SpaceByte: Towards Deleting Tokenization from Large Language Modeling
预备知识
- 请先回顾一下 MegaByte.
核心思想
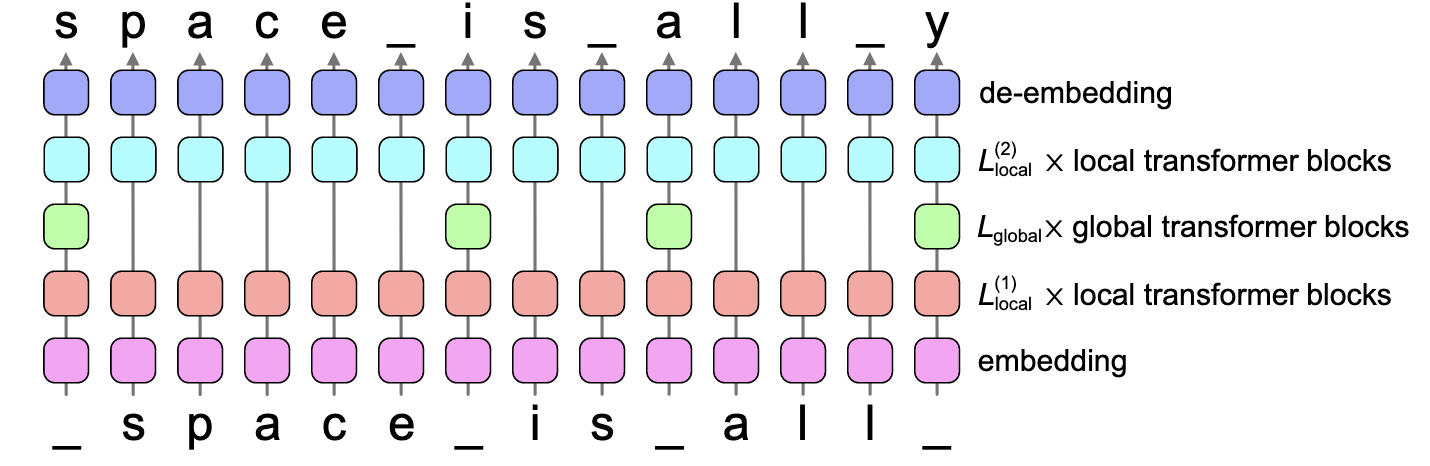
- 虽然 MegaByte 已经在移除 subword tokenizer 的方向上迈出了一大步, 但是其实际效果相较于一般的 subword tokenizer 模型依然相去甚远. 因此, 本文在 MegaByte 的基础上进行了一些适当的改进.

- SpaceByte: 除开模型设计上略有不同, SpaceByte 和 MegaByte 的最大区别是引入了 spacelike byte 的概念来作为词和词的边界:
MegaByte 采用固定滑动方式将符号序列切分成大小为 $P$ 的 patches.
SpaceByte 以 spacelike byte (e.g., " “, “,”, “.”) 来作为 patch 和 patch 之间的边界. 如上图所示, 第一个 patch 为 ’the ‘, 第二个patch为 “enemy!”, 第三个 patch 为 “$"\bullet \bullet$ " …
一个 patch 的基本构成就是:
$$ [\underbrace{\times \times \times}_{\ge 0 \text{ spacelike bytes }}\underbrace{wwwww}_{\ge 1} \underbrace{\times}_{=1}]. $$
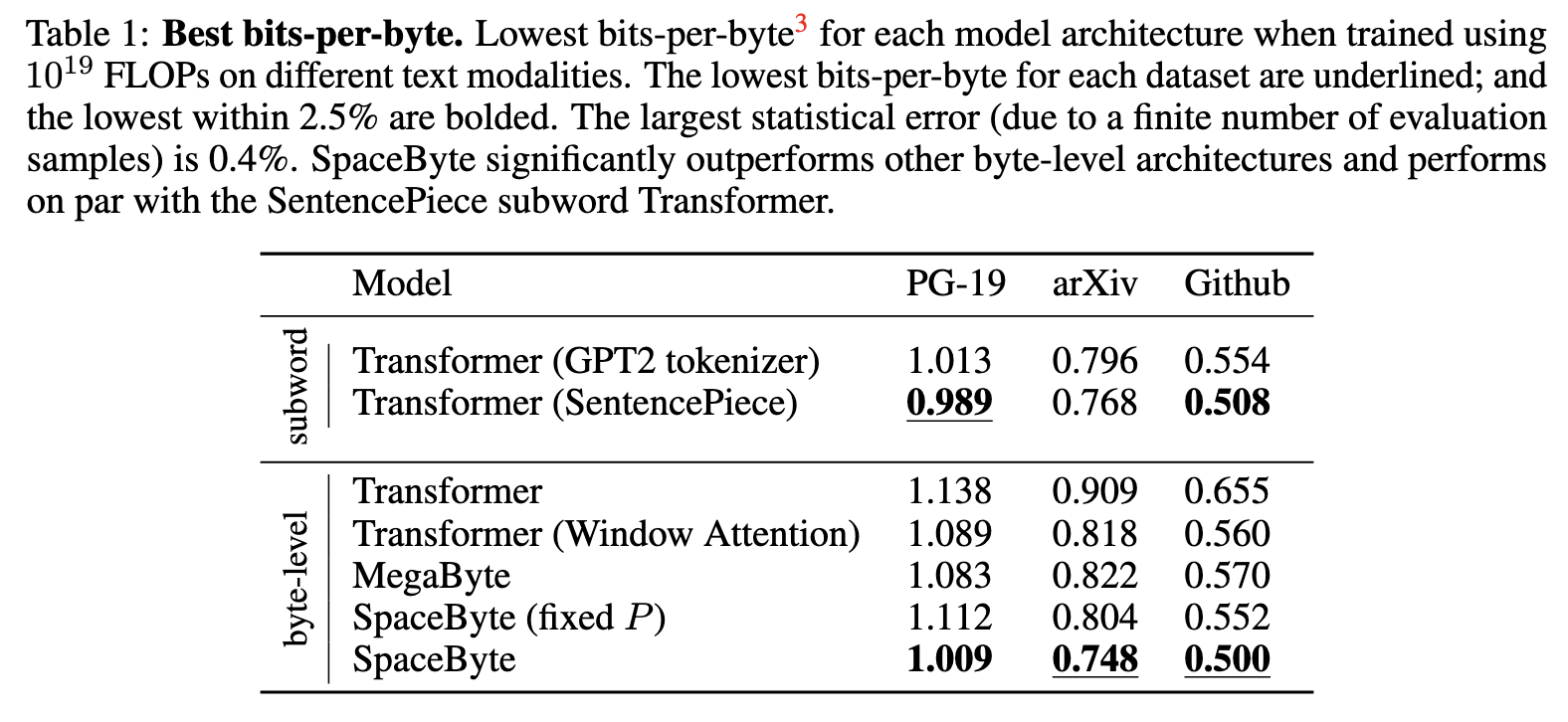
- 在相同的计算量下, SpaceByte 能够取得和 Subword Tokenizer 相媲美的结果.