到的向量量化, 但是并不像 VQ-VAE 那样要将 Image 编码为离散的表示的限制.
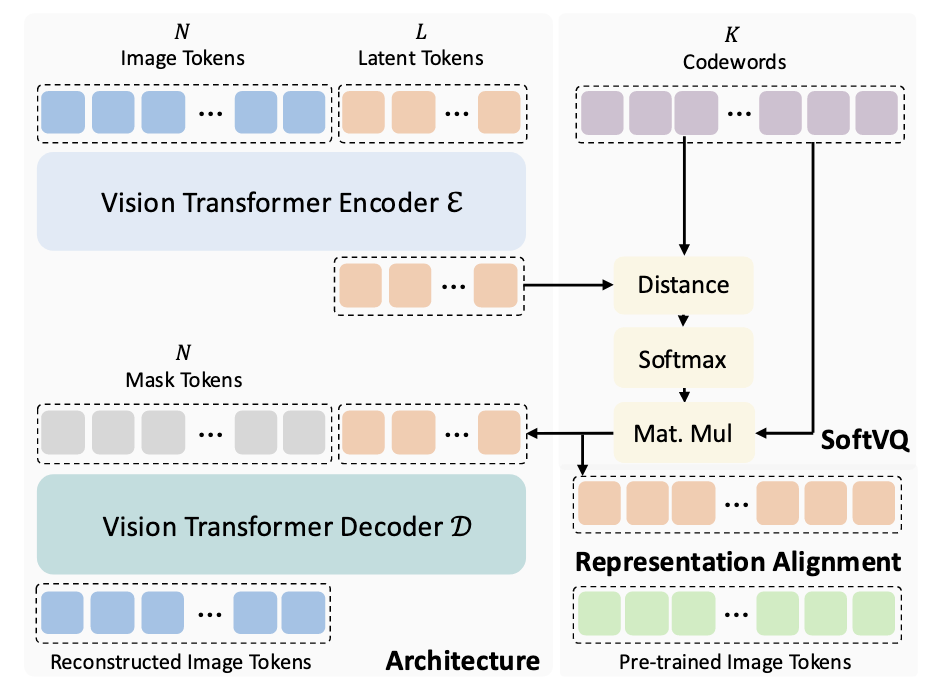
流程其实很简单:
(Encoding) Image Tokens + (Learnable) Latent Tokens 通过 Encoder, Latent Tokens 部分会逐步’吸收’ Image Tokens 的中的信息, 转换得到压缩后的表示 $\mathbf{\hat{z}} \in \mathbb{R}^{L \times D}$, 这里 $L$ 表示 Latent Tokens 的数目 (即压缩后的 Tokens 数量), $D$ 为 Token 表示的维度.
(Quantization) 和 VQ-VAE 不同, SoftVQ-VAE 不要求每个 Token 表示从 Codebook $\mathcal{C}$ 匹配一个, 而是计算 softmax 并加权求和:
$$ q_{\phi}(\mathbf{z}|\mathbf{x}) = \text{Softmax}\left( - \frac{\|\mathbf{\hat{z}} - \mathcal{C}\|_2}{\tau} \right), \\ \mathbf{z} = q_{\phi} (\mathbf{z}| \mathbf{x}) \mathcal{C}, $$此外, 这部分有额外的 KL 散度损失替代 commitment loss.
(Decoding) 有了 $\mathbf{z}$ 后, 再配合 Mask Tokens 通过 Decoder 恢复 Image.
Representation Alignment: 由于 SoftVQ-VAE 并没有 ‘argmin’ 这类截断梯度的操作, 所以我们可以设计其他任务来帮助 Codebook 的学习. 比如, 我们可以要求 $\mathbf{z}$ 和一些预训练模型得到的 Tokens 进行对齐, 从而加速收敛.
个人感觉 SoftVQ 这个思想并没有什么高明的地方, 实际上就可以看成是 Gumbel-softmax 替代了 STE, 不过 Latent Tokens 的设计倒是让人眼前一亮.