UniCode$^2$: Cascaded Large-scale Codebooks for Unified Multimodal Understanding and Generation
预备知识
- 请务必了解 VQGAN.
核心思想
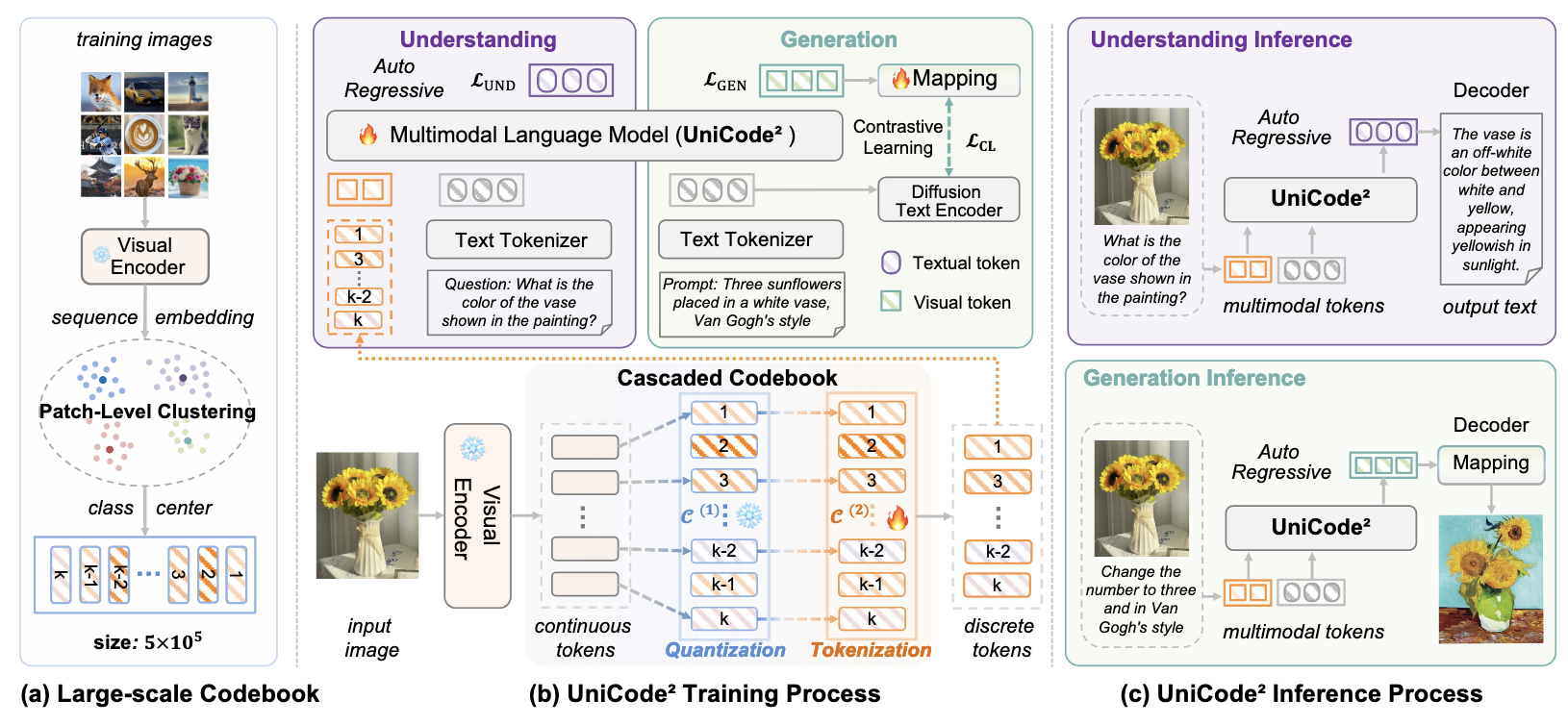
- UniCode$^2$ 介绍了一套非常自然的图片 -> Codeword -> 通过 LLM 预测下一 Codeword -> 最后通过一般生成模型 (e.g., Diffusion) 条件生成图片的流程.
对于图片 $\mathcal{D} = \{I_i\}_{i=1}^N$, 首先通过预训练好的 Encoder (e.g., SigLIP) 得到 patch-level 的 embeddings, 这些 embeddings 通过 K-means 计算得到 $K=500,000$ 个类别中心, 记为
$$ \mathcal{C} = \{\bm{c}_k\}_{k=1}^K \subset \mathbb{R}^{d}. $$对于任一图片 ($I$), 通过 Image Encoder 得到它的 patch-level 的 embeddings:
$$ [\bm{z}_1, \bm{z}_2, \ldots \bm{z}_T] \subset \mathbb{R}^d. $$通过最近邻可以得到 $I$ 的一组离散表示:
$$ [v_1, v_2, \ldots, v_T], \\ v_i = \text{argmin}_{k} \| \bm{z}_i - \bm{c}_k \|_2. $$$[v_1, \ldots, v_K]$ 作为 LLM 的词表的扩展 (以 $\mathcal{C}$ 为 Embedding 初始化), 再加上一个 projector, 即可将 Image 的 codeword 和 Text 描述一起作为 LLM 的输入.
通过一些 MLLM 的理解任务可以直接训练上述的额外的词表.
如果想要进行生成任务, 可以让 LLM 作为下一个 patch 对应的 codeword 的生成器, 得到下一个 codeword 后, 作为条件输入到传统的 Decoder 中进行图像生成.