SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?
预备知识
(AI Software Engineering) AI Software Engineering 已经从简单的"提需求 -> 代码生成"过渡到了"独自攻克 Repository-level 问题".
(Issue & Pull Request) 提问题并根据问题提交解决方案是 GitHub 最为广泛的场景之一. 其要求贡献者从庞大的仓库中 (庞大体现在文件架构以及代码量) 准确定位针对某个 issue 需要修改的代码块 (这要求模型具有相当的理解和检索能力) 并做出适当修改 (这要求模型具有相当的代码生成能力).
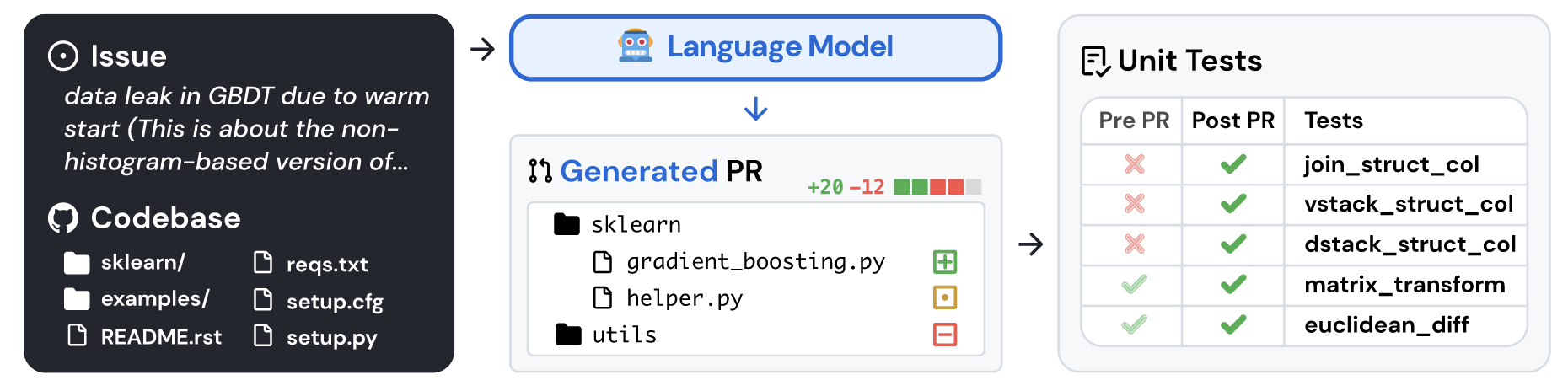
核心思想
SWE-Bench 的构建

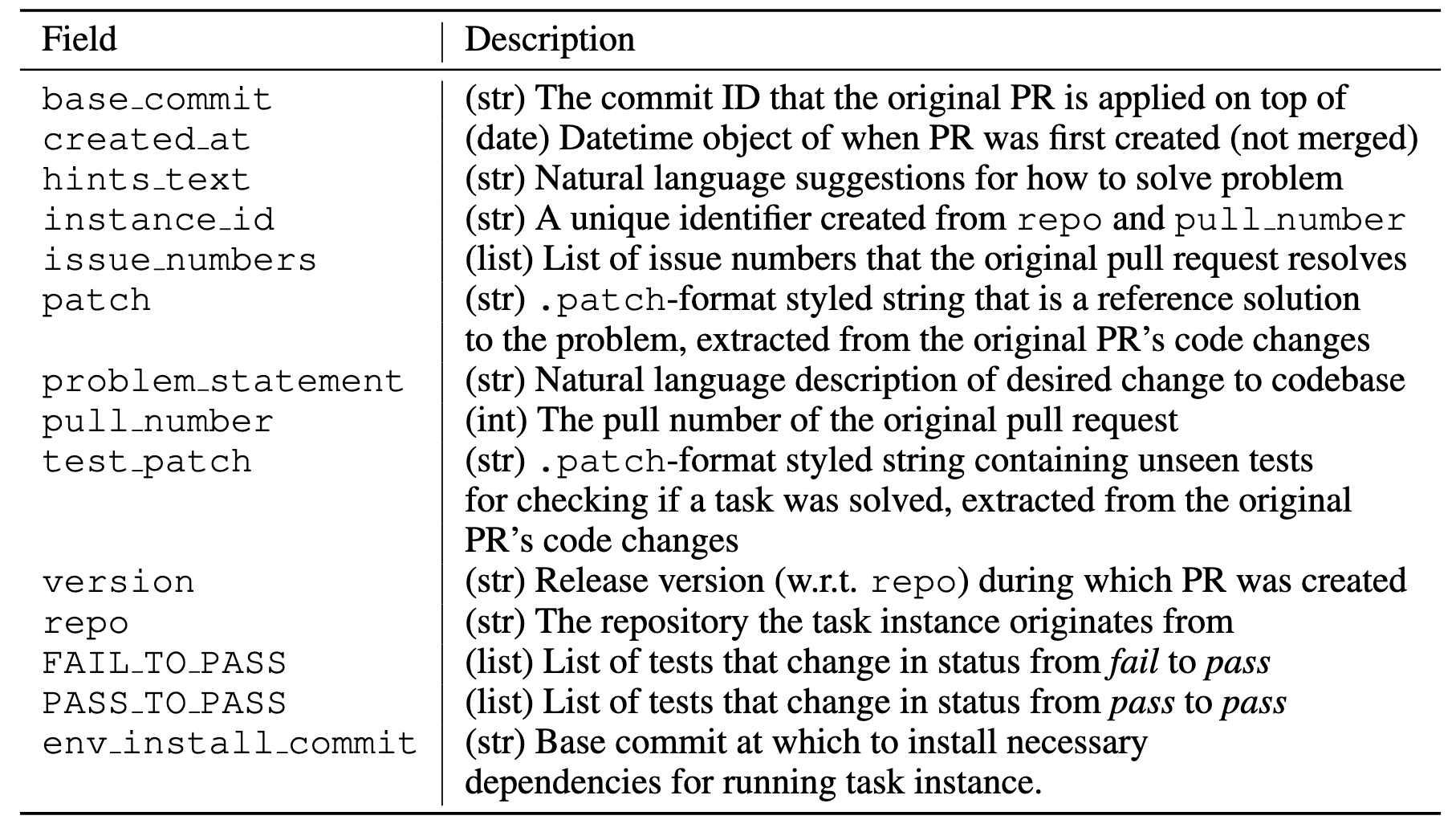
- (Repo selection and data scraping) 从 12 个流行的开源 Python 库中爬取 90,000 PRs. 数据结构如下:
- repo, base_commit, version: 通过仓库名 ‘repo’ 以及 commit ID ‘base_commit’ 可以定位具体的代码, 通过 ‘version’ 可以进一步确认所需的安装环境 (SWE-Bench 假设只有 version 发生变更安装环境才有可能发生变更);
- problem_statement: 和 PR 相关的 issues 的描述的拼接;
- patch: PR 中的解决方案, 即 Gold Patch, 即 Ground Truth;
- test_patch 和该 PR 相关的测试用例, 通过应用该 test_patch 可以测试相关 solution 能够实现 issues/PR 所关心的功能.
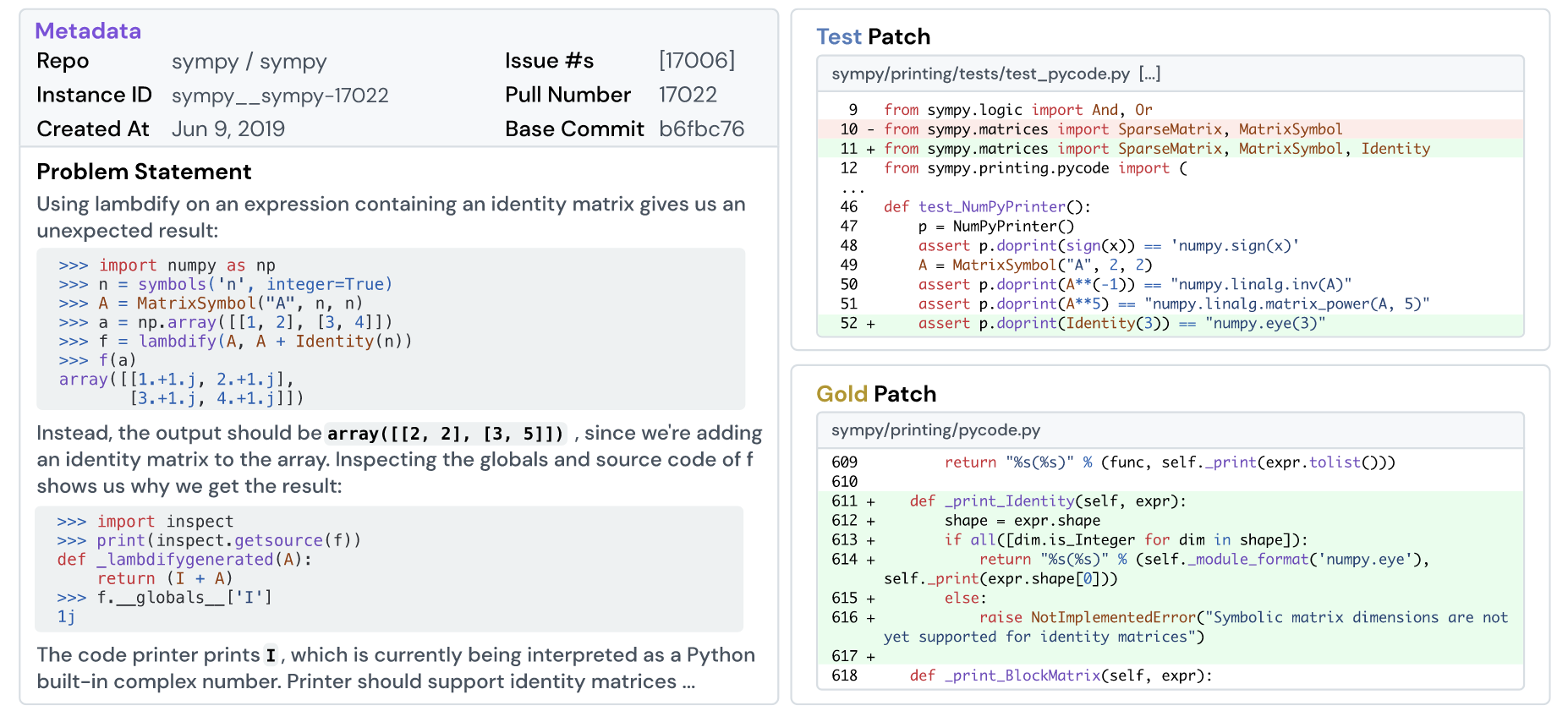
(Attribute-based filtering) 仅保留 ‘issue_numbers’ 和 ’test_patch’ 非空的 PRs. 前者保证该实例存在明确的问题需求作为 context 提供给模型, 后者提供了明确的测试案例以方便后续对不同的 solution 进行实际的评估.
(Execution-based filtering) 可用的实例应当通过如下的验证步骤:
- 根据 ‘version’ 所对应的安装环境创建 conda 环境;
- 根据 ‘repo’ 和 ‘base_commit’ 定位到具体的代码;
- 应用 ’test_patch’ 至代码中;
- 运行测试脚本, 生成日志 $log_{pre}$;
- 应用 ‘patch’ 至代码中;
- 运行测试脚本, 生成日志 $log_{post}$;
- 如果 ‘patch’ 是 Gold Patch, 则 $log_{pre}$ 中部分 fail 的测试用例 (尤其是 ’test_patch’ 所对应的用例) 在 $log_{post}$ 中为 pass. 即 PR 实现了 fail to pass 的过程.
经过上述的过滤, 90,000 PRs 最后只剩下约 2,294 个任务实例, 构成了 SWE-Bench.

SWE-Bench Lite
- 由于 SWE-Bench 中每个实例的评估都需要配置环境, 跑测试用例, 因此相当耗时. 为了快速评估, 作者团队给出了一个轻量的版本: SWE-Bench Lite, 包含 300 个测试用例:
- 移除设计图片和外部链接的任务;
- 移除问题描述少于 40 字符的任务;
- 移除需要同时编辑多个文件的任务;
- 移除需要修改超过三个代码块 (hunk, 在 patch 中指连续的代码更改)的任务;
- 移除需要创建和删除文件的任务;
- 移除那些包含错误信息检查测试的任务.
基础实验
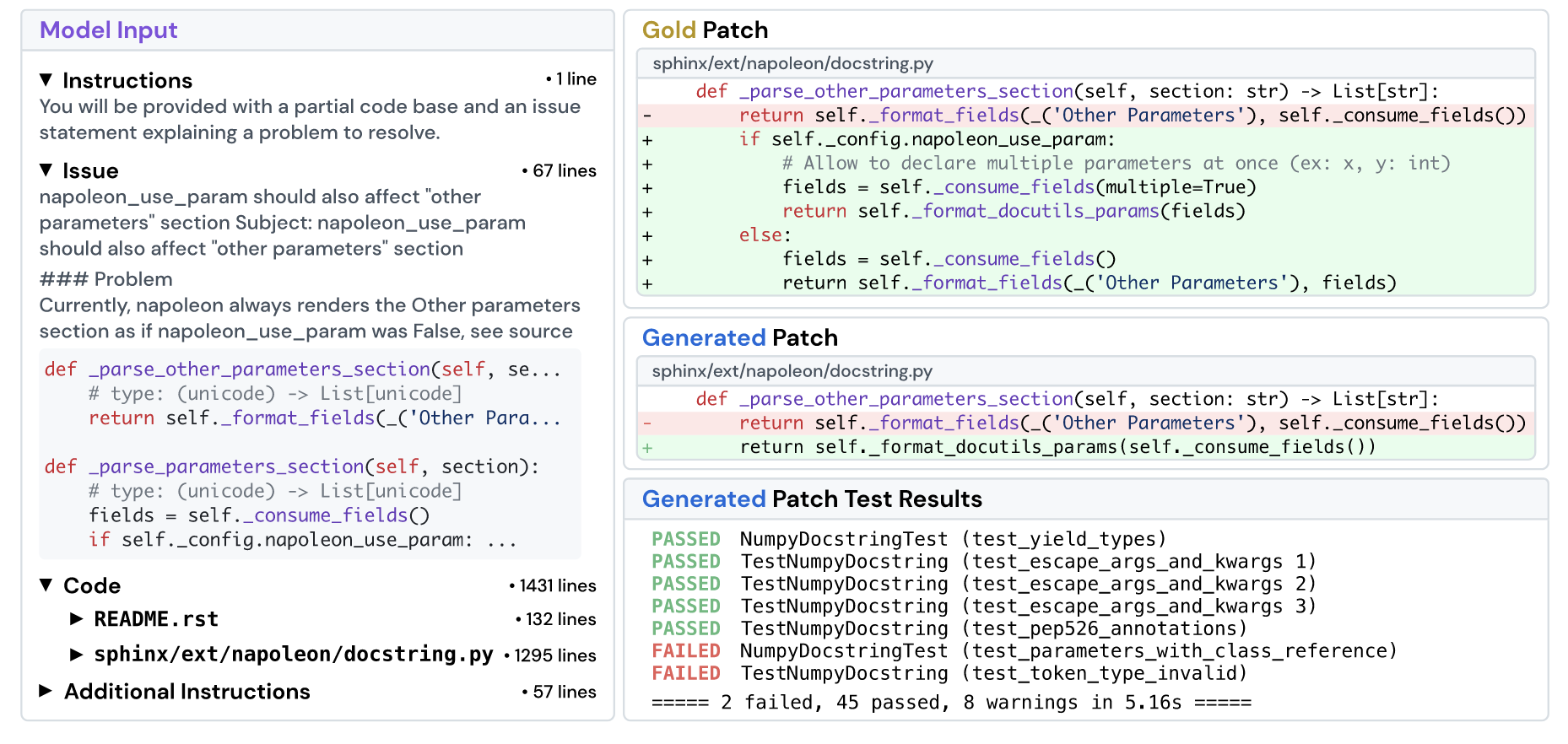
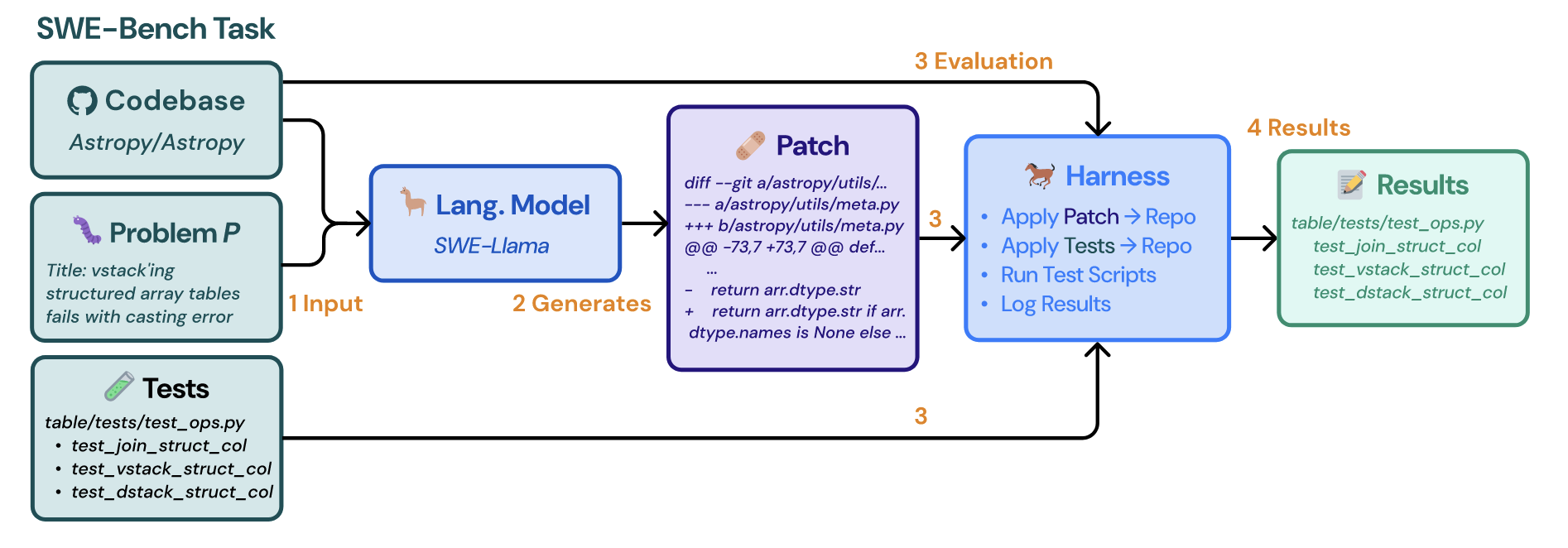
- (步骤):
- 类似上图左侧将 issues 以及对应代码块形成输入;
- 要求模型根据输入生成 patch, 如右侧所示;
- 将生成的 patch 按照类似上述的验证过程进行验证, 成功通过所有测试案例则得 1 分, 任何应用不成功或者案例不通过的得 0 分. 最后将通过率作为评测指标.
代码块检索方式
- 由于完全的仓库的代码量过于庞大, 需要根据问题描述进行初步检索. 本文探究两种方式:
- BM25 retrieval: BM25 根据词频计算 query 和文档的相关性;
- Oracle retrieval: Oracle retrieval 直接根据 Gold Patch 定位所需修改的代码块, 在此背景下考验的是模型的代码生成能力.
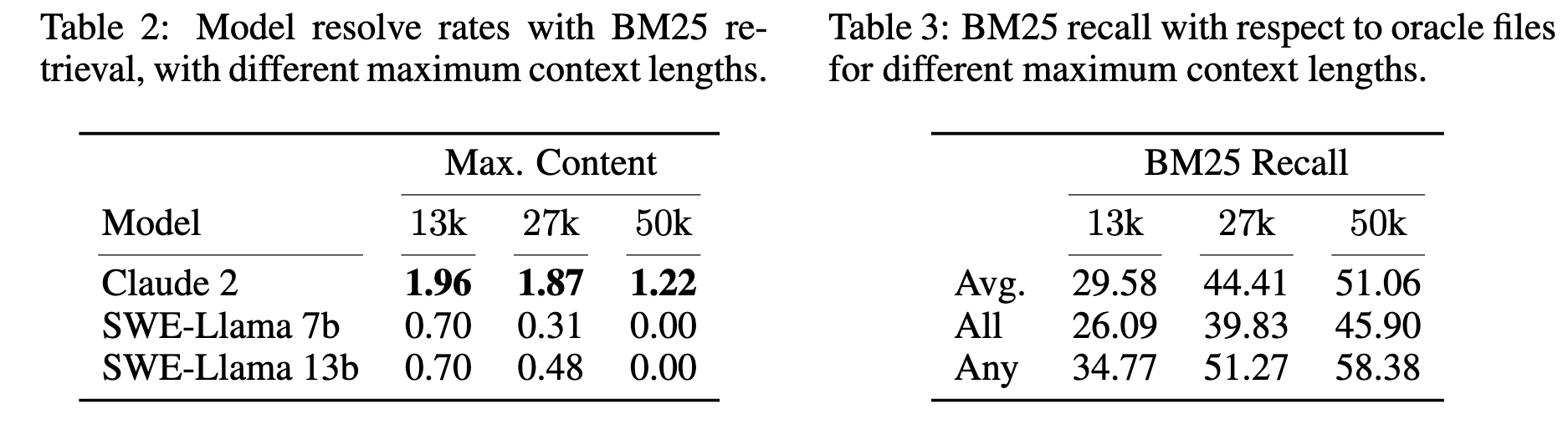
(定位准确性更为重要) 当放宽上下文长度限制是, 可以通过 BM25 检索出更多可能的代码块, 然而如上表所示, 虽然召回率随着上下文长度不断增加, 实际的通过率反而是在下降的, 这很大可能是信息过于冗杂.
Claude 2 在 Oracle retrieval 下能够解决 5.9%, 这说明了准确检索的重要性.
生成特性
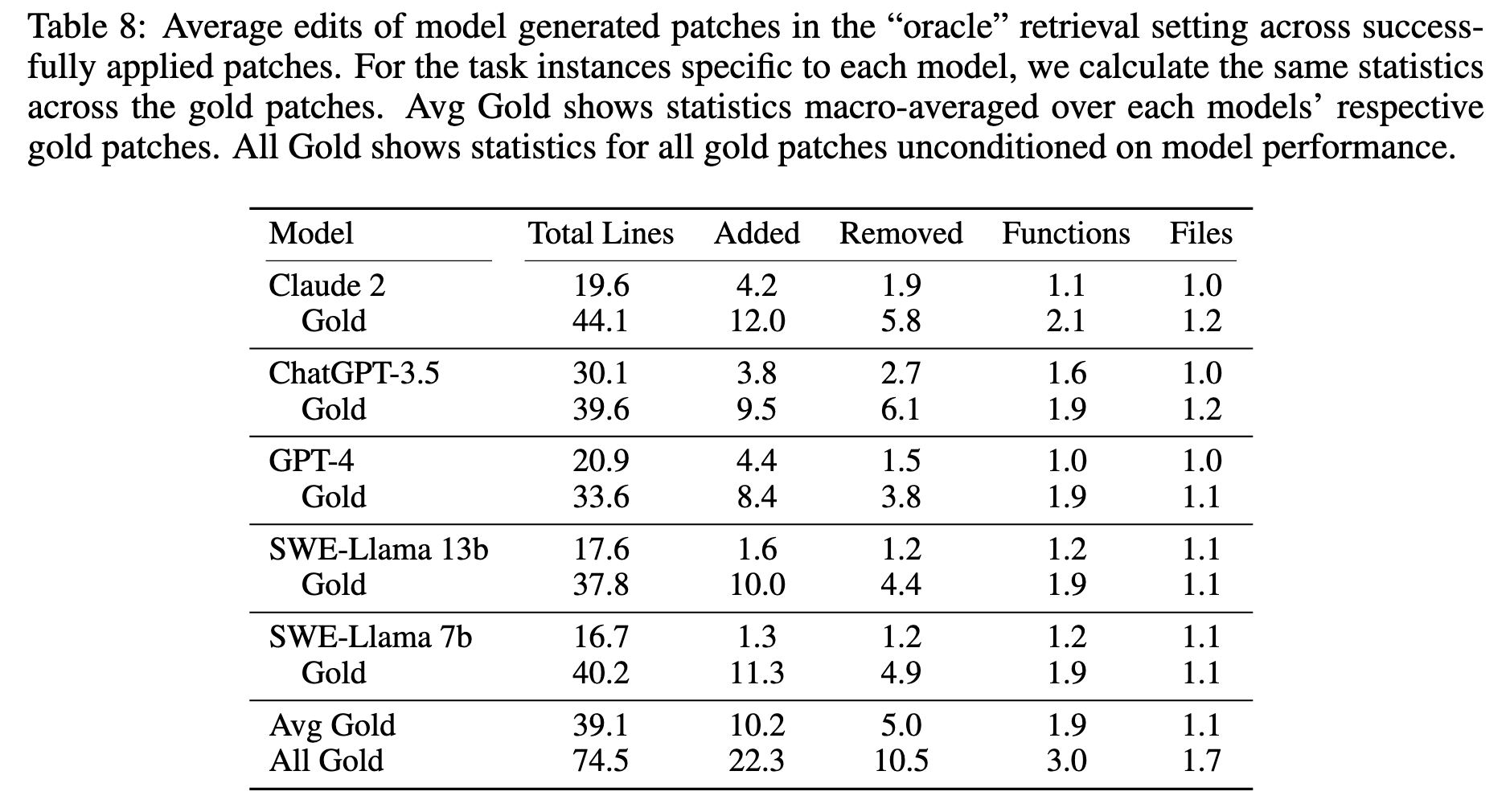
- 目前的 LLM 在生成 patch 上倾向于采取 ‘简化’ 的方式生成, 如上表所示, 生成的行数显著小于实际的. 一方面, 作者认为这可能和 LLM 的微调方式有关; 另一方面, 实际的 PR 往往不仅解决某个 issue, 还会考虑一些 future issues 从而导致代码量相对较多.