Unified Semantic and ID Representation Learning for Deep Recommenders
预备知识
- 请了解 TIGER.
核心思想
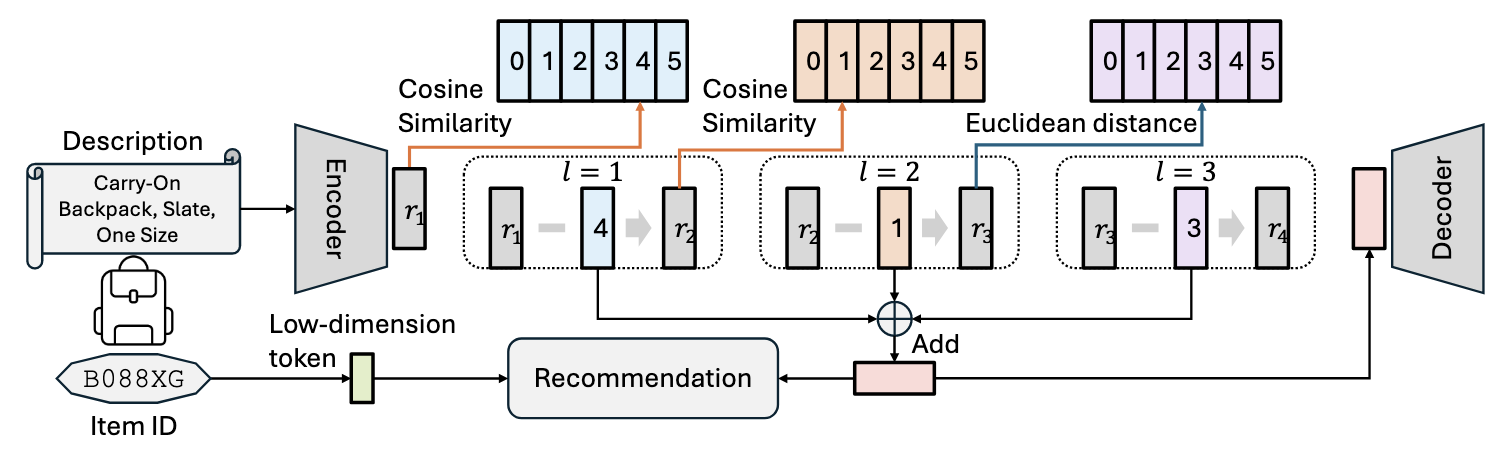
(Motivation) 生成式推荐虽然能够大大降低 Embedding Size, 但是不可避免地部分 Items 会有 ID 冲突的问题, 因此本文希望将 ID Embedding 和 RQ-VAE 过程中的共享的 semantic Embedding 综合起来. 作者认为, 前者是 Item 的独有的一些特征, 因此只需要一小部分维度表示即可, 而后者是表达一些共有的特性.
(Unified Semantic and ID Tokenization) 对于 item $i$, 我们有 1. ID embedding $\bm{e}_{i} \in \mathbb{R}^{D_1}$; 2. RQ-VAE 中用于重构的向量 $\bm{z}_i \in \mathbb{R}^{D_2}$, 则最终的 Item 表示为:
$$ \bm{s}_i = [\bm{e}_i \| \bm{z}_i] = \mathbb{R}^{D_1 + D_2}. $$
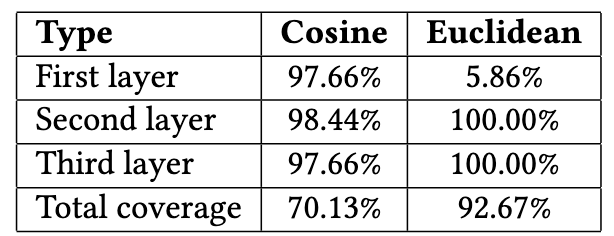
(Unified Distance Function) 通常来说, RQ-VAE 的量化是采用欧氏距离计算的, 但是作者发现 (如上表所示):
Euclidean 在第一个 codebook 出显示出极差的 codeword 利用率, 仅 5.86% 的 codewords 是存在附属 Item 的, 与之相比 Cosine 相似度的利用率就相当高;
Cosine 相似度虽然相较于 Euclidean 有更高的 Codebook 利用率, 但是它产生出来的 Item 的 semantic IDs 存在较为严重的 ID 冲突, 仅有 70.13% 的唯一 semantic IDs.
因此, 作者建议, 利用 RQ-VAE 进行量化的时候, 前几个 Codebook 均采用 cosine 相似度, 仅最后一个 codebook 采用欧式距离.
(End-to-end Joint Optimization) 为了更好的优化, 不同于 TIGER 的二阶段的训练方式, 作者采用一个 End-to-end 的联合训练: 即 RQ-VAE 和 Recommender 一起训练.