SWE-smith: Scaling Data for Software Engineering Agents
预备知识
(AI Software Engineering) AI Software Engineering 已经从简单的"提需求 -> 代码生成"过渡到了"独自攻克 Repository-level 问题".
(Issue & Pull Request) 提问题并根据问题提交解决方案是 GitHub 最为广泛的场景之一. 其要求贡献者从庞大的仓库中 (庞大体现在文件架构以及代码量) 准确定位针对某个 issue 需要修改的代码块 (这要求模型具有相当的理解和检索能力) 并做出适当修改 (这要求模型具有相当的代码生成能力).
(SWE-Bench) SWE-Bench 提供了上千的 repository-level 的实例任务, 然而受限于 “可执行可验证” 的需求和限制, 提供上千的 repository-level 的实例任务已经难能可贵. 然而, 大模型时代数据量往往能够直接决定模型训练好坏, 因此如何低成本地自动化地生成 repository-level 的实例任务是需要重点攻克的问题.
核心思想
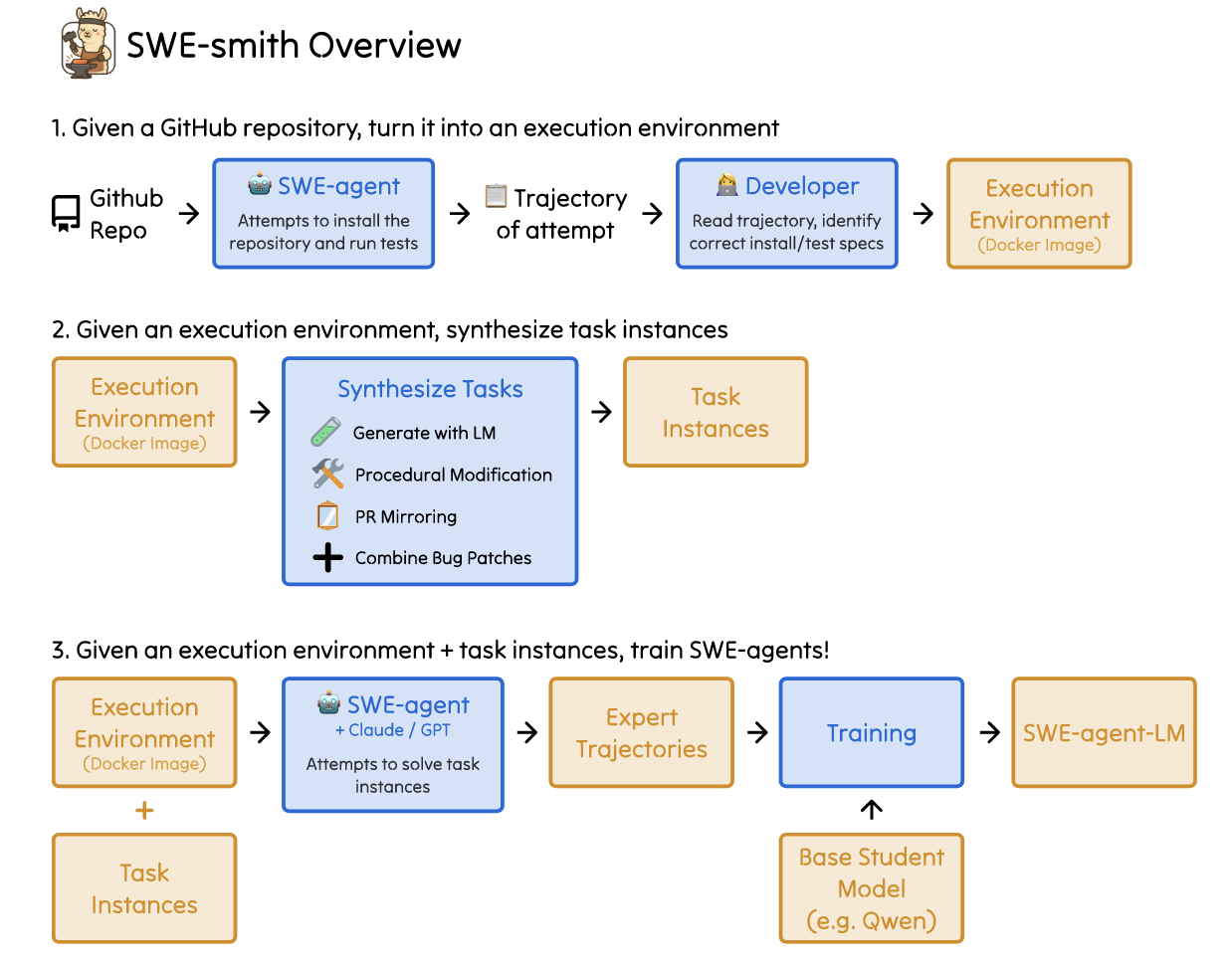
- (SWE-Smith) SWE-Smith 具有三种功能:
- 自动搭建可执行环境: 给定一个 repository, 通过 SWE-Agent 自动安装所需依赖, 形成可验证的交互环境;
- 自动合成类似 SWE-Bench 中的任务实例: 在原 repository 的基础上, 自动生成 bugs 以及相应的 problem_statement;
- 训练 SWE-Agents: 仿照 SWE-Gym 的方式在合成数据上训练 SWE-Agents.
数据合成
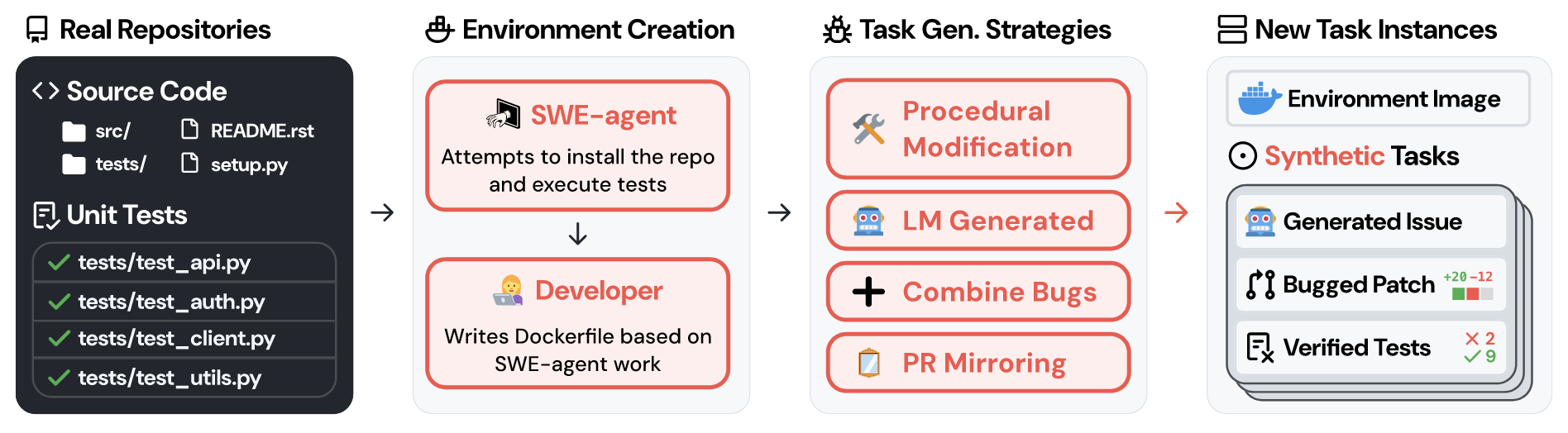
(SWE-Bench) SWE-Bench 为了保证 repository-level 实例具有 1. 相关联的 issue; 2. 对应的 test 实例, 从原本 90,000 PRs 过滤出 2,294 个 PRs. SWE-Smith 的核心思想在于: 是否可以通过某些方式在原 repository 的基础上构造 bugs, 且保证这些 bugs 会导致某些 test 实例不通过, 并通过 LM 生成 problem_statement, 则可以自动生成满足 SWE-Bench 要求的 repository-level 实例任务. 而且, 相较于 SWE-Bench 需要为每个测试实例搭建专有的运行环境 (因为一个 repository 的生命周期中的依赖会发生改变), SWE-Smith 仅需为每个 repository 搭建一个环境并通过修改其中不同的代码块以产生多个实例.
(Bug 来源) SWE-Smith 考虑了四种 Bug 构造方式.
LM Generation
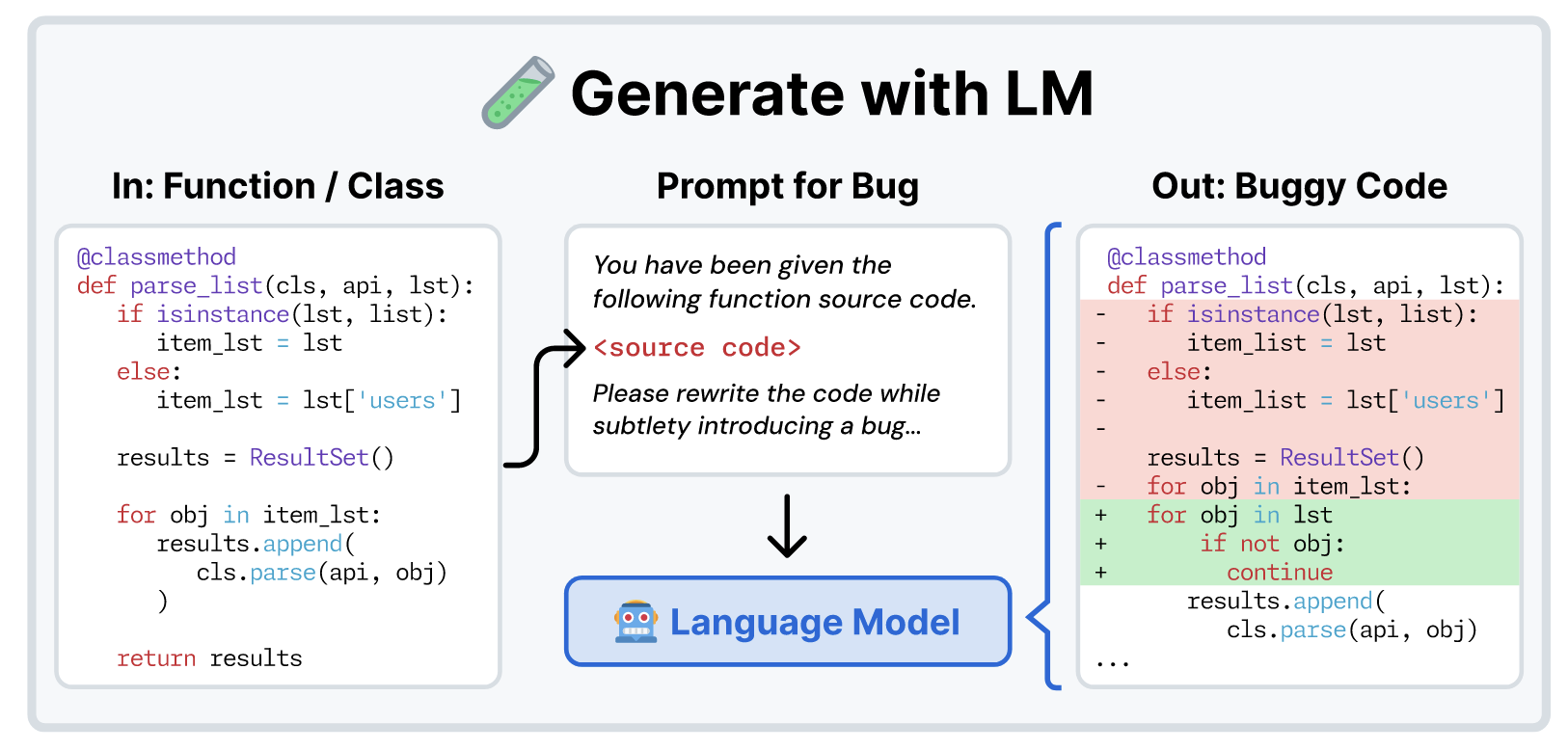
LM Generation 旨在通过适当的 prompt 要求 LM 恶意改写 repository 中部分代码, 从而产生一些不易察觉的 bugs.
(Modify existing functions/classes) 最直接的方式就是在 repository 的代码基础上要求 LM 根据如下 prompt 直接加入恶意的 bug. 这些 bug 不能是直接造成编译错误或者存在语法检查问题的基础 bug. SWE-Smith 建议了很多改变控制流和运行逻辑的微小 bug.
You are a software developer doing chaos monkey testing. Your job is to rewrite a function such that it introduces a logical bug that will break existing unit test(s) in a codebase. To this end, some kinds of bugs you might introduce include:
(Per inference call, only 3 of the following tips are randomly selected and shown)
- Alter calculation order for incorrect results: Rearrange the sequence of operations in a calculation to subtly change the output (e.g., change (a + b) * c to a + (b * c)).
- Introduce subtle data transformation errors: Modify data processing logic, such as flipping a sign, truncating a value, or applying the wrong transformation function.
- Change variable assignments to alter computation state: Assign a wrong or outdated value to a variable that affects subsequent logic.
- Mishandle edge cases for specific inputs: Change handling logic to ignore or improperly handle boundary cases, like an empty array or a null input.
- Modify logic in conditionals or loops: Adjust conditions or loop boundaries (e.g., replace <= with <) to change the control flow.
- Introduce off-by-one errors in indices or loop boundaries: Shift an index or iteration boundary by one, such as starting a loop at 1 instead of 0.
- Adjust default values or constants to affect behavior: Change a hardcoded value or default parameter that alters how the function behaves under normal use.
- Reorder operations while maintaining syntax: Rearrange steps in a process so the function produces incorrect intermediate results without breaking the code.
- Swallow exceptions or return defaults silently: Introduce logic that catches an error but doesn’t log or handle it properly, leading to silent failures.
Tips about the bug-introducing task: (At inference time, tips are randomly shuffled)
- It should not cause compilation errors.
- It should not be a syntax error.
- It should be subtle and challenging to detect.
- It should not modify the function signature.
- It should not modify the documentation significantly.
- For longer functions, if there is an opportunity to introduce multiple bugs, please do!” Please DO NOT INCLUDE COMMENTS IN THE CODE indicating the bug location or the bug itself.
Your answer should be formatted as follows:
Explanation: <explanation>
Bugged Code:
‘‘‘
<bugged code>
‘‘‘
- (Rewrite existing functions) 另一种方式是要求 LM 重写相应的函数, 虽然没有明确要求产生 bug, 由于 LM 本身能力的局限, 有一定概率导致一些 bug, 而且往往这些 bug 是难以察觉的.
**System Prompt**
You are a software developer and you have been asked to implement a function.
You will be given the contents of an entire file, with one or more functions defined in it. Please implement the function(s) that are missing. Do NOT modify the function signature, including the function name, parameters, return types, or docstring if provided. Do NOT change any other code in the file. You should not use any external libraries.
**Task Instance Prompt**
Please implement the function func signature in the following code:
{file src code}
Remember, you should not modify the function signature, including the function name, parameters, return types, or docstring if provided. Do NOT change any other code in the file. Format your output as:
[explanation]
{func to write}
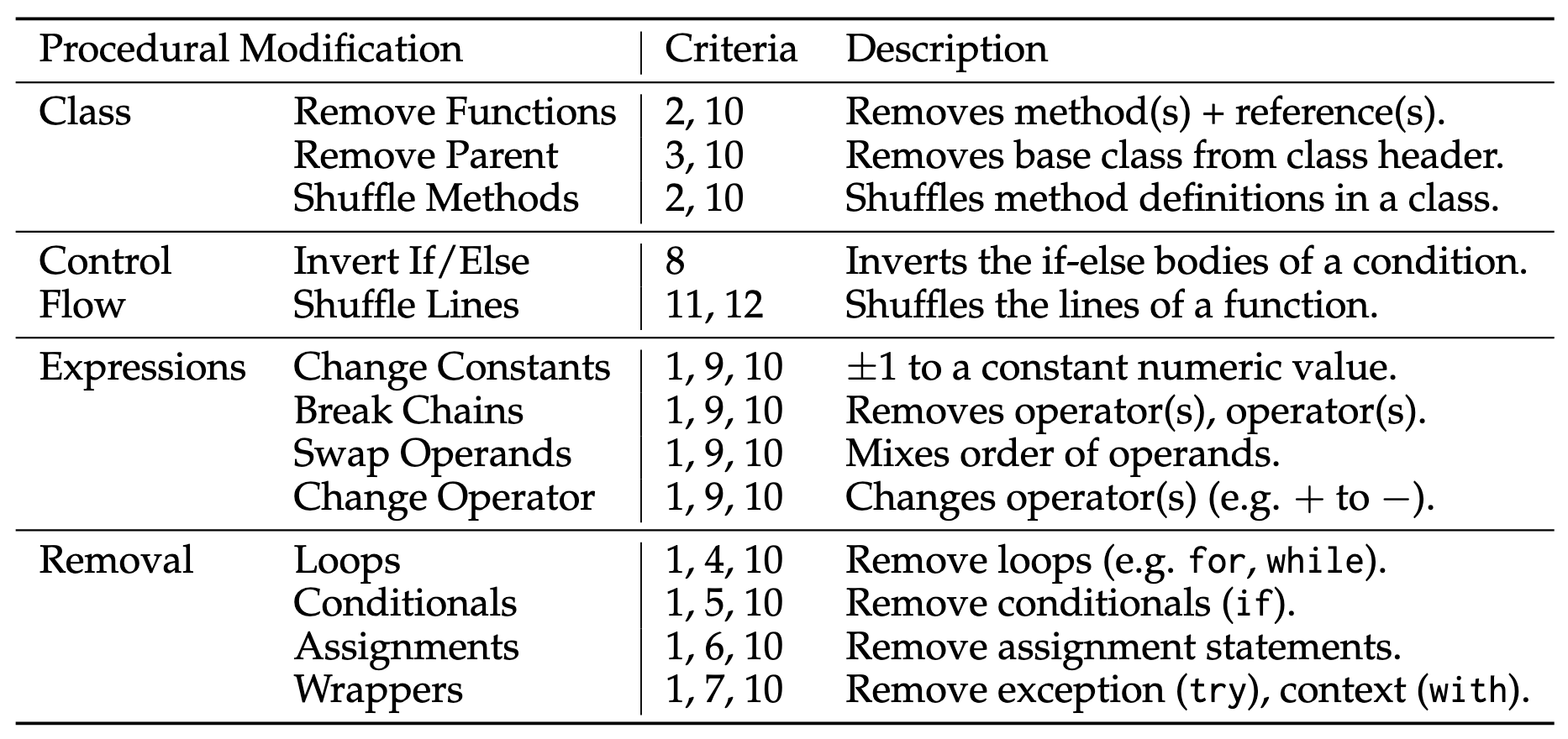
Procedural Modification
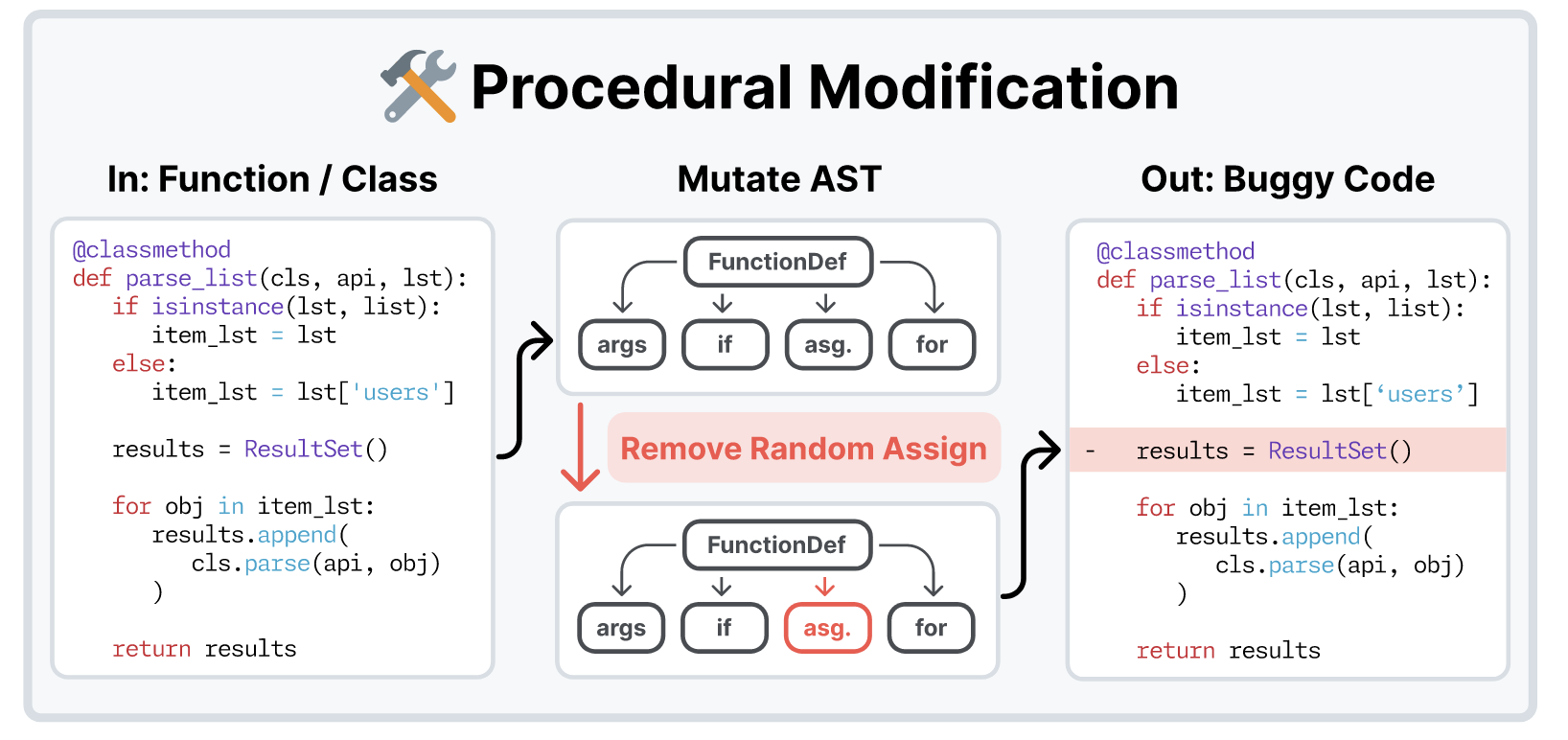
- 另一种不依赖 LM 的方式是首先构建 repository 的语法树, 然后改变其中部分节点.
Combine Bug Patches
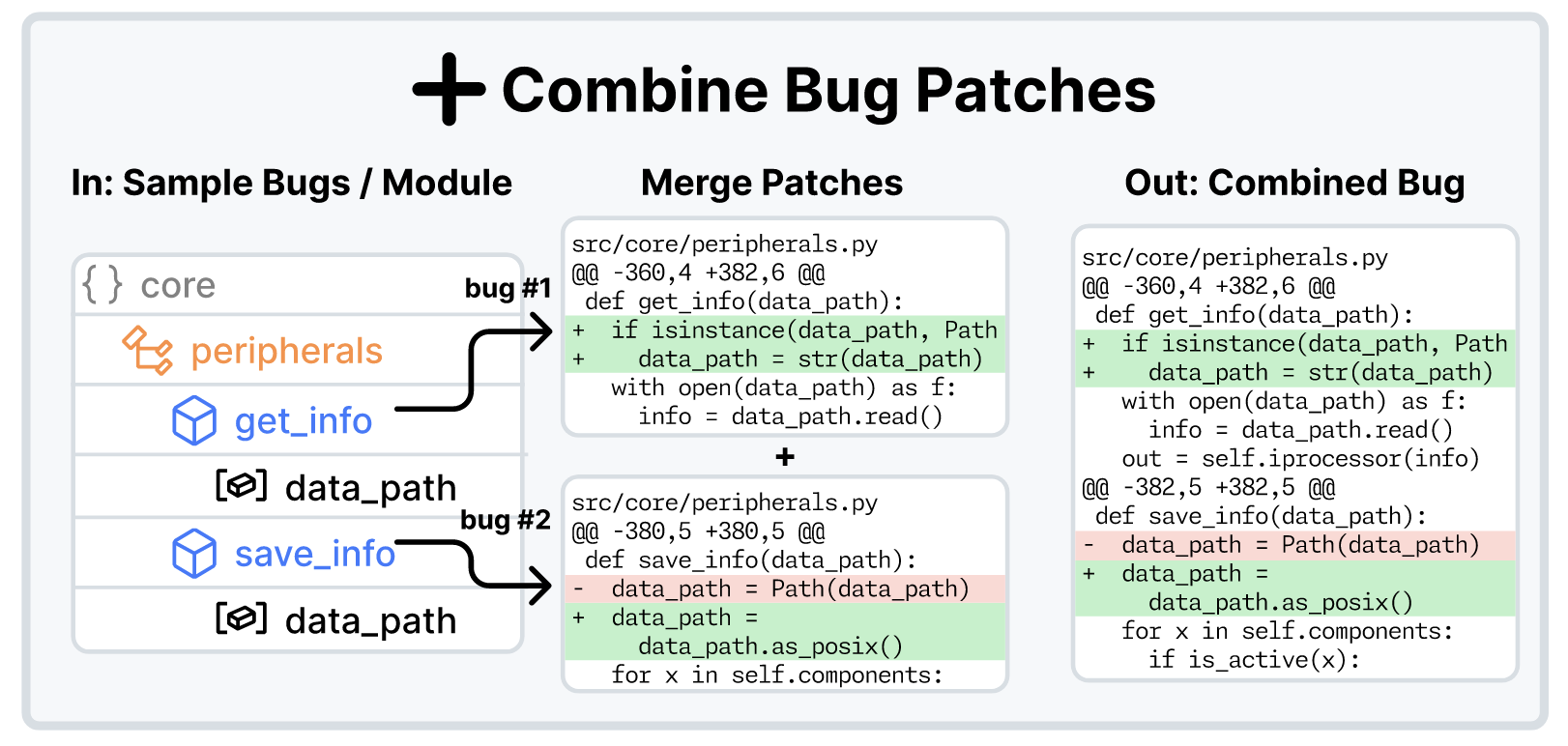
- 单一的 bug 生成方式可能过于简单, 因此可以通过将不同的 bug 进行融合, 得到更加复杂的问题实例.
Pull Request Mirroring
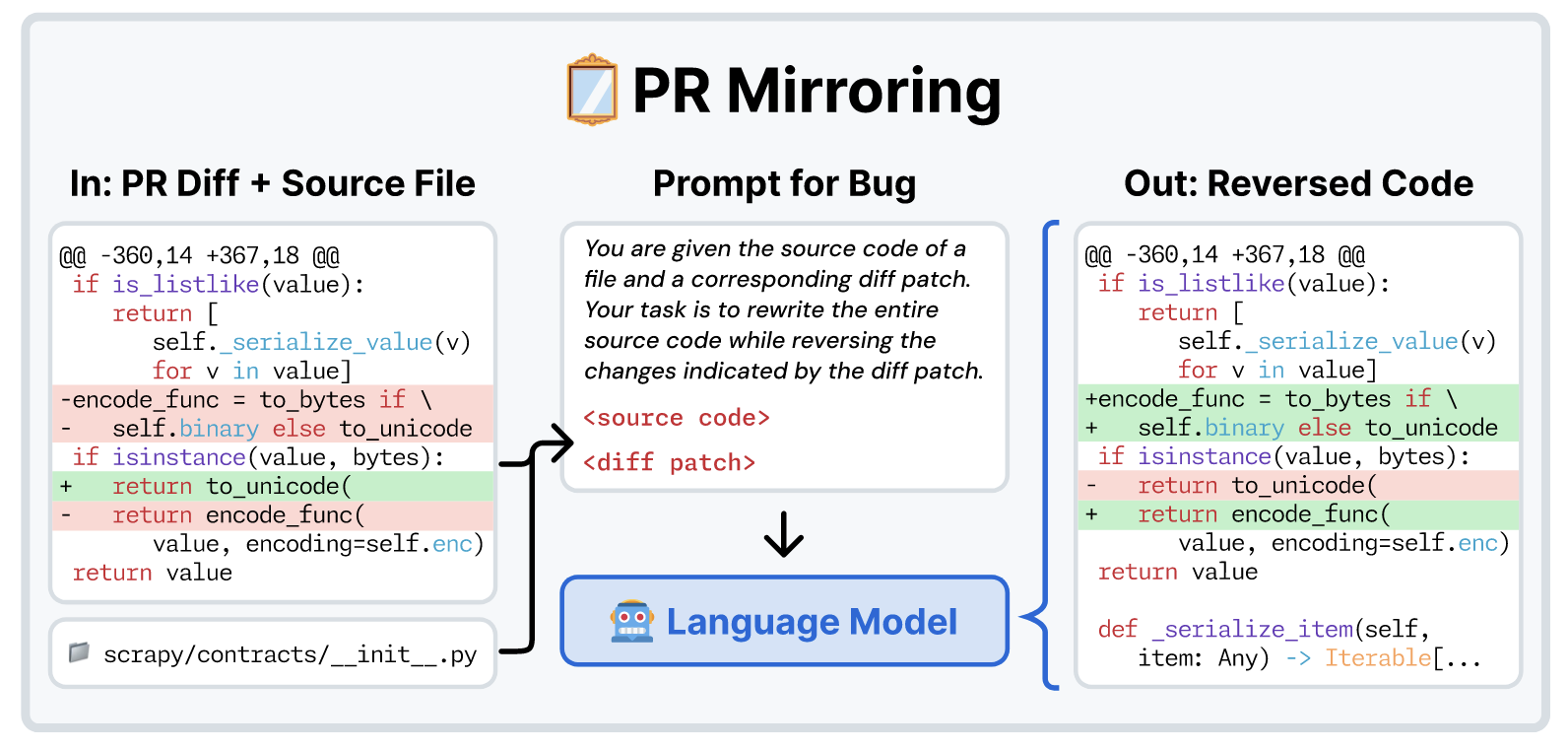
- 给定 PR 有时可以通过反转修改恢复出 “bug”, 这里 SWE-Smith 将反转的任务交给 LM 而不是一些自动化脚本主要是在 repository 的生命周期中 Patch 对应的行号已经发生了较大的更改.
Issue Generation
上述阶段提供了 Bug 和相应的可用于验证的测试用例, 还需要 problem_statement 完成最后的工作.
SWE-Smith 提供了三种方案:
- Fixed issue templates: 按照下列模板构造 issue.

Fail-to-Pass test code and execution logs: 随机选择一个未通过的 test, 并给出相应的执行日志;
Generated with LM (推荐): 提供给 LM 一个问题描述案例, 以及实际的 bug patch, 失败的 test, 某个失败 test 的源代码, 以及所有失败 test 的执行日志, 让 LM 生成合适的 issue.
You are a software engineer helping to create a realistic dataset of synthetic GitHub issues.
You will be given the following input:
1. Demonstration: A realistic GitHub issue to mimic (included in the <demonstration> tag).
2. Patch: A git diff output/PR changes that introduces a bug (included in the <patch> tag).
3. Test output: The output of running the tests after the patch is applied (included in the <test output> tag).
4. Test source code: Source code for one or more tests that failed (included in the <test source code> tag).
Output: A realistic GitHub issue for the patch.
Guidelines:
- Mimic the style and structure of the demonstration issues. If the demonstration issues are not well structured, your output should also be not well structured. If the demonstrations use improper or no markdown, your output should also use improper or no markdown. If the demonstrations are short/long, your output should also be short/long (if possible). If the demonstrations include human ”flavor text” or ”fluff”, your output should also include human ”flavor text” or ”fluff”. Do this even if it conflicts with your default behavior of trying to be extremely concise and helpful.
- DO NOT explain the fix/what caused the bug itself, focus on how to reproduce the issue it introduces
- Do not mention pytest or what exact test failed. Instead, generate a realistic issue.
- If possible, include information about how to reproduce the issue. An ideal reproduction script should raise an error or print an unexpected output together with the expected output. However, still include this information in a style very similar to the demonstration issues.
模型训练
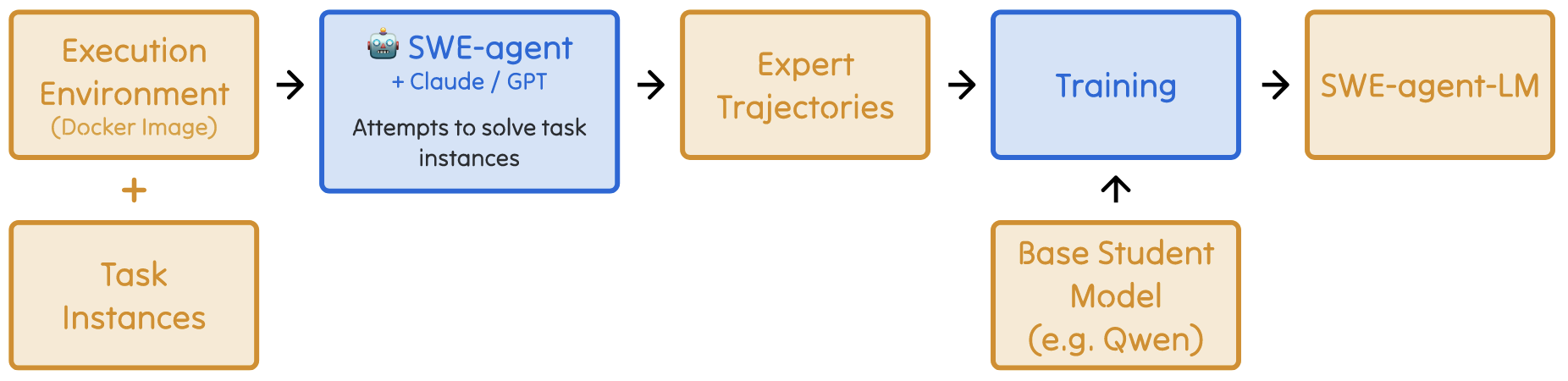
- SWE-Smith 提供了一种合理利用上述数据的方法:
- 利用 SWE-Agent 配合如 Claude 3.7 Sonnet, GPT 4o 等强模型在生成数据集上收集成功的轨迹;
- 在上述轨迹上微调 Qwen-2.5 等稍弱的模型.
实验
Data Scaling
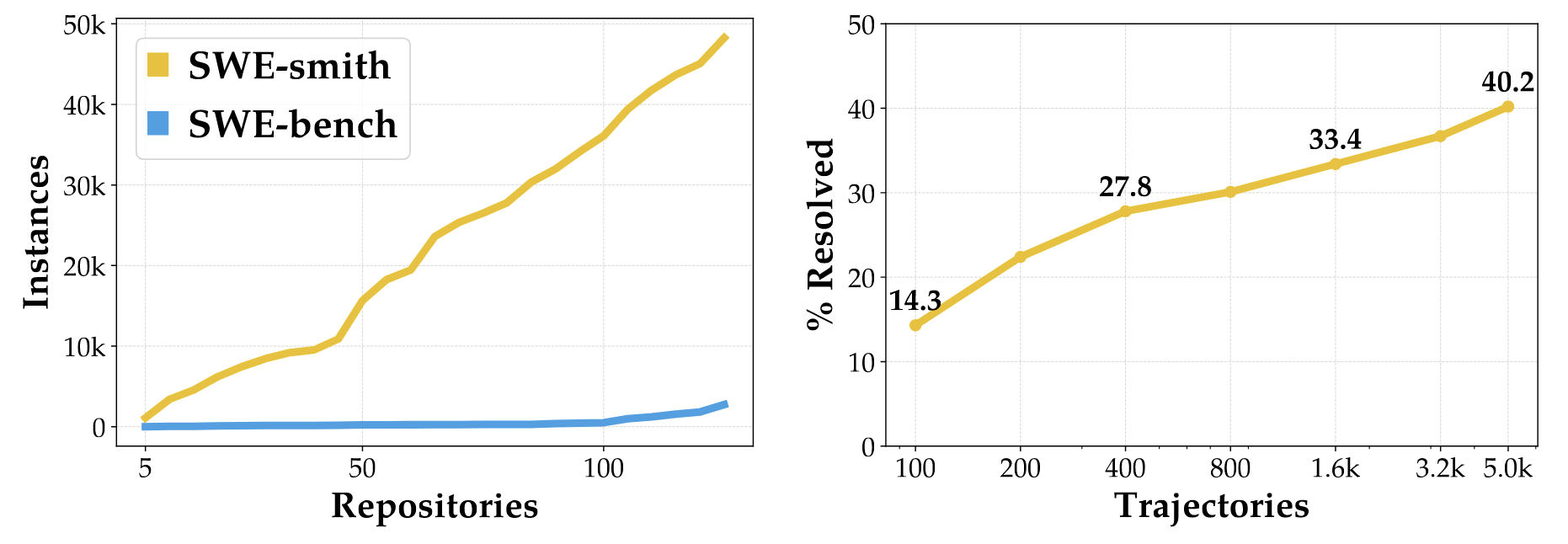
- 随着生成的数据量的增强, 解决成功率快速上升.
Bug 生成策略
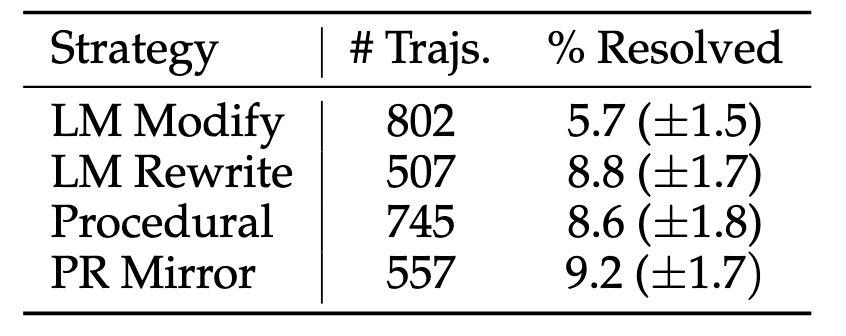
- 除了 LM Modify 效果较差外, 其余效果都还可以 (可能是 LM Modify 生成的错误还是太明显了).
Issue 生成策略
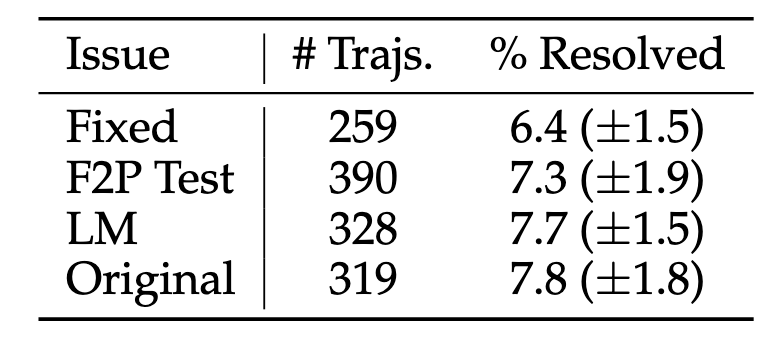
- 采用固定模板的效果最差.
失败分析
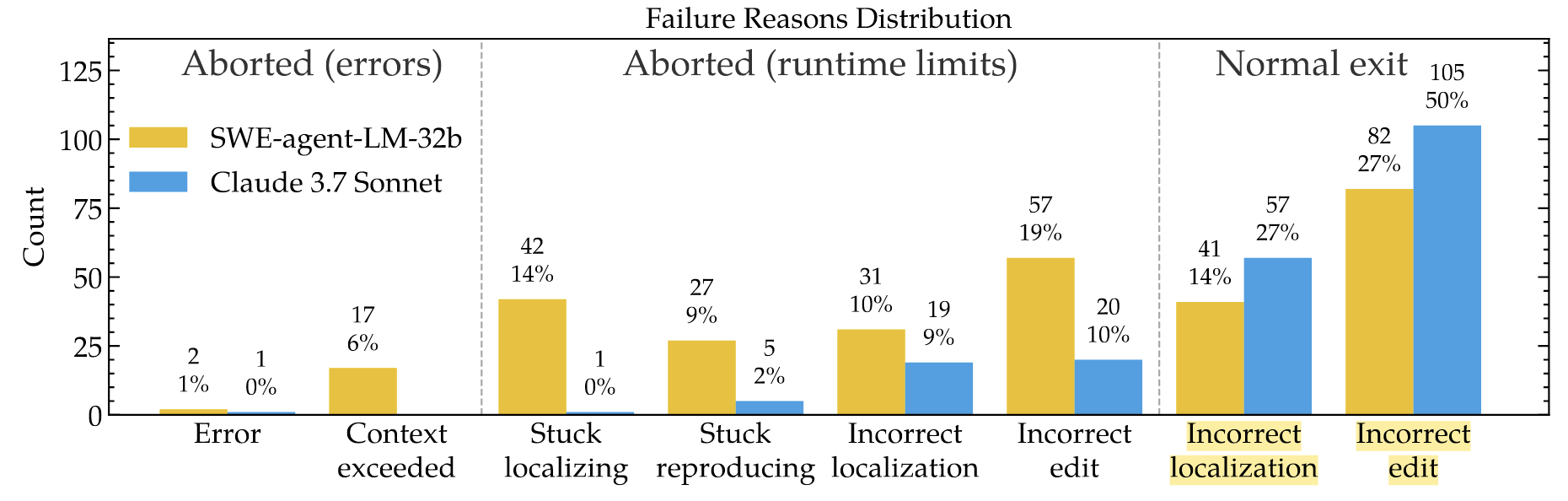
- 和 Claude 等顶尖模型不同, 通过 SWE-Smith 训练的模型容易在推理阶段陷入反复执行某个 Action 的循环, 导致过度消耗 tokens 造成异常退出.