UniSearch: Rethinking Search System with a Unified Generative Architecture
预备知识
(生成式检索) 生成式检索和生成式推荐类似, 其主要特点是将 Video 编码成 Semantic IDs (SIDs), 然后训练目标就是预测 Video 的 SIDs.
(两阶段) 通常来说, 生成式的方法都会分成两个阶段: 1. 通过 RQ-VAE 或 VQ-VAE 等生成 SIDs (也可以通过 RQ-KMeans 这种不需要训练的方式); 2. 基于预先得到的 SIDs 作为词表, 用于后面的序列模型. 快手的 One Team 倾向于用 Encoder-Decoder 的架构作为预测器.
(End-to-End) 显然, 两阶段的方式存在一些弊端. 通常来说, 生成 SIDs 的过程仅仅依赖 Video 的语义信息, 然后这不可避免地引入一些不必要的噪声, 以及和真实的目标存在一些 GAP. 这一点在推荐中其实尤为明显, 因为推荐任务非常强调协同信息.
核心思想
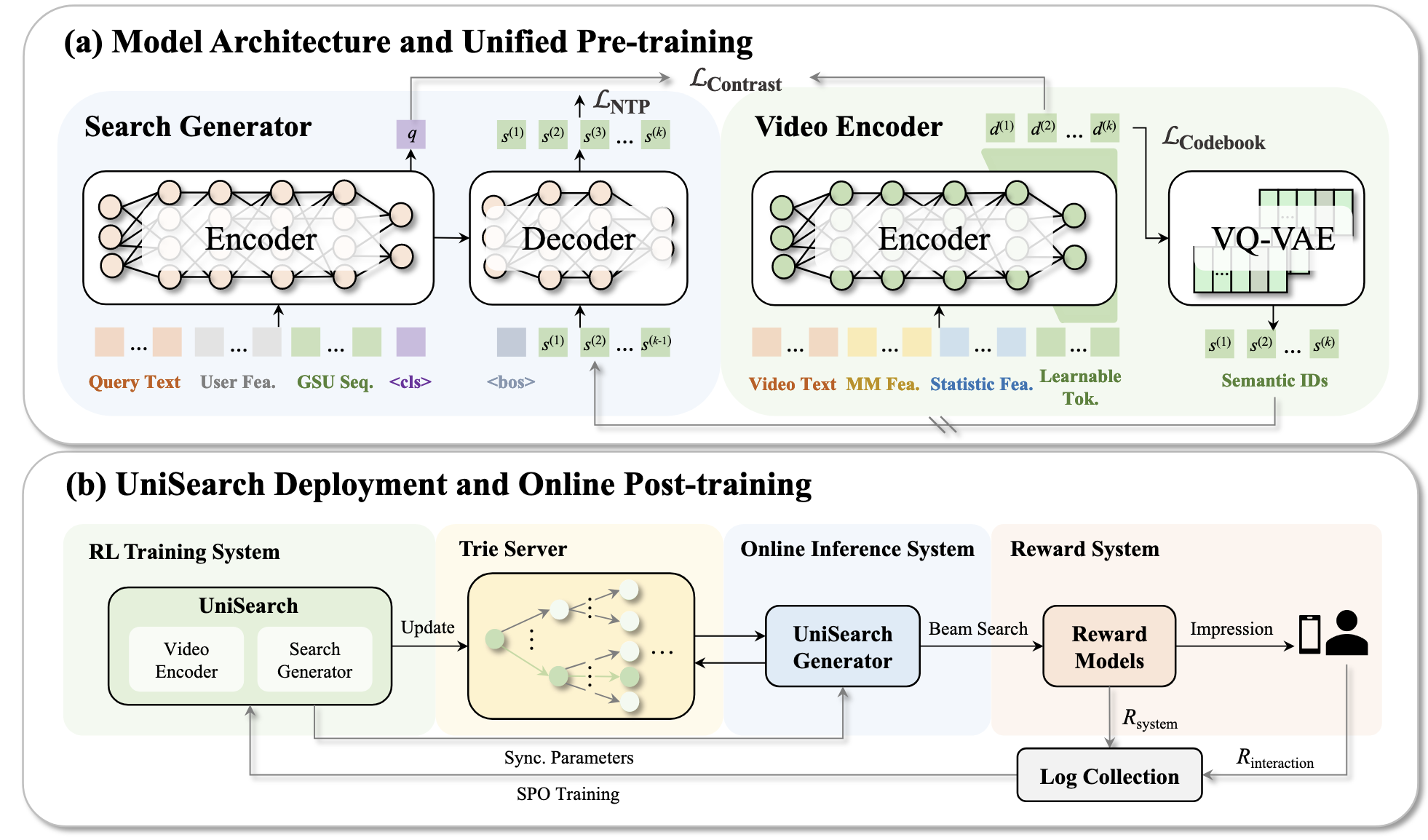
(Video Encoder)
- 这部分以 Video 的多模态/统计特征为输入, 然后通过 Learnable Tokens 凝练先前的特征, 得到 $d^{(1)}, d^{(2)}, \ldots, d^{(k)} \in \mathbb{R}^{p}$.
- 接着, 这些凝练后的表示通过 VQ-VAE 离散编码得到 Semantic IDs $s^{(1)}, s^{(2)}, \ldots, s^{(k)}$. 特别地, VQ-VAE 应用了 SimVQ 策略
(Search Generator)
- Encoder: 这部分以 query 和用户的一些历史搜索记录为输入, 通过一个可学习的 [cls] token 凝练 query 表示 $q \in \mathbb{R}^p$.
- Decoder: 这部分以 Encoder 的 hidden states 为 cross-attention 的 key/val, 以及 Item 的 SIDs 为输入, 通过 Next-Token Prediction 的方式进行训练和预测.
(Alignment) UniSearch 要求 video 的表示 $d^{(1)}, d^{(2)}, \ldots, d^{(k)}$ 和 $q$ 对齐:
$$ \mathcal{L}_{contrast} = \sum_{n=1}^k \mathcal{L}( q_i, \text{sg}[\sum_{m < n} d_i^{(m)}] + d_i^{(n)} ), \\ \mathcal{L}(q, d) = -\log \frac{ \exp(\text{sim}(q, d) / \tau) }{ \exp(\text{sim}(q, d) / \tau) + \sum_{d^- \in \mathcal{N}}\exp(\text{sim}(q, d^-) / \tau) }. $$这里 $\text{sg}[\cdot]$ 表示 stop-gradient, $\text{sim}(q, d) = 1 - \|q - d\|_2^2$. 特别地, 作者希望 $d^{(1)} \longrightarrow d^{(k)}$ 满足一个先捕捉粗粒度的信息, 然后再捕捉细粒度信息的过程, 因此对于负样本集合 $\mathcal{N}$, $d^{(1)}$ 仅是 in-batch sampling, 而之后逐步增加更难的负样本.
因此, 本文有三个训练目标: Next-Token Prediction Loss; Contrastive Loss; 以及 VQ-VAE 的 codebook commitment loss.
在推理阶段, UniSearch 采取前缀树 (Trie) 来保证生成的有效性.
总的来说, 作者并没有为 End-to-End 训练设计什么特别的框架, 个人怀疑训练过程是否能够稳定.