TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
预备知识
- 请务必了解 VQGAN.
核心思想
本文试图将 Image 编码为离散 Token 以方便直接通过 LLM 实现 Image 的理解和生成任务.
作者将研究重心放在 Vector Quantization 之上, 认为之前的方法通常只采用一个单独的 Vector Quantization, 这会导致对应的编码要么过于偏向语义 Embedding 要么过于偏向 pixel-to-pixel 这种强调 low-level 特征的.
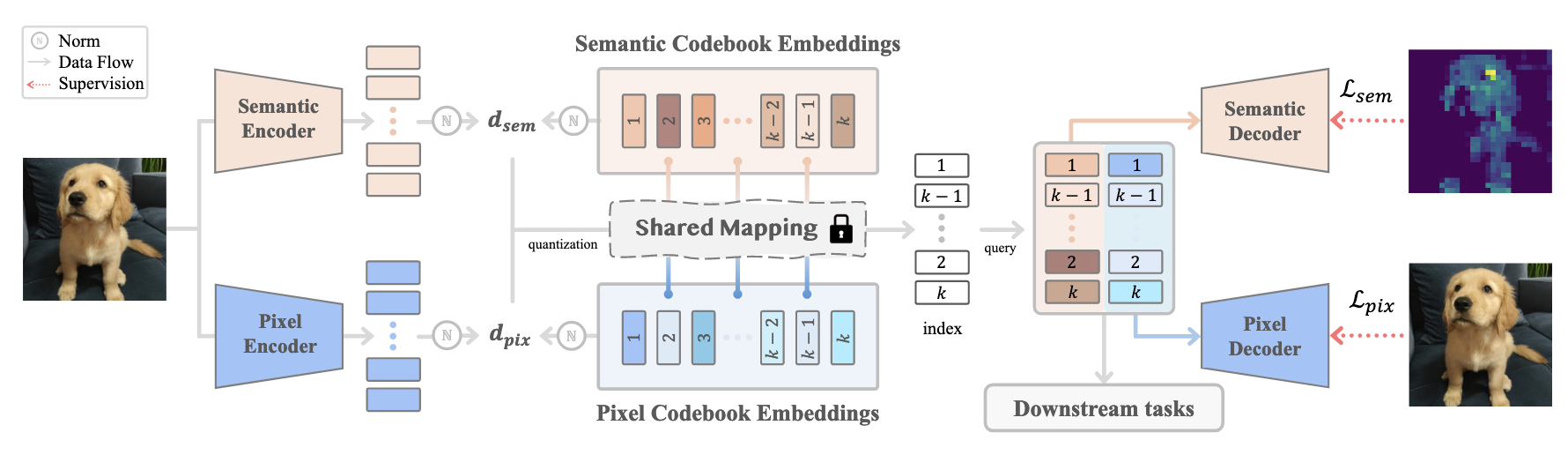
因此, TokenFlow 希望设计一个 dual-encoder 来实现二者的兼容:
如上图所示, TokenFlow 具备两个分支: Semantic/Pixel.
但是二者并非完全独立, 中间有一个 shared mapping. 需要注意的是, 这里指得不是共享的 Codebook. 对于, Semantic/Pixel 各自有其 CodeBook $\mathbf{Z}_{sem} = \{z_{sem, i}\}_{i=1}^K, \mathbf{Z}_{pix} = \{z_{pix, i}\}_{i=1}^K$. 然后量化的过程是耦合的:
$$ d_{sem, i} = \|\hat{z}_{sem} - z_{sem, i}\|, \quad i=1,2,\ldots, K, \\ d_{pix, i} = \|\hat{z}_{pix} - z_{pix, i}\|, \quad i=1,2,\ldots, K, \\ i^* = \text{argmin}_{i} (d_{sem, i} + w_{dis} \cdot d_{pix, i}). $$
实际上就是通过一个额外的权重来调节两部分的重要性. 如果 $w_{dis} = 1$, 实际上就可以看出是 shared codebook (而且作者给的代码中就是就是设定的 $w_{dis} = 1$).
最后, Semantic 和 Pixel 两个分支的训练目标略有不同. Semantic 采用的分支就是用重构损失训练, 而 Pixel 部分的分支采用 VQGAN 的方式训练, 最后再加上 VQ-VAE 中所建议的 commit loss.