Let’s Verify Step by Step
预备知识
- 对 Reward Model 有所认知.
核心思想
Reward Model 有两个重要用途:
- (Training) 用于价值对齐;
- (Inference) 用于打分, 以从多个回答中选择最合适的.
Reward Model 的训练同样有两个主要途径:
- Outcome-supervised Reward Model (ORM): 以输出结果作为监督信号;
- Process-supervised Reward Model (PRM): 以阶段反馈作为监督信号.
以做数学题为例, 最简单的训练方式就是以最终的答案作为标准来训练 reward model, 此时就是 ORM. 但是数学题有些时候过程不对但是答案还是可能是对的, 倘若我们要求对于每一个 step 都打分, 此时就是 PRM. 显然:
- ORM 相较于 PRM 会存在 false positives 的问题;
- PRM 相较于 ORM 则需要更多的监督信号, process supervision 往往需要额外的人类打标.

PRM 的 Active Learning
给定一个 base model (e.g., GPT-4), 在此基础上进行微调.
最为简单的方式可能是直接通过 base model 生成 solutions 让人类进行打标, 但是这种方式是较为低效的. 作者认为, 我们需要定位那些模型当前 “convincing wrong-answer solutions”, 即模型很自信却实质上错误的解答过程.
有了一批打标数据后, 对模型进行一个微调, 如上图所示, 这是一个三分类的任务: positive, neutral, negative.
然后基于这个最新的模型继续打标.
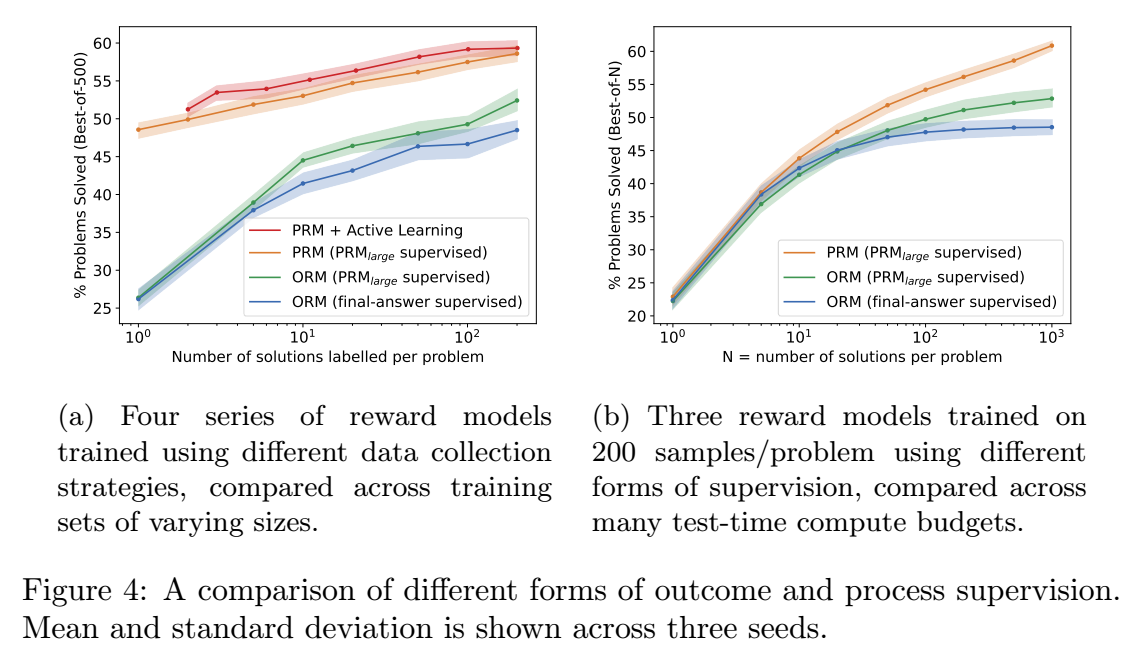
- PRM 相较于 ORM 具有明显的优势. 同时, 左图验证了 Active Learning 的重要性.
PRM 的使用

- 本文主要是将 PRM 用于推理阶段, 即判断 N 个作答中哪个是最为可靠的. 最终的打分为每个 step 的正确概率的乘积 (?这种计算方式不会倾向于较短的作答吗).
注: 作者在附录里还提到了另一种打分方式: 所有 step 的正确概率的最小值.
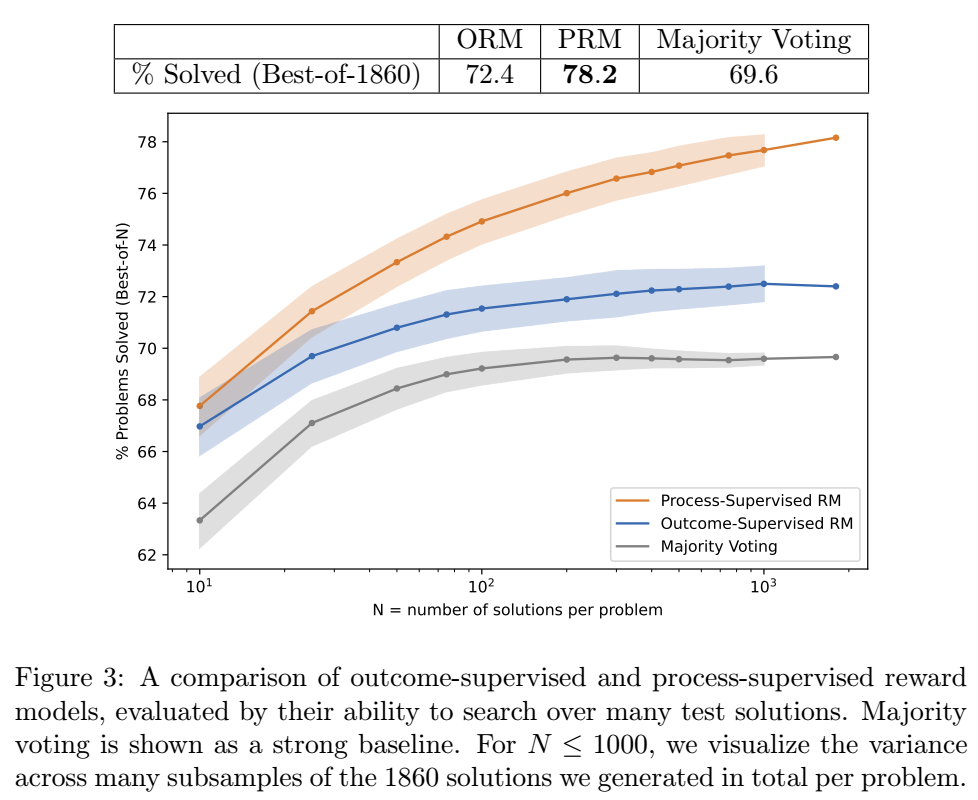
- 如上图所示, PRM 相较于 ORM 有明显的优势, 而且这个优势随着 N 的增加越来越大 (这个就是最近还挺火的 Test-time scaling).
注: 需要 few-shot prompt 来保证 solution 是 step-by-step 的.