Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
预备知识
- $\mathcal{U}$, user set;
- $\mathcal{V}$, item set;
- $s_{u} = [v_1, \ldots, v_j, \ldots, v_{|s_u|}]$, 用户 $u$ 的交互序列;
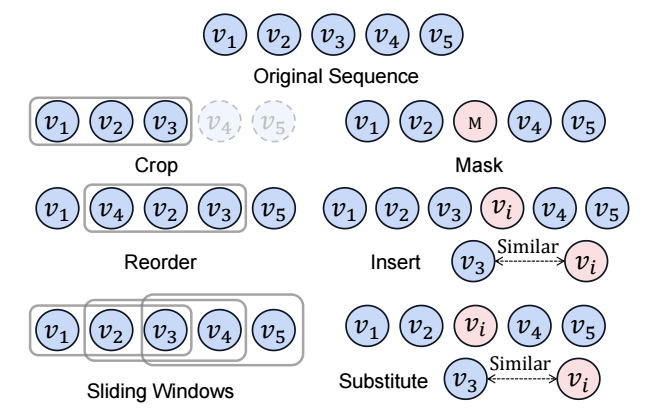
- 在序列推荐中有如下常见的数据增强:
- Crop: 从 $s_u$ 中截取一段连续的子序列;
- Reorder: 将 $s_u$ 中某一段子序列打乱;
- Sliding Windows: 将序列 $s_u$ 通过滑动窗口得到长度为 $T$ 的多个子序列;
- Mask: 随机序列 $s_u$ 中的部分 item mask 掉 (一般是替换为某个 mask token);
- Substitute: 将 $s_u$ 中的部分 items 替换为相似的 item (相似一般是根据向量表示相似度度量);
- Insert: 在 $s_u$ 中添加部分 items.
核心思想
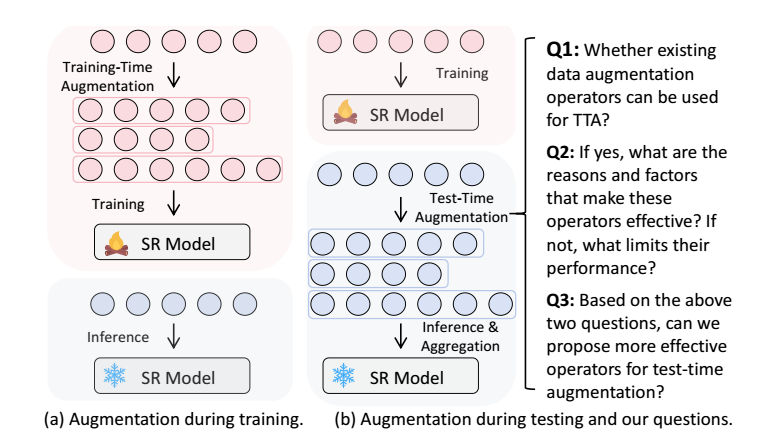
Test-Time Augmentation (TTA) 是希望在测试阶段中将数据增强应用于 $s_u$, 从而得到 $m$ 个相似的序列 $\tilde{s}_i, i=1,2, \ldots, m$, 然后最后的 score 是这些序列的 score 的平均:
$$ AverageAgg (\sum_{i=1}^m Model (\tilde{s}_i)). $$
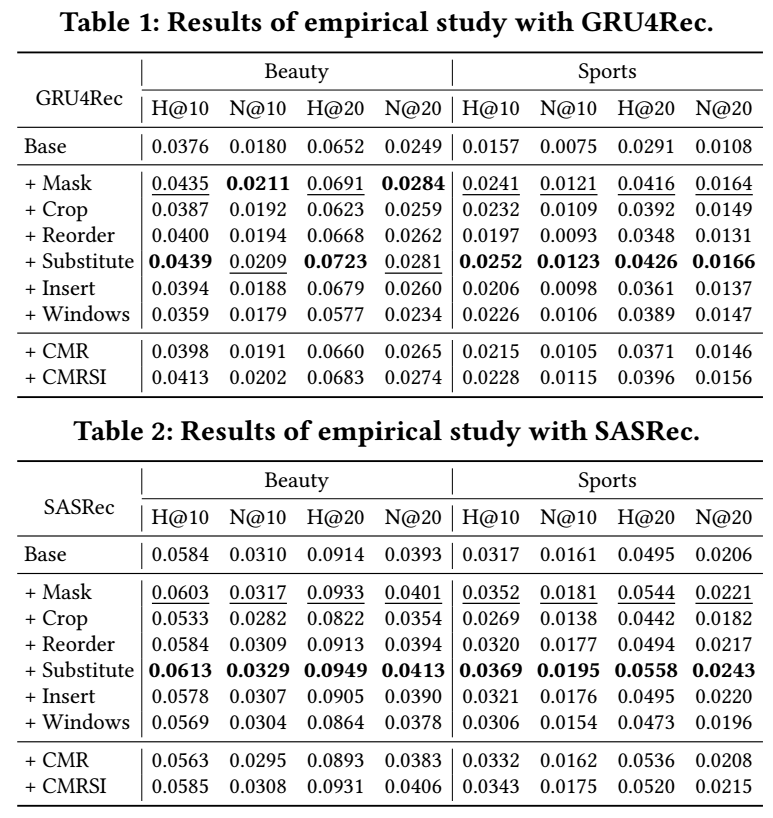
- 作者发现, 不同的数据增强, 最为有效的是
Mask和Substitute:
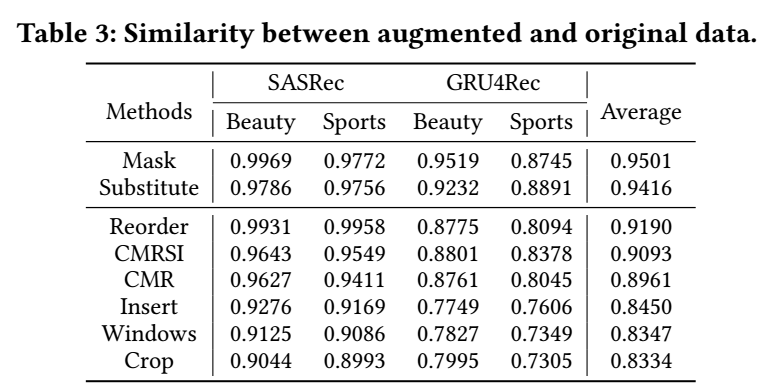
- 一个问题是, 为什么这两个相对来说比较简单的策略会比其它数据增强更有效呢? 作者假设是因为这两个方法很好地平衡了原本用户的行为模式和多样化. 通过下表可以发现, 数据增强前后相似度改变差异过大 (如 Crop) 或者过小 (如 Reorder) 均不能带来性能上的提升.
- 据此, 作者还提出了 TNoise 数据增强, 直接在序列的 item embedding 上添加微量的均匀噪声.