Recommender Systems with Generative Retrieval
预备知识
- 请了解 RQ-VAE.
核心思想
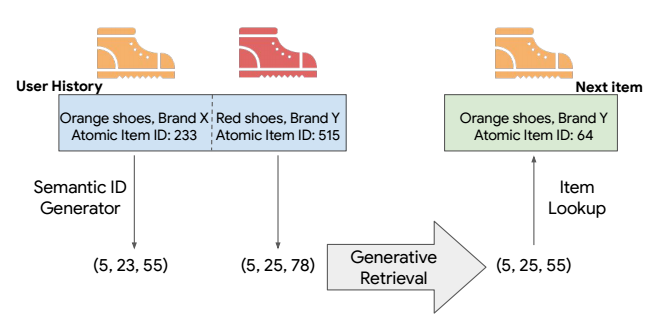
目前主流的推荐系统的一个痛点是将 item 表示为一个 embedding, 这就导致对于冷启动的场景并不友好 (既然我们没法再立即获得高效的新来的 item 的表示). 此外, 现阶段的推荐系统大多采用 matching 的架构 (在 item 数量较多的时候可能会慢一些), 本文探索一种生成式的检索方式.
本文所提出的 Tiger 依然 RQ-VAE, 对 item 的文本 embedding 首先进行编码, 得到的编码作为 item 的 ‘ID’, 后面的模型只需要在此基础上进行预测即可.
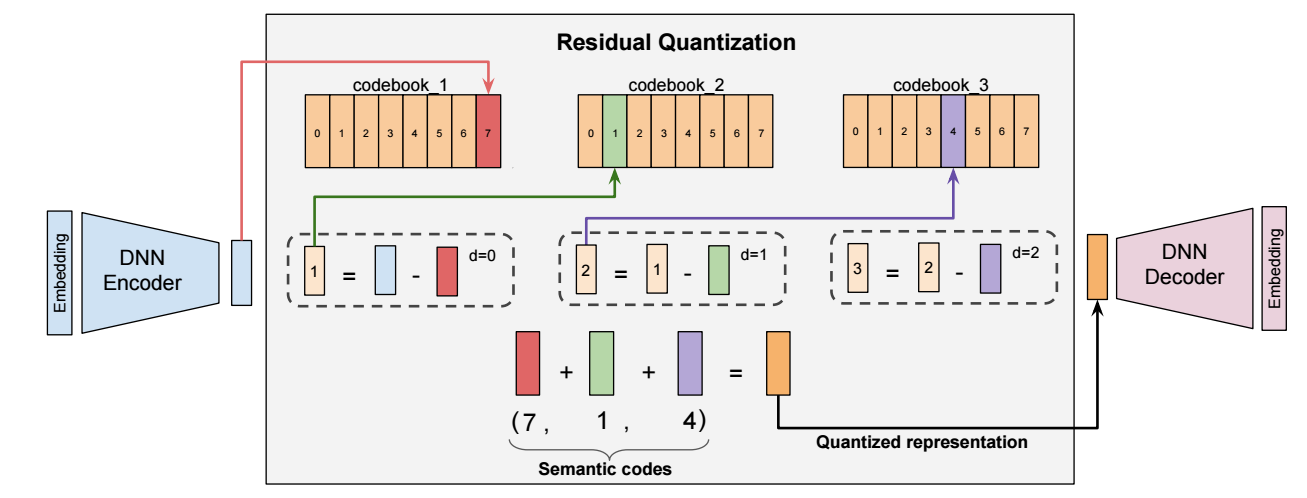
如上图所示, 文本的 embedding 经过 RQ-VAE (codebook 不共享) 得到 semantic codes. 比如 codebook 的size 为 8, 则理论上可以表示 $8^K$ 个 items (这里 $K$ 表示残差量化的次数).
在第一阶段训练完毕之后, 我们就可以用得到的编码作为每个 item 的 ‘ID’, 然后就可以训练一个模型来进行生成式推荐, 这里文中给了一个例子:
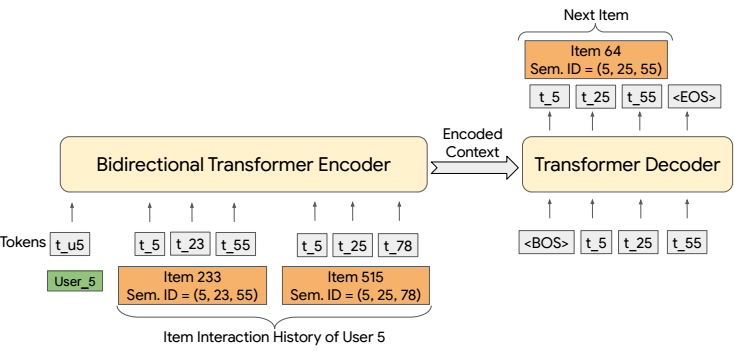
- 对于一个新来的 item, 只需要 -> Tiger 编码 -> 就可以用于预测了.
注: 这里省略了避免 ID 碰撞的细节.
个人测试
- Semantic embedding 处理流程:
# %%
import pandas as pd
import torch
import numpy as np
import os
import pickle
from tqdm import tqdm
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
from sentence_transformers import SentenceTransformer
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
# %%
item_df = pd.read_csv('../data/Processed/Amazon2014Beauty_550_LOU/item.txt', sep='\t')
fields = ('TITLE', 'CATEGORIES', 'BRAND')
# fields = ('TITLE',)
for field in fields:
item_df[field] = item_df[field].fillna('')
item_df['TEXT'] = item_df.apply(
lambda row: "\n".join([f"{field}: {row[field]}." for field in fields]),
axis=1
)
print(item_df['TEXT'].head(5))
# %%
def export_pickle(data, file: str):
r"""
Export data into pickle format.
data: Any
file: str
The file (path/filename) to be saved
"""
fh = None
try:
fh = open(file, "wb")
pickle.dump(data, fh, pickle.HIGHEST_PROTOCOL)
except (EnvironmentError, pickle.PicklingError) as err:
ExportError_ = type("ExportError", (Exception,), dict())
raise ExportError_(f"Export Error: {err}")
finally:
if fh is not None:
fh.close()
def encode_by_llama(
item_df: pd.DataFrame,
model_dir: str = "./models",
model: str = "Llama-2-7b-hf",
batch_size: int = 32
):
saved_filename = f"{model}_{'_'.join(fields)}.pkl".lower()
model_path = os.path.join(model_dir, model)
tokenizer = AutoTokenizer.from_pretrained(model_path, device_map = 'cuda')
model = AutoModelForCausalLM.from_pretrained(model_path, device_map = 'cuda')
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.eos_token
for i in tqdm(range(0, len(item_df), batch_size)):
# print(i)
item_names = item_df['TEXT'][i:i+batch_size]
# 生成输出
inputs = tokenizer(item_names.tolist(), return_tensors="pt", padding=True, truncation=True, max_length=128).to(model.device)
with torch.no_grad():
output = model(**inputs, output_hidden_states=True)
seq_embeds = output.hidden_states[-1][:, -1, :].detach().cpu().numpy()
# break
if i == 0:
tFeats = seq_embeds
else:
tFeats = np.concatenate((tFeats, seq_embeds), axis=0)
tFeats = torch.from_numpy(tFeats).float()
export_pickle(
tFeats,
saved_filename
)
return tFeats
def encode_textual_modality(
item_df: pd.DataFrame,
model: str = "all-MiniLM-L12-v2", model_dir: str = "./models",
batch_size: int = 128
):
saved_filename = f"{model}_{'_'.join(fields)}.pkl".lower()
sentences = item_df['TEXT']
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
encoder = SentenceTransformer(
os.path.join(model_dir, model),
device=device
).eval()
with torch.no_grad():
tFeats = encoder.encode(
sentences,
convert_to_tensor=True,
batch_size=batch_size, show_progress_bar=True
).cpu()
assert tFeats.size(0) == len(item_df), f"Unknown errors happen ..."
export_pickle(
tFeats,
saved_filename
)
return tFeats
# %%
encode_by_llama(item_df)
encode_textual_modality(item_df)
SASRec
Blocks
- Blocks: 有着非常重要的意义, 只有当 Blocks 足够大的时候, Invalid Beams 的数目才能被控制住.
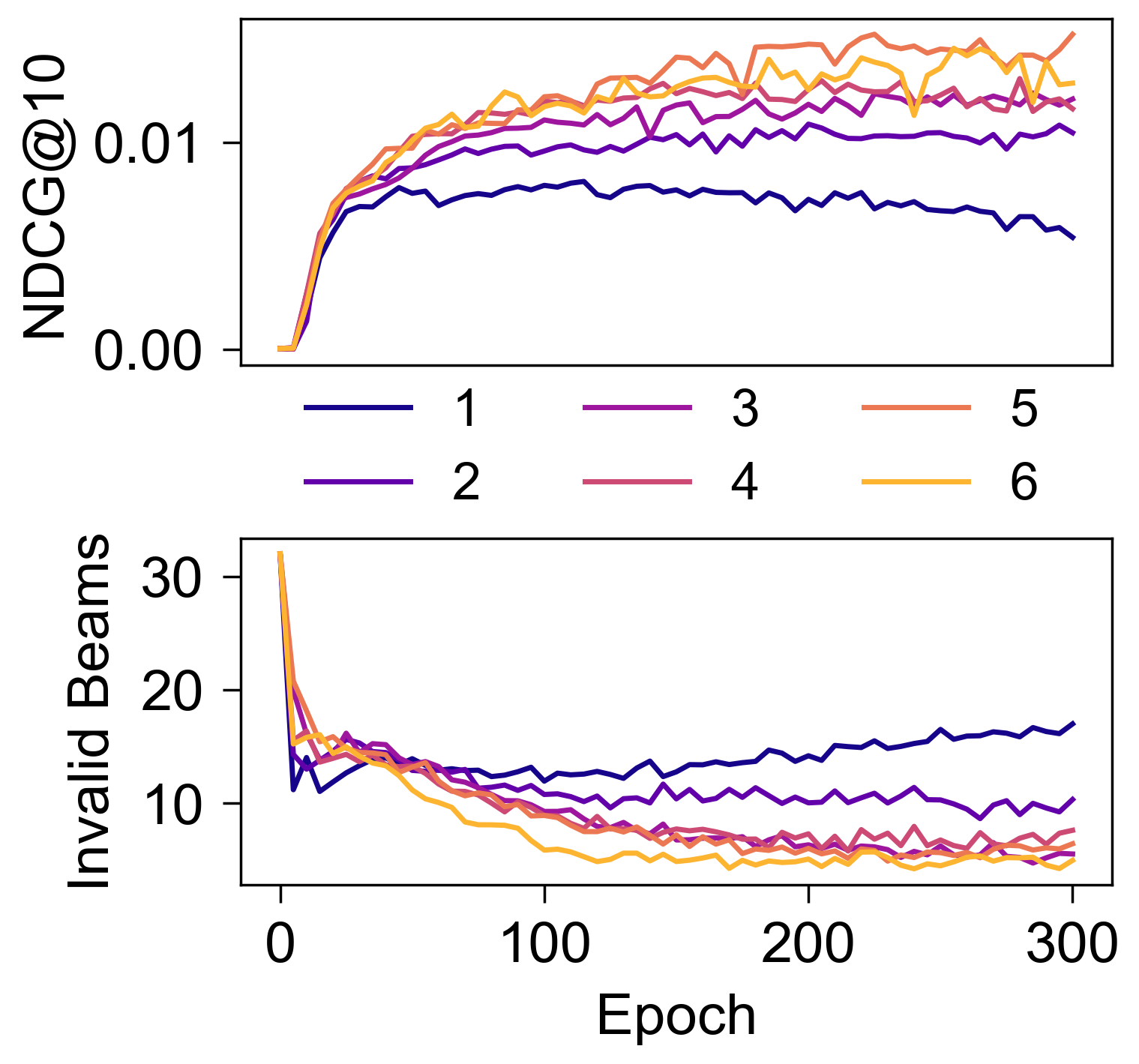
- 这个图是在
Amazon2014Beauty_1000_LOU上测的, 不过在Amazon2014Beauty_550_LOU上也能观察到类似的结果.
Quantization
- 下面是不同 Quantization 在
Amazon2014Beauty_1000_LOU数据集上的表现, KMeans 的效果要好太多.
| HR@1 | HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
|---|---|---|---|---|---|
| Random | 0.0025 | 0.0080 | 0.0114 | 0.0052 | 0.0063 |
| KMeans (random; iters=10) | 0.0039 | 0.0146 | 0.0233 | 0.0092 | 0.0120 |
| KMeans (random; iters=100) | 0.0038 | 0.0154 | 0.0246 | 0.0096 | 0.0126 |
| KMeans (points; iters=10) | 0.0032 | 0.0119 | 0.0219 | 0.0074 | 0.0107 |
| KMeans (points; iters=100) | 0.0043 | 0.0144 | 0.0239 | 0.0092 | 0.0123 |
| STE | 0.0023 | 0.0111 | 0.0188 | 0.0067 | 0.0091 |
| Rotation-trick | 0.0041 | 0.0122 | 0.0195 | 0.0083 | 0.0106 |
| Rotation-trick w/o KMeans init | 0.0025 | 0.0105 | 0.0178 | 0.0064 | 0.0087 |
| SimVQ | 0.0029 | 0.0092 | 0.0164 | 0.0060 | 0.0083 |
- 在
Amazon2014Beauty_550_LOU上, 观察到了类似的结果, 不过和上面的不同是. 在Amazon2014Beauty_1000_LOU上不论是何种量化方法, 基本上都存在不可忽略的 ID 冲突 (虽然只要 Blocks 足够, 模型是可以通过额外添加一个 Token 来区分的). 但是在Amazon2014Beauty_550_LOU中, 虽然 Rotation-trick/STE 这些的冲突基本上只有 30 左右, 但是效果依旧比不上 Kmeans (它足足有 3472 个 Item 产生冲突). 注意, KMeans 比普通的 quantization 方法好, 不是因为额外的 Tokens 多 (实际上第四个位置只有 20 个不同的 Tokens, 即最多有 20 个 Item 被映射到同一个 ID). 我觉得这反而说了普通的 VQ-VAE 实际上没有学到什么东西.
Commit Weight
- 在
Amazon2014Beauty_550_LOU上的测试结果:
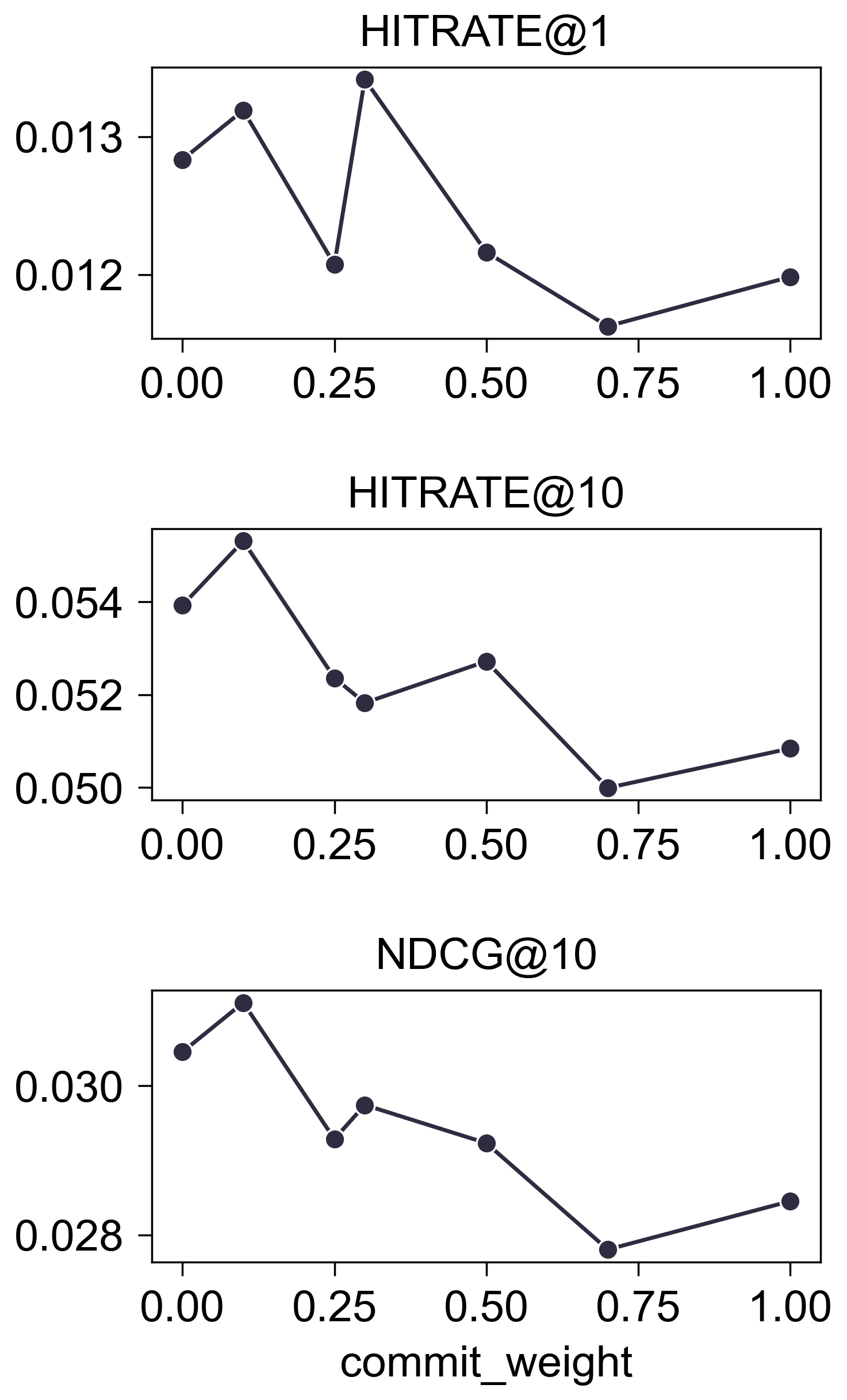
- (结论) 影响不大.
PPL -> Performance
- 个人观察到, KMeans 的 PPL 挺高, 那么会不会这是个合理的性能指标呢?
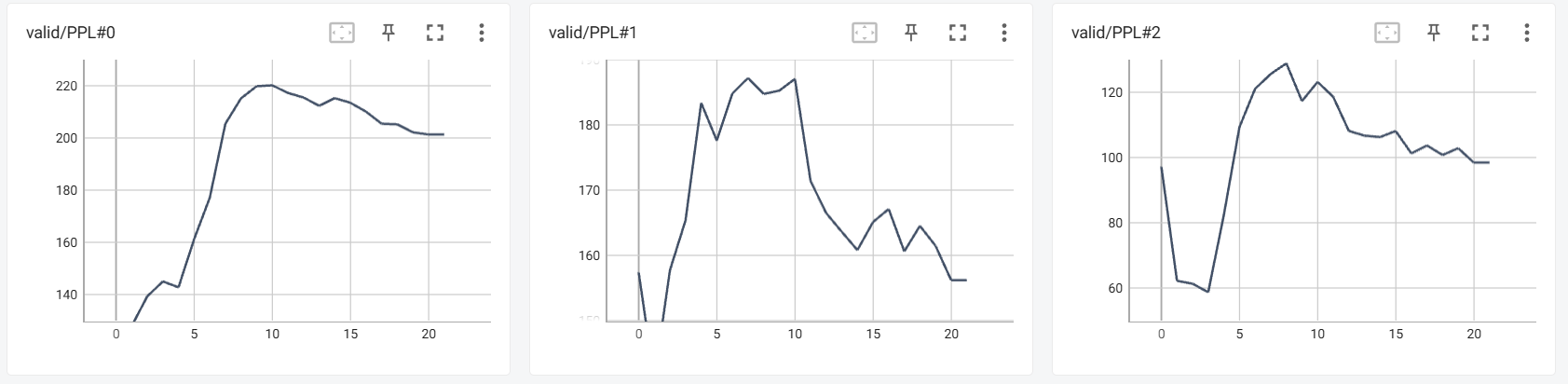
- 确实在 Epoch=25-30 的地方有一个小高峰 (PPL 的图横坐标需要 x 5), 但是后续还能涨回来?
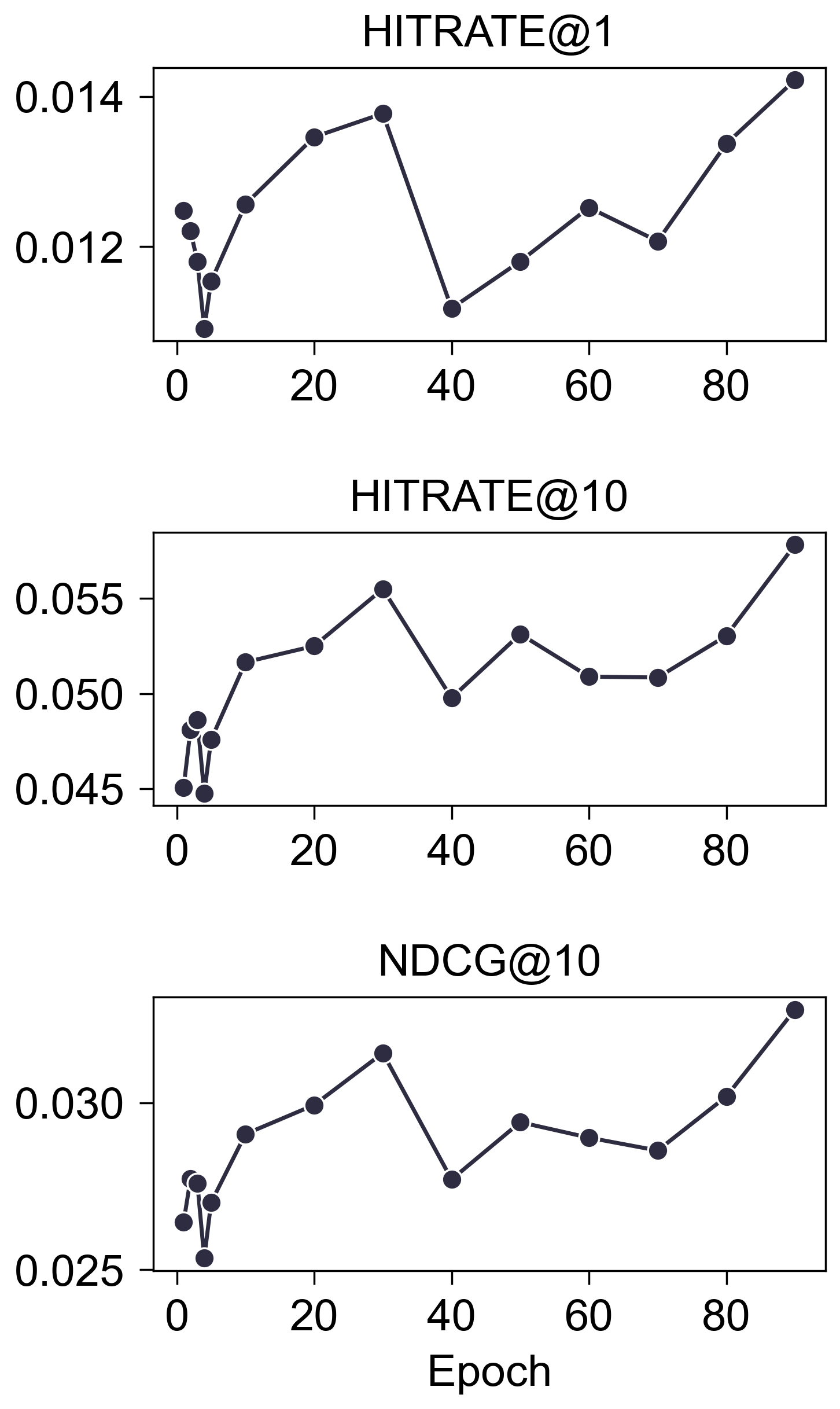
Epochs
- (Valid)
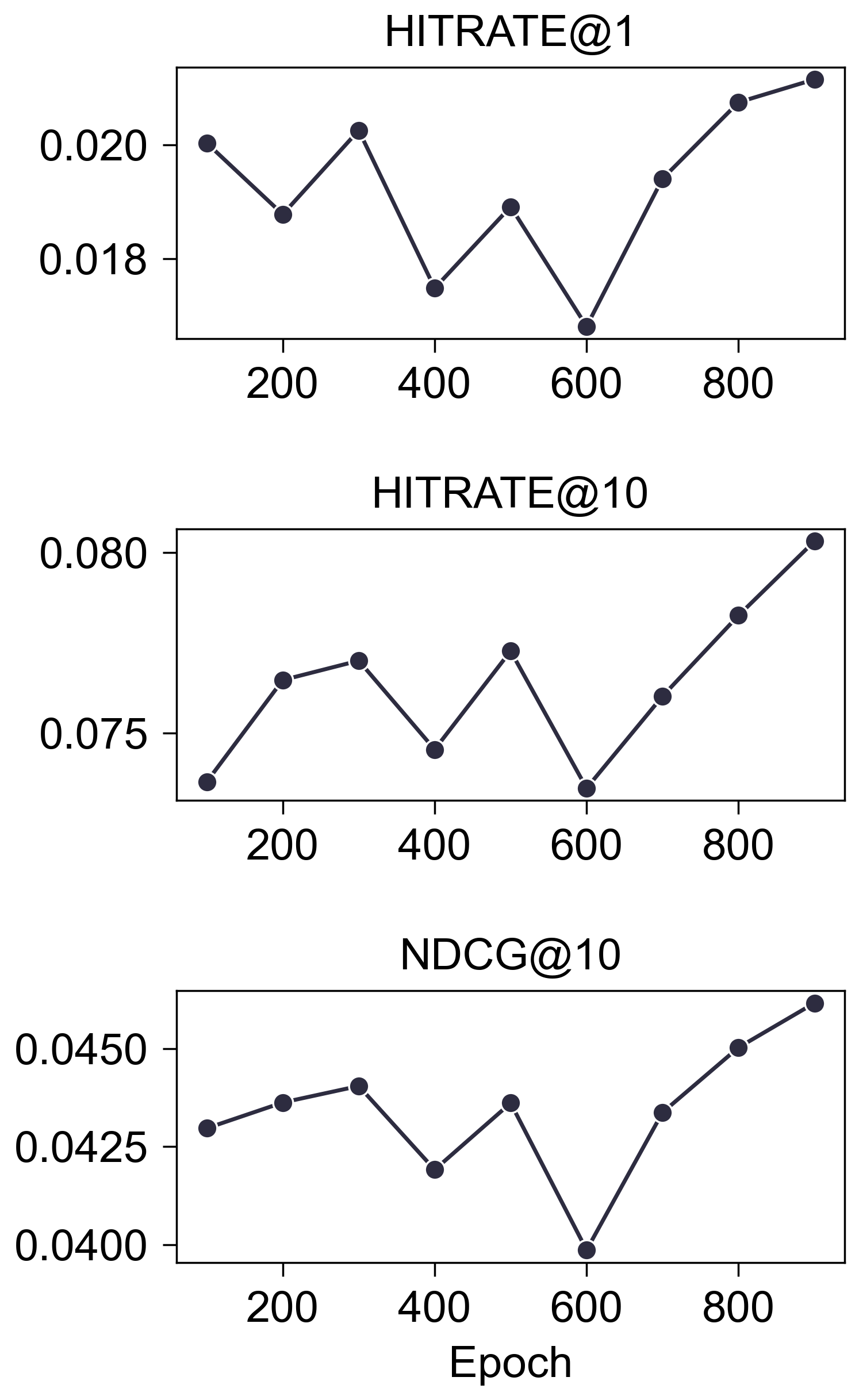
- (Test)
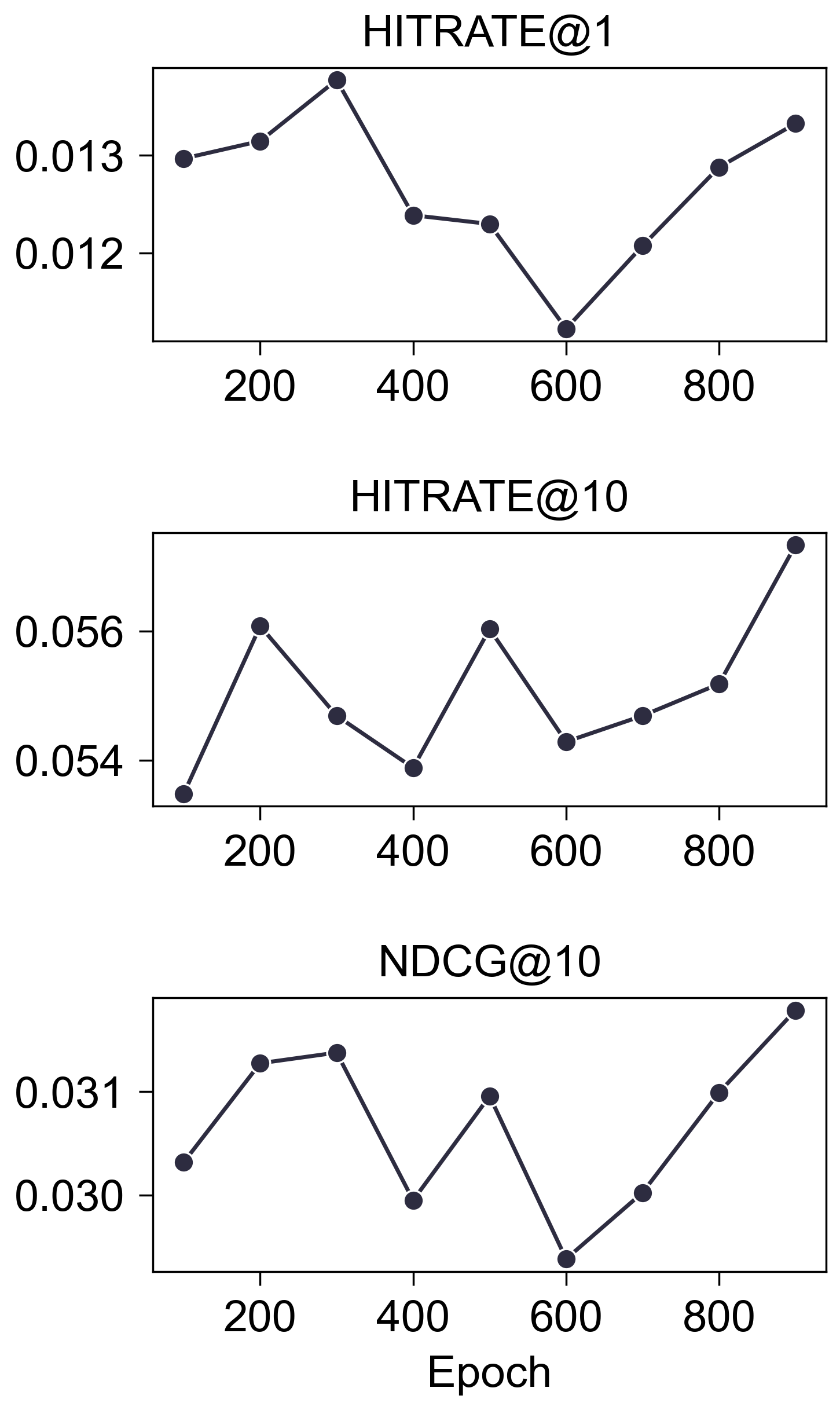
- 从验证集看, 训练更长的时间是明显有用的, 但是这体现在测试集上的优势过于微弱了, 需要进一步验证.